Hi zusammen, ich bin gerade dabei ein Programm in mehrere Dateien aufzuteilen. main.c config.h peripherie1.c peripherie1.h peripherie2.c peripherie2.h Es wird vor der Kompilierung entschieden, welche Peripherie ich einbinde, entweder 1 oder 2. Ich möchte nicht viele verschiedene Funktionsauffrufe verwenden. Daher soll eine Funktion aufgerufen werden, deren Definition immer gleich ist, die Deklaration sich jedoch unterscheidet. Eine Funktion mit einer Definition und einer Deklaration in verschiedenen Dateien zu verwenden habe ich mittlerweile hinbekommen. Ist das in C überhaupt möglich? Irgendwelche Tips oder wo kann ich das am besten nachlesen?
Tuck I. schrieb: > Es wird vor der Kompilierung entschieden, welche Peripherie ich > einbinde, entweder 1 oder 2. einbinden heisst: die Funktion aufrufen? Oder die Datei mit Kompilieren und Linken zu lassen? > Ich möchte nicht viele verschiedene Funktionsauffrufe verwenden. > Daher soll eine Funktion aufgerufen werden, deren Definition immer > gleich ist, die Deklaration sich jedoch unterscheidet. Was meinst Du mit Definition und Deklaration? Zumal du "extern" in den Betreff geschrieben hast. Bei Variablen ist "extern int foo;" die Deklaration, "int foo;" die Definition. Bei Funktionen ist kein "extern" notwendig. Trotzdem muss die Signatur (z.B. "int foofunc(void);" natürlich bei der Deklaration gleich sein. > Eine Funktion mit einer Definition und einer Deklaration in > verschiedenen Dateien zu verwenden habe ich mittlerweile hinbekommen. Also "void foofunc(void);" in die Header-Datei, "void foofunc(void) { ...}" in die C-Datei? Mache bitte ein Beispiel, was unterschiedlich sein soll. Wenn Du in beiden C-Dateien foofunc definierst, dann darfst Du nur eine Datei compilieren/linken. Wenn Du Funktionspointer beherrscht, gibt es elegante Wege, 2 Implementierungen zu haben und beide gleich zu nutzen.
bedingte Kompilierung? Siehe #if defined(VARIANTE_A) ... #else #if definded(VARIANTE_B)... #endif Die Variante dann beim kompilieren als define mitgeben oder in einer header Datei definieren.
Da die Funktions-Deklaration in der x.h Datei ist, braucht du nur eine Header-Datei, wenn der Aufruf (-> Name & die Parameter) gleich sind. Da die Definition in den .c-Dateien ist, brauchst du nur diese .c-Dateien auszutauschen, um andere Funktionalität zu erreichen. Dies ist natürlich statisch und wird zur Compilezeit festgelegt. Wenn es dynamisch sein muss, musst du unterschiedliche Namen für die Deklaration & Definition verwenden und mit Funktionspointern arbeiten. Aber mein Bauchgefühl sagt mir, dass womöglich dein grundlegender Ansatz nicht optimal ist und man das anders besser lösen kann. Was willst du machen und warum?
Tuck I. schrieb: > Ist das in C überhaupt möglich? > Irgendwelche Tips oder wo kann ich das am besten nachlesen? Ja, das ist möglich und in C auch nicht unüblich. Du must die Unterscheidung halt zur Link-Zeit machen: Wenn Du peripheral_1 verwenden willst, dann linkst Du main.o und peripherie1.o zusammen. Wenn es peripheral_2 sein soll, dann eben main.o und peripherie2.o. Eigentlich bräuchtest Du auch keine 2 header, wenn die Deklaration beider Funktions-Sätze identisch sein soll. Implementierung-Details würde ich in C-Dateien verschieben. mfg Torsten
Danke schonmal für die Antworten. Im falschen Subforum und trotzdem so viele Antworten :) Ich erkläre vielleicht nochmal ein bisl was: A. S. schrieb: > einbinden heisst: die Funktion aufrufen? Oder die Datei mit Kompilieren > und Linken zu lassen? Die Datei beim Kompilieren mit #ifdef entsprechend auswählen. > Was meinst Du mit Definition und Deklaration? Zumal du "extern" in den > Betreff geschrieben hast. Definition: void tuWas(uint8_t data1); Deklaration: void tuWas(uint_8 data1){ .... } Titel etwas unglücklich gewählt... > Also "void foofunc(void);" in die Header-Datei, "void foofunc(void) { > ...}" in die C-Datei? Genau, das ist eigentlich nicht schwierig :-) Ein Problem hatte ich zuvor mit structs die in den Funktionen anderer Dateien aufgerufe werden sollen. Das ging dann mit extern. > Mache bitte ein Beispiel, was unterschiedlich sein soll. Bsp zwei Hardwaremodule mit unterschiedlicher Anzahl 7 Segment Digits. Die Aufbereitung der Ausgabe unterscheidet sich dann. > Wenn Du in beiden C-Dateien foofunc definierst, dann darfst Du nur eine > Datei compilieren/linken. Eigentlich dachte ich, dass genau das mit #ifdef erledigt wird Bsp: #if PERIPHERIE == PERIPHERIE1 #include "peripherie1.h" #elif PERIPHERIE == PERIPHERIE2 #include "peripherie2.h" #endif Oder macht plattformio da irgendwelche krummen Dinge? Zumindest wird die nicht gesetzte Datei im Editor ausgegraut, also wird das "erkannt". Beim Kompilieren und Linken taucht im Status immer jede Datei auf, in der die Funktion deklariert wird. "multiple definition of" > Wenn Du Funktionspointer beherrscht, gibt es elegante Wege, 2 > Implementierungen zu haben und beide gleich zu nutzen. Leider noch nicht. und zu schrieb: > ...und warum nicht einfach mit #ifdef auseinanderhalten? Ich hatte zuvor eine riesige Datei mit sehr vielen #ifdef Aufrufen für unterschiedlich benannte Funktionen, die eigentlich das Gleiche gemacht hatten. Das wollte ich jezt aufdröseln. Elektrolurch schrieb: > Da die Funktions-Deklaration in der x.h Datei ist, braucht du nur > eine > Header-Datei, wenn der Aufruf (-> Name & die Parameter) gleich sind. > Da die Definition in den .c-Dateien ist, brauchst du nur diese > .c-Dateien auszutauschen, um andere Funktionalität zu erreichen. > Dies ist natürlich statisch und wird zur Compilezeit festgelegt. > Wenn es dynamisch sein muss, musst du unterschiedliche Namen für die > Deklaration & Definition verwenden und mit Funktionspointern arbeiten. > Aber mein Bauchgefühl sagt mir, dass womöglich dein grundlegender Ansatz > nicht optimal ist und man das anders besser lösen kann. > Was willst du machen und warum? Mir schwebt gerade ein Lösung vor. Ich verwende zum einen eine selbstgebastelte Bibliothek für eine Siebensegmentanzeige mit Shiftregistern, die ich eben auslagern wollte. Dazu eine fertige Bibliothek für ein anderes Modul mit mehr Segmenten und auch speziellem Chip zur Ansteuerung, die um die dubiose Funktion erweitert wird, um die Ausgabe auszubereiten. Meine Funktion zum Aufrufen ist bei beiden identisch, unterscheidet sich jedoch bei der genannten Aufbereitung. Möglicherweise wäre es ja besser diese eine Funktion im "Hauptprogramm" zu belassen und dann mit #ifdef zu unterscheiden, welch Aufbereitung am Zuge ist. Dann entfällt das ganze Gedöhns, das mir Sorgen macht und die beiden Bibliotheken bleiben unberührt. main.c config.h <- hier kommt die eine Funktion hinein peripherie1.c peripherie1.h peripherie2.c peripherie2.h <- unberührt Möglicherweise wollte ich das umständlich kompliziert machen.
Tuck I. schrieb: >> Was meinst Du mit Definition und Deklaration? Zumal du "extern" in den >> Betreff geschrieben hast. > Definition: void tuWas(uint8_t data1); > Deklaration: void tuWas(uint_8 data1){ > .... > } Genau andersherum. Eine Deklaration ist eine reine Information. Die Variable/Funktion mit diesen Namen gibt es und sie hat diesen Typ. Eine Definition verbraucht Speicher. Das ist Code oder eine Variable wird angelegt. In C/C++ impliziert eine Definition auch eine Deklaration. Deklaration: void tuWas(uint8_t data1); Definition: void tuWas(uint_8 data1){ .... } Deklaration: extern int foo; Definition: int foo;
:
Bearbeitet durch User
Sorry du hast recht, das kommt davon wenn man pennt. Da ist mir jetzt peinlich.
Tuck I. schrieb: > Eigentlich dachte ich, dass genau das mit #ifdef erledigt wird > Bsp: > #if PERIPHERIE == PERIPHERIE1 > #include "peripherie1.h" > #elif PERIPHERIE == PERIPHERIE2 > #include "peripherie2.h" > #endif > Oder macht plattformio da irgendwelche krummen Dinge? > Zumindest wird die nicht gesetzte Datei im Editor ausgegraut, also wird > das "erkannt". > Beim Kompilieren und Linken taucht im Status immer jede Datei auf, in > der die Funktion deklariert wird. "multiple definition of" Das entfernt oder inkludiert nur die Header-Datei (.h). Es bleiben jedoch beide C-Dateien im Projekt (und das soll auch so sein). Ein einfacher Hack ist, in peripherie1.h #define TuWas(a) TuWas1(a) zu schreiben und in peripherie2.h define TuWas(a) TuWas2(a) Und dann entsprechend TuWas1 und 2 in peripherie1.c und 2.c zu schreiben. Mit Funktionspointern läuft das ähnlich, nur typsicherer. #define-Gräber sind verlockend und verwirrend. Die zweite Möglichkeit: In der C-Datei eine ähnliche #define-Klammer über den ganzen Code. Beispiel für peripherie1.c, 2.c ist analog gegengesetzt:
1 | #if PERIPHERIE==PERIPHERIE1
|
2 | .....
|
3 | void TuWas(int data) |
4 | {
|
5 | ....
|
6 | }
|
7 | #else
|
8 | static int dummy; /* damit irgendwas drin ist, sonst meckert der Compiler evt. */ |
9 | #endif
|
A. S. schrieb: > Das entfernt oder inkludiert nur die Header-Datei (.h). Again what learned. > Mit Funktionspointern läuft das ähnlich, nur typsicherer. #define-Gräber > sind verlockend und verwirrend. Pointer werde ich als nächstes angehen. > Die zweite Möglichkeit: In der C-Datei eine ähnliche #define-Klammer > über den ganzen Code. Beispiel für peripherie1.c, 2.c ist analog > gegengesetzt: > #if PERIPHERIE==PERIPHERIE1 > ..... > void TuWas(int data) > { > .... > } > #else > static int dummy; /* damit irgendwas drin ist, sonst meckert der > Compiler evt. */ > #endif Genau so habe ich das jetzt umgesetzt! Funktioniert wunderbar.
Tuck I. schrieb: > Hi zusammen, > > ich bin gerade dabei ein Programm in mehrere Dateien aufzuteilen. Und in der schliesslich gewaehlten Variante wird wieder mit Praeprozessortricks Teile aus dem Source code selektiert?? BEOBACHTUNG: Das ist fast das Gegenteil des urspruenglichen Ansatzes! Sprich: der Source Code tut was anderes, je nachdem welches #define gesetzt wurde. Unschoen. Ja ich mach solche Sachen auch. Aber bloss, wenn ich tatsaechlich static inline (Tuck I. - schau dir das jetzt bitte noch nicht an .-) Funktionen unterschiedlich haben will. > Es wird vor der Kompilierung entschieden, welche Peripherie ich > einbinde, entweder 1 oder 2. Wie entscheidest Du? Wo wird das hinterlegt? In config.h? In einer Datei, welche das compilieren/linken regelt, wie Makefile oder sowas? Wenn Makefile, definierst Du dann gleich die Ziele 'peripherie1' UND 'peripherie2', damit du nicht wieder im Source-Code rumaendern musst (ich waere entschieden dafuer). Der Zeitpunkt der Enscheidung kann uebrigens auch erst zu Link-Zeit sein, wenn Du eine andere Vorgehensweise waehlst, wie z.B. Makefile mit unterschiedlichen Zielen. > Ich möchte nicht viele verschiedene Funktionsauffrufe verwenden. Vorbildlich. Huete dich vor 'einfachsten' Loesungen. Du warst selber auf dem besten Weg eine sehr saubere und klare Loesung zu finden und nun hast Du dich von #Paeprozessor-Tricks verlocken (versauen!) lassen. Wenn Du noch einen Schritt weiter gehst, von dem getrennten .c-Dateien (und daraus erzeugten .o/.obj-Dateien) zu (statischen) Bibliotheken, dann wirst Du mit dem #if...#else... ganz schoen auf dem Bauch landen. Weil der Name der Objektdatei dannn nicht mehr eindeutig deren Funktionalitaet zuzuordnen ist. Stichwort 'Etikettenschwindel'.
Was ist denn dann die sauberste Lösung für richtige Trennung bzw wo kann man sowas nachlesen? C Cookbook? Diverse Tutorials zeigen entweder Präprozessortricks oder gar keine gleichnamige Funktion. Weil das niemand so macht wie ich mir das vorstelle? Nimmt man die hier schonmal genannten Funktionszeiger? Ist eine Makefileverbiegung nicht auch ein Schritt zur Unübersichtlich? Tausend Fragen eines verwirrten Bastlers.
Funktionszeiger - nein dafuer nicht noetig. Es kommt auf deine Entwicklungsumgebung an. Hast Du 'ne IDE die dir jeden (Standard-)Wunsch von den Augen abliest? Oder machst Du was auf der Kommandozeile? Oder hast Du 'ne IDE aber darfst wenigstens noch deine Makefiles selber schreiben? Zum Verstehen sollte man meiner Meinung nach ein paar mal seine Programme selbst 'bauen' (hier am Beispiel von Linux/*nix mit gcc - ich kann nichts anderes): ein oder mehrere .c-Files 'compilieren' zu .o ; mehrere .o zu einer ausfuehrbaren Datei 'linken' evtl. unter Zuhilfenahme von Bibliotheken .a Schau mal da: https://www.cs.utah.edu/~zachary/isp/tutorials/separate/separate.html Das mit den gleichnamigen Funktionen ist nicht so wichtig. Bei dem was du naemlich am Ende zusammenlinkst, da darf es eh keine gleichnamigen Funktionen geben, sonst gibt es Fehler beim Linken. Du musst naemlich spaetestens beim Linken auswaehlen, welches Objektfile (.o) zu verwenden willst. Der Linker sieht nur was du ihm uebergibst.Getrennt Kompilierung (mehrere .c) ist schon das was du suchst. Was dir noch fehlt, ist: wie wir aus deinen mehrdeutigen Quellen eine gueltige ausfuehrbare Datei. Manche Menschen machen das mit 'make' und seinen Makefiles. Manchmal mit expliziten Shell-Scripten. Manchmal explizit auf der Kommandozeile. Manchmal mit Programmen, die Makefiles generieren. Benutzt Du eine IDE, dann kann es sein, dass die einfach alle Dateien ins ausfuehrbare Programm stecken will und das geht dann eben schief, mangels Selektion. Mit IDEs kenn ich mich nicht aus. Seit 15+ Jahren keine mehr verwendet... PS: Makefile wird nicht verbogen, sondern einmal sagst Du z.B. make peripherie1 das andere Mal make peripherie2 Du aenderst keine Datei, du modifizierst keine Umgebungsvariable oder so. Du sagst, welche Variante du (genau jetzt) willst.
:
Bearbeitet durch User
tuckito schrieb: > Ist eine Makefileverbiegung nicht auch ein Schritt zur Unübersichtlich? Ja. Du bist nach eigenen Angaben ein Anfänger. Und bevor Du anfängst, Makefiles zu verbiegen, solltest Du erstmal innerhalb des Sourcecodes Erfahrungen sammeln. Und ein Makefile erstmal für typische Dinge kennenlernen. Dein Weg mit der #ifdef-Klammer um den Sourcecode ist bislang der einfachste. Ja, wenn Du eigene Bibliotheken erstellst, geht das so nicht. Aber das ist unwichtig, solange Du die genauen Mechanismen von includierten Dateien, extern oder Funktionspointer noch nicht durchdrungen hast. @Marc P: Wenn jemand erste Erfahrungen sammelt, dann ist es m.E. wenig sinnvoll, Alle Register (Make, eigene Bibliotheken, manuelles Linken, ...) zu ziehen. Irgendwann kann keiner mehr ein Hallo-Welt ausprobieren, wenn er nicht den Startup-Code und das Linker-Skriptfile sauber für beliebige noch unbekannte Plattformen erstellt hat. Ja, man kann das Tayloring ins Makefile legen, aber alles zu seiner Zeit.
A. S. schrieb: > Ja, wenn Du eigene Bibliotheken erstellst, geht das so nicht. Warum nicht? Was passiert, wenn ich mehrere Libs mit gleichnamigen Funktionen einbinde. Und zu guter letzt noch eine .o mit einer gleichnamigen Funktion? ;->>>
oder erst die .o Datei und dann die Libs mit gleichnamigen Funktionen? ;->>>
MaWin schrieb: > Warum nicht? Was passiert, wenn ich mehrere Libs mit gleichnamigen > Funktionen einbinde. Und zu guter letzt noch eine .o mit einer > gleichnamigen Funktion? ;->>> Dafür brauchst Du wieder einen Schritt: Für einen Anfänger, der im Ausgangspost die Wirkungsweise von #Include noch nicht verstanden hat, ist es ein Weiter weg, bis er sicherstellen kann, dass seine libs mit Übersetzungs-Einheiten gleicher Funktionsnamen in der notwendigen Reihenfolge angezogen werden. Nur zum Verständnis: Er muss nicht nur wissen, dass der Linker sich aus den Bibliotheken all das raus saugt, was er braucht, dass bei 2 oder mehr gleichen Funktionsnamen nur eine der Übersetzungseinheiten angezogen werden darf, nein, er muss auch noch die Reihenfolge mit ein paar Makefile-Hacks beherrschen. Ich bin mir nichtmal sicher, ob in C definiert ist, wann welches Symbol erstmals in den Bibliotheken gesucht wird...
A. S. schrieb: > Ja, man kann das Tayloring ins Makefile legen, aber alles zu seiner > Zeit. 100% Zustimmung. Ich hoffe, ich habe auch nicht dazu geraten Makefiles zu schreiben, sondern nur kurz und oberflaechlich sagen, was 'man' so machen kann. Ich bin selber von Makefiles abgekommen, ausser bei Standard-Sachen. Das manuelle Linken, das finde ich schon wichtig. Zumal Tuck I. ja schon mehr will als ein Anfaenger. Und er will offensichtlich verstehen. @MaWin > oder erst die .o Datei und dann die Libs mit gleichnamigen Funktionen? Ja. Oder gar 'weak references' (als default-Implementierung) und bei Bedarf mit einer gleichnamigen Funktion aus der .o 'ueberschreiben'... So mach ich das bei den Interrupt-Handlern (an festen Adressen) auf'm ARM. Ist aber schon ein bissl haarig und ich bin nicht so gluecklich damit. (Tippfehler => keine Meldung von Compiler oder Linker, aber nix funktioniert ):
Tuck I. schrieb: > Ist das in C überhaupt möglich? Ja, ich würde mal sagen, dass du hier auf eine C Schwäche gestoßen bist. Klar bekommt man das auch in C irgendwie hingefummelt.... Aber wirklich schön wird das nicht C++ bietet mehr Möglichkeiten gleichnamige Funktionen/Methoden unter zu bringen. Ganz ohne define Klimmzüge. z.B namespaces, Klassen Gibts einen besonderen Grund, warum du mit C startest, und nicht mit C++? Denn später irgendwann, ist der Umstieg von C++ zu C leichter, als der von C zu C++. Beispiel:
1 | namespace peripherie1 |
2 | {
|
3 | void tuwas() |
4 | {
|
5 | // tue dieses
|
6 | }
|
7 | }
|
8 | |
9 | namespace peripherie2 |
10 | {
|
11 | void tuwas() |
12 | {
|
13 | // tue was anderes
|
14 | }
|
15 | }
|
16 | |
17 | // hier wähle welches tuwas() zum default wird
|
18 | //using namespace peripherie1;
|
19 | using namespace peripherie2; |
20 | |
21 | int main() |
22 | {
|
23 | tuwas(); // using bestimmt welches tuwas |
24 | peripherie1::tuwas(); |
25 | peripherie2::tuwas(); |
26 | while(1); |
27 | }
|
Arduino Fanboy D. schrieb: > Ganz ohne define Klimmzüge. echt? Wie bekommst Du den das "richtige" `using namespace` in den Code?
Torsten R. schrieb: > echt? Wie bekommst Du den das "richtige" using namespace in den Code? Kannst Du dort sehen: mit sorgfältigen auskommentieren :-)
was ist der fanbox nur für ein typ laber von cpp obwol nur cgefragt Macht den wech
Wech schrieb: > was ist der fanbox nur für ein typ > laber von cpp obwol nur cgefragt Was ist den daran so schlimm, wenn mal jemand ein Lösung zeigt, die über dem Tellerrand liegt?
Naja so verkehrt ist es ja nicht. Ich hatte auch schon damit geliebäugelt. Nur dieses Mainstream unelitäre "Arduino c/c++ Gewurschtel" will ich nicht verwenden :-)
Torsten R. schrieb: > Was ist den daran so schlimm, wenn mal jemand ein Lösung zeigt, die über > dem Tellerrand liegt? Ich danke dir für die Blumen! Aber lass bitte den "xxx" men laufen, der stalkt mich schon eine kleine Weile. Wird aber auf Grund seiner Defizite, den Arsch nicht in die Hose bekommen.
Tuck I. schrieb: > Nur dieses Mainstream unelitäre "Arduino c/c++ Gewurschtel" will ich > nicht verwenden :-) Vorurteile! C++ ist vielleicht/oberflächlich etwas komplizierter, als C, aber kein "Gewurstel".
Das war ein Spaß! Ich möchte nur kein hipper Programierer sein, der Makerheftchen kauft. Ist ja fast so wie damals als manche in die Bücherei gingen um C64 Bücher mit fertigen Projekten auszuleihen. PS: ebenfalls Spaß
Hallo, wenn ich zu den namespace nochwas sagen darf. Ich würde dann aber dafür sorgen den namespace nicht global zur Verfügung zu stellen. Ansonsten ist der Sinn dahinter wirklungslos. Will sagen das namespace zwar viel möglich macht, aber auch kein Allheilmittel ist. Ansonsten bemerkt man das Problem erst später was man ohne sofort bemerkt hätte.
Veit D. schrieb: > Hallo, > > wenn ich zu den namespace nochwas sagen darf. Ich würde dann aber dafür > sorgen den namespace nicht global zur Verfügung zu stellen. Ansonsten > ist der Sinn dahinter wirklungslos. Will sagen das namespace zwar viel > möglich macht, aber auch kein Allheilmittel ist. Ansonsten bemerkt man > das Problem erst später was man ohne sofort bemerkt hätte. Na... Hier ist der Zweck zwischen zwei Konfigurationen zu wählen. Und das tut man eben, am besten, nur an einer Stelle. Nicht an tausend Stellen im Code, per #define, #indef usw., wenn man es denn vermeiden kann. Wie würdest du das denn lösen?
Hallo, ehrlich gesagt würde ich in dem Bsp. gar keinen globalen namespace anbieten. Sondern nur mit Bereichsnamen arbeiten. Sonst weiß man irgendwann nicht mehr aus welchen namespace "default" kommt. Weil der Blick darauf irgendwann schwindet. Meine Meinung. Meine Hardware Libs mit Klassen sind so aufgebaut das ich global keinen namespace freigeben muss. Intern arbeite ich mit anonymen namespace und mit Bereichsnamen wenn etwas woandersher inkludiert/benötigt wird. Damit habe ich global im Hauptprogramm nur mit Klassennamen und deren Methodenname zu tun und die verschiedensten Libs können dennoch gleich aufgebaut sein mit gleichen struct Bezeichner usw. Als ich das noch nicht so hatte kam es darauf an in welcher Reihenfolge ich den namespace zur Verfügung gestellt und Libs inkludiert habe, einmal kompilierte es, einmal knallte es. Das ist der Grund warum ich vor globaler namespace Freigabe etwas warnen möchte. Man kann sich leicht drin verstricken und wundert sich warum es trotz namespace Kapselung nicht kompiliert.
Veit D. schrieb: > ehrlich gesagt würde ich in dem Bsp. gar keinen globalen namespace > anbieten. Sondern nur mit Bereichsnamen arbeiten. Tut mir leid, aber den Begriff "Bereichsnamen" kann ich nicht in der C++ Spezifikation und auch nicht bei den OOP Design Patern finden. Eigentlich müsste ich dich ja jetzt fragen, was du damit meinst. Aber damit müsste ich ja auch vor mir selber eingestehen, dass ich das nicht weiß. Gerade in diesem Forum, eine Schwäche zugeben? Nee, dafür bin ich zu feige.
Hallo, um bei dem Bsp. zu bleiben. Wenn :: der Bereichsoperator ist, dann ist der Name davor für mich der Bereichsname. In dem Fall peripherie1 und peripherie2. Man kann es auch anders herleiten. namespace kapselt einen Code-Bereich. Den Namen vom namespace kann man in meinen Augen deswegen auch als Bereichsnamen betiteln. Sollte nicht sooo falsch sein. Vielleicht ist es auch einfach alles nur zu viel deutsch. :-) Um dir ein Brücke zu bauen.
1 | ...
|
2 | ...
|
3 | int main() |
4 | {
|
5 | tuwas(); // using bestimmt welches tuwas |
6 | peripherie1::tuwas(); |
7 | peripherie2::tuwas(); |
8 | while(1); |
9 | }
|
Veit D. schrieb: > Wenn :: der Bereichsoperator ist, dann ist > der Name davor für mich der Bereichsname. Danke! "Eine" Definition ist besser, als "keine" Veit D. schrieb: > ehrlich gesagt würde ich in dem Bsp. gar keinen globalen namespace > anbieten. Sondern nur mit Bereichsnamen arbeiten. Sonst weiß man > irgendwann nicht mehr aus welchen namespace "default" kommt. Weil der > Blick darauf irgendwann schwindet. Meine Meinung. Dann muss ich nochmal nachfragen: Wie würdest du eine globale Bereichsumschaltung machen, ohne einen der "Bereiche" mit using zuzuordnen? Verstehe mich bitte richtig. Ich möchte dich nicht kritisieren, nur deine Kritik/Vorschlag verstehen.
Hallo, man könnte sich irgendwas mit Klassen und Parameterübergabe für die Initialisierung ausdenken. Nur hilft das dem TO nicht weiter. C++ kommt ja nur voll zum tragen wenn man verschiedene Objekte mit unterschiedlichen Methoden aber gleichen Methodennamen anlegen möchte usw.. Das alles benötigt der TO nicht. Wenn ich mir den Eingangspost durchlese möchte der TO nur stumpf vorgeben welches Headerfile eingebunden werden soll. Dafür halte ich die Auswahl aus
1 | // #include <peripherie1.h>
|
2 | // #include <peripherie2.h>
|
mit auskommentieren für völlig ausreichend. Man benötigt weder define noch namespace. Alles was man so drumherum bauen könnte hat hier keinen echten Nutzen, wenn man das einmal ganz nüchtern betrachtet. Und weil der TO C und nicht C++ programmiert hat sich das sowieso erledigt. Wir würden mit C++ bestimmt seine Peripherie Klassenfein aufsplitten mit allen drum und dran und am Ende, um bei TO Aufgabe zu bleiben, im Hauptprogramm auch nur eine Klasse für alle Objekte verwenden. Bedeutet großer Aufwand ohne Nutzen. Erst wenn verschiedene Klassen für verschiedene Objekte gemeinsam Verwendung finden sollen sind wir mit C++ klar im Vorteil. Genau das sehe ich hier nicht.
Veit D. schrieb: > Dafür halte ich die Auswahl aus > // #include <peripherie1.h> > // #include <peripherie2.h> > > mit auskommentieren für völlig ausreichend. Nein, das ist es nicht. Denn dafür müsste zusätzlich das makefile geändert werden. Sofern überhaupt eins verwendet wird. Und damit hat man schon min 2 Schrauben an denen gedreht werden muss. Bedenke: Es gibt ja auch noch *.c oder eben *.cpp Dateien, neben den *.h Und doppelte Definitionen mag der Linker nun gar nicht.
Hallo, na jetzt bin ich wirklich verwundert, weil ich das Problem noch nie hatte, dass Lib Dateien angefasst werden die gar nicht inkludiert werden sollen. Ich habe das gerade ausprobiert. Wenn test1.h und test1.cpp neben test2.h und test2.cpp mit gleichen Inhalt (internes include x.h natürlich geändert) existieren aber nur test1.h inkludiert werden soll, dass es dann überhaupt ein Problem gibt. Wäre mir nie in den Sinn gekommen. Ehrlich gesagt finde ich das Verhalten schon etwas merkwürdig.
Veit D. schrieb: > Ehrlich gesagt finde > ich das Verhalten schon etwas merkwürdig. Ich nicht. Jede *.c, *.cpp und auch *.S Datei ist eine eigene Übersetzungseinheit. Irgendwelche *.h, oder welche du davon auswählst, interessiert den Compiler eigentlich überhaupt nicht. Die *.h bekommt er nicht zu sehen, denn der Präprozessor bindet diese in den Code ein und der ist eben vor dem eigentlichen Compiler dran. Veit D. schrieb: > Wäre mir nie in den Sinn gekommen. Siehste, so kannste auch vom dööfsten noch was lernen.
Veit D. schrieb: > Dafür halte ich die Auswahl aus > // #include <peripherie1.h> > // #include <peripherie2.h> > > mit auskommentieren für völlig ausreichend Das ist nicht das Problem des TO. Dem TO reicht ein include (auch wenn er es vorher fälschlicherweise mit 2 versucht hat) und 2 ifdefs. Alternativ funktionsptr oder defines oder oder. Eure Diskussion geht aber am Problem des TO vorbei.
A. S. schrieb: > und 2 ifdefs. Alternativ funktionsptr oder defines oder > oder. Mantra: > Jedes vermiedene Präprozessor Konstrukt ist ein gutes Konstrukt > Jedes vermeidbare Präprozessor Konstrukt ist ein böses Konstrukt Und Pointer belegen, in der Regel, Ram. Auch das ist vermeidbar. A. S. schrieb: > Eure Diskussion geht aber am Problem des TO vorbei. Ja? Darum sagte er sicherlich auch: Tuck I. schrieb: > Naja so verkehrt ist es ja nicht. > Ich hatte auch schon damit geliebäugelt. Und zudem hats ja einen Sachverhalt beim Veit D.(devil-elec) geklärt. Was ja irgendwie auch ein positiver Effekt der Diskussion ist.
Arduino Fanboy D. schrieb: > Mantra: >> Jedes vermiedene Präprozessor Konstrukt ist ein gutes Konstrukt >> Jedes vermeidbare Präprozessor Konstrukt ist ein böses Konstrukt Aber Dein ein- und auskommentieren ist besser?
Hallo, warum geht unsere Diskussion am Problem des TO vorbei? Er hat doch das Problem das er nicht weiß wie er das sauber je nach Bedarf inkludieren soll. Dabei dachte ich etwas naiv ich könnte helfen und verstehe jetzt das Problem des TO besser. Nämlich das es nicht so einfach ist. Wegen meiner Verwunderung nochmal. Wenn der Präprozessor beginnt und nur peripherie1.h inkludieren soll, warum wird dann eine peripherie2.h mit ihrem .c überhaupt angefasst und übersetzt? Letzteres peripherie2.h include bleibt ja auskommentiert. Werden wirklich immer alle "Dateien" übersetzt die so rumliegen obwohl sie gar nicht verwendet werden? Kann doch nicht sein.
Veit D. schrieb: > Wenn der Präprozessor beginnt und nur > peripherie1.h inkludieren soll, warum wird dann eine peripherie2.h mit > ihrem .c überhaupt angefasst und übersetzt? Weil das egal ist. Die Frage ist nicht, was included oder übersetzt wird, sondern was der Linker versucht einzubinden. Ein compiliertes C Programm kann keine Maschine ausfüren. ;-)
Hallo, tut mir leid, ich habs noch nicht verstanden. Ich kann meine Frage auch umformulieren und überspitzen. Wenn der Linker sowieso macht was er will, warum benötigt man dann überhaupt die include Direktive in der main.c? Mit include lege ich doch fest was eingebunden werden soll und was nicht.
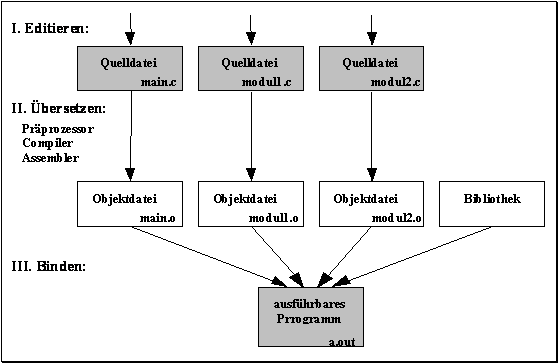
Durch ein #include wird der Text der angegebenen Datei einfach genau an dieser Stelle eingefügt (so etwa wie 'copy paste'). Aus einem C file baut der Compiler ein object file. Das ist quasi der Maschinencode für das gewählte Target. Aber die Abhängigkeiten zwischen den Modulen wurde noch nicht hergestellt bzw. geprüft. Und es fehlt noch das mapping auf den Speicher. Darum kümmert sich der Linker. https://www.informatik.uni-leipzig.de/~meiler/Propaed.dir/PropaedWS12.dir/Vorlesung.dir/V08-Dateien/image002.gif Das solltest du nachlesen und verstehen.
{kind=link}
A. S. schrieb: > Arduino Fanboy D. schrieb: >> Mantra: >>> Jedes vermiedene Präprozessor Konstrukt ist ein gutes Konstrukt >>> Jedes vermeidbare Präprozessor Konstrukt ist ein böses Konstrukt > > Aber Dein ein- und auskommentieren ist besser? Natürlich! Weil das in nur einer einzigen Zeile des Projektes passieren kann/muss. Du benötigst mehrere Zeilen mit Präprozessor Gedönse. Evtl. auch eine makefile Anpassung. Und beim Wechsel der Konfiguration gar ein "make clean" oder die IDE übliche Entsprechung Zudem, falls es dir nicht aufgefallen ist, dann lass dich mit der Nase drauf stoßen: Das Mantra hat eine Hysterese! Und zwar die, in der die unvermeidbaren Präprozessor Konstrukte stecken. Veit D. schrieb: > Wegen meiner Verwunderung nochmal. Wenn der Präprozessor beginnt und nur > peripherie1.h inkludieren soll, warum wird dann eine peripherie2.h mit > ihrem .c überhaupt angefasst und übersetzt? Letzteres peripherie2.h > include bleibt ja auskommentiert. Du reitest weiter auf *.h rum... Das ist nicht zielführend. Die Übersetzungseinheiten sind *.c und *.cpp und auch *.S Dateien. Das hat alles nichts mit *.h Dateien zu tun. Da kannst du auskommentieren, was du willst. Das ist eine ganz andere Baustelle. In der Regel schnappt sich eine IDE, fast egal welche, wenn du auf "Build" drückst, alle übersetzbaren Einheiten und kompiliert diese. Und das sind eben nicht die *.h, wie du es gerne hättest, sondern die *.c und *.cpp und auch *.S Dateien welche dem Projekt zugeordnet sind.
Der letzte Absatz ist der springende Punkt. Wenn man nur in der Konsole arbeitet, tritt das beschriebene Problem nicht auf. Da wird nur exakt das ausgeführt, was man eingibt.
Gnorm schrieb: > Wenn man nur in der Konsole > arbeitet, tritt das beschriebene Problem nicht auf. Da wird nur exakt > das ausgeführt, was man eingibt. Das hat auch mit Konsole nichts zu tun. Es sind einfach zwei Bereiche, die der TO zu Beginn und Veit D. zuletzt durcheinander werfen: In einer C-Datei steht nur drin, was darin steht. Egal ob direkt oder per #include. Das ist nur plain Text. Keine Bibliotheken, keine zugehörigen .c-oder .sonstwas-Dateien. Jede C-Datei wird allein übersetzt. Der Linker macht aus vielen übersetzten Einheiten ein Programm. Hier aus den compilierten Dateien main.c, peripherie1.c und peripherie2.c und noch aus vielen anderen .C und Assembler-Dateien, wo z.B. Startup und printf oder so drin sind.
Hallo, danke für eure Erklärungen. Mir war nicht bewusst, dass sich die Toolchain wirklich allen erreichbaren Quellcode schnappt und übersetzt. Damit sind wir wieder bei meiner Verwunderung. Wenn ich ganz tief nachdenke, ist mir immer noch nicht klar warum das überhaupt so pauschal alles übersetzt wird obwohl es nicht benötigt wird, weil es vom Programmierer nicht inkludiert wurde. Und das der Linker alle Objektfiles zusammenwirft kann ich wirklich noch nicht ganz glauben. Denn wenn man sich ein disassemblierten Quellcode anschaut findet man keine Codeteile die nicht reingehören. Das heißt für mich der weiß am Ende schon was benötigt wird und was nicht. Er prüft das nur in der falschen Reihenfolge. Er könnte sich demzufolge schon vorher Übersetzungsarbeit sparen. Soweit zu meiner Logik.
Ich sehe schon, du benötigst noch einen kräftigen Schuss aus der Blickwinkelkanone. Sollst du bekommen! (nur noch nicht in dieser Minute)
Veit D. schrieb: > danke für eure Erklärungen. Mir war nicht bewusst, dass sich die > Toolchain wirklich allen erreichbaren Quellcode schnappt und übersetzt. Eine toolchain tut von sich aus gar nichts. Und auch eine IDE nicht. Beide tun immer nur genau das, was jemand definiert. Wenn das nicht das ist, was erwartet wird, sitzt die Ursache dafür vor dem Rechner. Oliver
Veit D. schrieb: > Und das der Linker alle > Objektfiles zusammenwirft kann ich wirklich noch nicht ganz glauben. Der Linker nimmt A) Alle Objectifles, die ihm direkt übergeben werden (*), meist aus C-Files oder Assembler, die Du für Dein Projekt auswählst B) Nur die Objectfiles aus den Bibliotheken (*), die Symbole enthalten, die noch fehlen. Z.B. ein printf, wenn es nicht A ist. Er bindet dann jeweils das ganze Objectfile ein, also alles, was im zugehörigen C-File stand. Darum hat ein abs.c gefühlt eine Zeile Code und steht nicht mit 10 anderen Funktionen in einer Datei. C) Manchmal ein paar implizite Dinge wie z.B. Startup-Code oder Dos-Umgebung oder so Die Toolchain "schnappt" sich nichts. Für die meisten spielt sich das nur im "unbekannten Makefile" ab. Ganz sicher aber bindet ein "include <X.h>" nichts von X.c ein. (*) Meist von Dir im Makefile oder in einer Batchdatei angegeben.
Veit D. schrieb: > ist mir immer noch nicht klar warum das überhaupt so pauschal > alles übersetzt wird obwohl es nicht benötigt wird, weil es vom > Programmierer nicht inkludiert wurde. Hier ist dein Gedankenfehler! Du includierst nur *.h Dateien. Die löst der Präprozessor auf, bevor der Compiler los läuft. Der Compiler bekommt nur die modifizierten *.c und *.cpp zu sehen. Und genau an der Stelle ist dein Satz: > weil es vom Programmierer nicht inkludiert wurde. Falsch! Denn du includierst ja keine *.c oder *.cpp Dateien. Niemals! ... nehme ich mal ganz stark an ... Angenommen, in der main.cpp findet sich dieses #include "test1.h" #include "test2.h" Und du nimmst einen weg: //#include "test1.h" #include "test2.h" Das kannst du tun, macht manchmal Sinn... Diese Änderung hat erstmal ausschließlich Auswirkungen auf die erzeugte main.o Aber irgendwann übersetzt der Compiler ja die test1.c und der bekommt von deiner Änderung nix mit. Denn die test1.c ist ein eigenständiger Übersetzungsvorgang. Solange test1.c deinem Projekt zugeordnet ist, wird sie übersetzt. Änderungen in der main.c haben darauf keine Auswirkungen. Mit anderen Worten: main.c und test1.c sind zwei völlig unterschiedliche Übersetzungseinheiten! Zwischen diesen beiden Übersetzungsvorgängen gibt es keine Art von Kommunikation. Darum können die auch an verschiedenen Ecken der Welt vorgenommen werden. Veit D. schrieb: > Und das der Linker alle > Objektfiles zusammenwirft kann ich wirklich noch nicht ganz glauben. > Denn wenn man sich ein disassemblierten Quellcode anschaut findet man > keine Codeteile die nicht reingehören. Ja klar! Der Linker hat ein Regelwerk, anhand er das fertige Programm zusammen flickt. Er bekommt eine Latte an *.o *.a, oder was auch immer, vor die Füße geworfen. Und hier bekommt er eben beide zu sehen! Die test1.o und die test2.o, egal, was du in main.cpp angestellt hast. Unter anderen führt er Referenzzähler o.ä. mit. Wichtig ist ihm die *.o, wo die main() liegt. Er bindet in den fertigen Code nur die *.o ein, wo mindestens 1 "Objekt/Element" aus der main.o heraus referenziert wird. Dafür ist das Arduino Serial ein gutes Beispiel! Angenommen: UNO Programm, ohne Serial. In den IDE Meldungen siehst du klar, dass der Compiler HardwareSerial.cpp anfasst. Schaust du aber in den erzeugten Code, sieht man nix von Serial. Noch nicht mal die ISR. Machst du aber nur ein Serial.begin(9600); dann wird auch die ISR etabliert. Alles ohne, dass ein Include verändert wurde. Schau dir in der IDE Ausgabe, das log an, dann siehst du welche *.cpp und sonstige kompiliert werden. 1 bis 2 Dutzend *.o werden erzeugt. Diese dann fein nacheinander in ein Archiv core.a gestopft. Zu guter Letzt, bekommt der Linker anwendung.o und core.a vorgeworfen und macht seinen Job, incl. diverser Optimierungen, wie z.B. unbenutzte Methoden/Funktion/Variablen zu entsorgen. Das aus der *.elf dann noch eine *.hex und eine *.eep gebastelt wird, geschenkt. ---- Die Arduino Besonderheit: Machst du in der anwendung.ino ein #include <Irgendwas.h> Dann findet der Arduino Builder das, durchsucht die Lib Ordner nach dem Kram, kopiert alle zugehörigen Dateien mit in den temporären build Ordner, und bezieht die dort gefundenen Übersetzungseinheiten mit ein. Hier hat das Auskommentieren einer Lib eine etwas größere Tragweite. Da eben der Builder selber Präprozessor spielt. Wie gesagt: Eine Besonderheit. Andere IDEs tun das nicht so, die halten sich an ihr Projekt Konzept. Sind so evtl. etwas fixer.
Hallo Arduino Fanboy,
diese Erklärung kann ich nun nicht mehr falsch verstehen. Der Schuss hat
gesessen. Hatte zwischendurch schon an mir gezweifelt. Auch schön das du
mir die Antwort auf den Arduino libraries Ordner vorweg genommen hast.
Darauf wäre ich auch noch gekommen, hat sich damit erledigt. Ich werde
mir die Logausgabe genauer anschauen.
Vielen Dank für die Zeit und Mühe.
Damit kann ich dir abschließend deine Frage beantworten. :-)
> Wie würdest du das denn lösen?
In C mit define Orgien und in C++ mit namespace. :-)
Natürlich auch allen anderen vielen Dank, die ich nun auch verstehe.
Manchmal braucht es bestimmte Worte.
Edit:
wünsche noch ruhige Ostern
:
Bearbeitet durch User
Hallo, eine Idee daraus folgend habe ich noch. Wenn der TO seine Libs auf Header only umschreibt, dann sollte er um define drumherumkommen und mit include<...> auskommen. Ich hoffe der TO liest noch mit.
Naja, dadurch, dass man alle Funktionen und Variablen in einer solche *.h als inline und/oder static definieren muss, könnte es schon unangenehme Seiteneffekte haben. z.B. können die gelinkten Übersetzungseinheiten keine Daten mehr über Variablen austauschen, da jede Übersetzungseinheit ihren eigenen Satz an Funktionen/Variablen hat. Auch könnte/wird der Programmspeicher und RAM Bedarf steigen. Result: Möglich! Kann allerdings einen Rattenschwanz an Problemen mit sich bringen.
Veit D. schrieb: > ine Idee daraus folgend habe ich noch. Wenn der TO seine Libs auf > Header only umschreibt, dann sollte er um define drumherumkommen und mit > include<...> auskommen. Ich hoffe der TO liest noch mit. Code in .h-Dateien und dann per include einbinden? Das ist das Gegenteil von strukturiert und modularisiert. Im Einzelfall gerechtfertigt, gegenüber den gängigen (und genannten) Alternativen Murks.
Ich lese noch mit. Ist schön was von der Blickwinkelkanone abzubekommen :-)
A. S. schrieb: > B) ... Er bindet dann > jeweils das ganze Objectfile ein, also alles, was im zugehörigen C-File > stand. Bist du dir da sicher? ;->
MaWin schrieb: > Bist du dir da sicher? ;-> Ja. Auch wenn heutige Compiler das unterdrücken können, weil sie es vom C++Bruder kennen.
A. S. schrieb: > Auch wenn heutige Compiler das unterdrücken Das dürfte der Realität entsprechen. :-)
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.