Hi Folgendes Problem: Auf einer Webseite kann mit über eine Suchmaske (mit javascript gestaltet) auf Tausende Wissenschaftsartikeln zugriefen. Auf den jeweiligen Artikelnseiten gibt es dann zumeist ein Dutzend pdf Dokumente zum Thema. Ich möchte nun die Seite in ihrem kompletten Umfang herunterladen, zumindest die Artikelseiten mit den jeweiligen pdf´s Wie bekomm ich dies am einfachsten hin? Problem ist wohl, dass sie Artikelseiten ausschließlich über die Suchmaske erreichbar sind und nicht über irgendwelche Links auf der Webseite...
Christian Kramer schrieb: > Ich möchte nun die Seite in ihrem kompletten Umfang herunterladen Oft ist das in den Nutzungsbedingungen der Webseite untersagt, und führt bei Zuwiderhandlung unweigerlich zu mehrjährigen Haftstrafen.
die Suchergebnisse haben dann in der URL Leiste das folgende Format: example.com/article/result=[string] [string] ist immer 484 Zeichen lang ist und besteht aus Klein- und Großbuchstanben, sowie Ziffern und die Zeichen "-" und "_", also 64 Möglichkeiten pro Stelle [string] ändert sich auch nicht, ist beim selben Artikel immer identisch, egal wann und auf welchen Geräten man die Seite öffnet
Christian Kramer schrieb: > und die Zeichen "-" und "_", also 64 > Möglichkeiten pro Stelle Sieht aus wie Base64URL-kodiert. Was kommt beim Dekodieren raus? https://base64.guru/standards/base64url/decode
Angehängte Dateien:
-

yeah-sure.jpg
70 KB

Scharfrichter schrieb: > Oft ist das in den Nutzungsbedingungen der Webseite untersagt, und führt > bei Zuwiderhandlung unweigerlich zu mehrjährigen Haftstrafen.
Scharfrichter schrieb: > Oft ist das in den Nutzungsbedingungen der Webseite untersagt, und führt > bei Zuwiderhandlung unweigerlich zu mehrjährigen Haftstrafen. im UrhG §87c sind die Ausnahmen geregelt, wann das "wget -r" zum Duplizieren der Artikeldatenbank erlaubt wäre. Leider alles mit Querverweisen hin und her, ist also einiges zu Lesen. "Mehrjährige Haftstrafen" hab ich dort nicht gefunden. https://www.gesetze-im-internet.de/urhg/__87c.html
erinnert irgendwie fast an Jstor und Aaron Schwartz... der wollte auch mal zuviel donloaden
Εrnst B. schrieb: > "Mehrjährige Haftstrafen" hab ich dort nicht gefunden. Möglicherweise wurde § 202 a StGB überdehnt. Ich halte es allerdings eher für Ironie.
Christian Kramer schrieb: > auf Tausende Wissenschaftsartikeln zugriefen Einfach das ganze Internet herunterladen, da ist dann das richtige schon dabei. Georg
Georg schrieb: > Einfach das ganze Internet herunterladen, da ist dann das richtige schon > dabei. Um Gottes Willen, das führt zu mehrfach lebenslänglich 😱
Mario M. schrieb: > Christian Kramer schrieb: >> und die Zeichen "-" und "_", also 64 >> Möglichkeiten pro Stelle > > Sieht aus wie Base64URL-kodiert. Was kommt beim Dekodieren raus? > > https://base64.guru/standards/base64url/decode leider nix, kommt nichts bei raus... hier mal ein string:
1 | 03AGdBq26Us66M1pxQxfuUwFzWundM9zL-5BvgUIGwqWKS60KkHcR0dIeJp83CKEzCoAFt0kKskJNTW1D8Hw0DgRi8Uu94-W9ZV9U_4gIh4Fdqd4_gHdc-ApsP6egDTzUs6Ve7eCzfgpBQjamPrnbxWpKe2YKjGMOzBIzw7c-6M8DyxUFLIq46YDgHtKtLLd7JaUpEjEkMNqqTVhVOvrcEl2QkedHwUUov9SZ8u25xfsyoI1VUyWc-KdYNhXKYx3WeEzKpzF13JVvK2d3dNUJ4P8q_ieZb8_mVtuURtVX79F4GN0kW4JS-TcJC42h_1Ksr3rvdAmT5UD2J6Y1Nmghqh_FyaO5p6aP5fEgzyZvUy2NtJiQ1rPNV1OjuRcYikJTuc9vDZoHIHA5ebgHSERHxmVEhUZt7VR7a3Y4Mwn7hnQd9LqHf40od1MnYVja9xNGKJujetuRXJOXG2bCQ3WcLRe3pQ87sotauwA |
Scharfrichter schrieb: > Um Gottes Willen, das führt zu mehrfach lebenslänglich 😱 Die Stromrechnung kann der TO niemals zahlen fuer den Traffik und die Speichermedien. Die CO2 Blockwarte werden ihn lebenslaenglich in Schutzgewahrsam, bzw. Sicherheitsverwahrung, nehmen. Hat der TO es schon mit wget oder curl versucht? Aussagen dazu glaube ich ohne Glaskugel nicht gesehen zu haben.
Christian Kramer schrieb: > Wie bekomm ich dies am einfachsten hin? Einfach die gesuchte Pdf herunterladen (falls möglich). Inwieweit die Referenzen eine Rolle spielen bzw. ob man die überhaupt braucht, muss man erstmal gucken, aber es gibt natürlich diese lästige Unkultur der Linkorgien. Meistens kann man die nötigen Refs aber auch noch mal einzeln suchen, und extra herunterladen. Oft ist es aber auch so, dann findet man die eine oder andere Referenz gar nicht, bzw. nur mit Sonderrechten, Buch vergriffen usw. Kann man meistens auch mit klarkommen - wenn auch schade, und so manche Ref ist auch noch deutlich verständlicher und weniger linkverseucht, als der Original-Artikel. Das gilt vor allem für viele ganz alte Artikel - die man oft aber eher in Bibliotheken als Papierversion/Zeitschriftartikel findet. Nur mal als Beispiel: https://web.mit.edu/alexmv/6.037/sicp.pdf Man arbeitet erstmal so gut es geht, konzentriert das jeweilige Kapitel durch, und schaut anschließend nach den Referenzen, ob man die noch braucht zum Verständnis, zur Vertiefung, oder warum auch immer.
Mario M. schrieb: > Re: Webseite herunterladen Und dann hier zeigen damit die mods richtig löschen können…
https://www.cyotek.com/cyotek-webcopy kannst du mal probieren. Ansonsten liefert Google viele online und offline programme, kostenpflichtige, demos, freeware...ist alles dabei.
Dieter schrieb: > Hat der TO es schon mit wget oder curl versucht? wget hat nur die Webseite inkl. einiger Unterseiten heruntergelanden, keinen einzigen der besagten Artikeln qq schrieb: > https://www.cyotek.com/cyotek-webcopy > kannst du mal probieren. hier wird bereits im Vorfeld gesagt: "What can WebCopy not do? WebCopy does not include a virtual DOM or any form of JavaScript parsing. If a website makes heavy use of JavaScript to operate, it is unlikely WebCopy will be able to make a true copy if it is unable to discover all of the website due to JavaScript being used to dynamically generate links."
Schon mal mit ftp probiert? Bei einigen .edu Seiten landet man mit ftp im Archiv der Site und kann sich entsprechende Dokumente herunter laden. Könnte evt. auch hier funktionieren.
ftp geht leider auch net bin aber einen Schritt weiter. Hab nun aber eine möglichkeit gefunden. Kann einen Artikel mit diesem Linkformat herunterladen: example.com/article/numConst=12345678 Die Artikel sind aber wild verteilt, das heißt, der nächste Artikel ist nicht etwa ...12345679 sondern kommt vielleicht erst bei ...12345800 wie würdet ihr nun weiter vorgehen?
Christian Kramer schrieb: > wie würdet ihr nun weiter vorgehen? die anderen oben genannten (einschlägigen) "Taktiken" durchprobieren. FTP war früher, so zur Jahrtausendwende eine gute Strategie.., Sachen zu finden/ bzw. herunterzuladen. Es gab sogar ziemlich gute FTP-Suchmaschinen. Bei Downloads mit Adresse und wilder Verteilung müsste man halt "zu Fuß" abschreiben, bzw. in eine (Download-) Liste eintragen und dann herunterladen lassen.
Christian Kramer schrieb: > wie würdet ihr nun weiter vorgehen? Wenn die Webseite so vehement versucht, sich aktiv gegen illegale Downloads zu wehren, brauchst du einen größeren Hammer. Headless Chrome würde sich anbieten: https://developers.google.com/web/updates/2017/04/headless-chrome oder headless firefox, selenium & co, evtl. auch ein altes phantomjs. Allen gemeinsam: Sie implementieren deutlich mehr "Browser" als reine Download-Tools, führen also auch Javascript aus.
warum sollte man eigentlich noch immer alles mögliche downloaden wollen, wenn es heutzutage genügend Leute parallel gibt, die die selben Infos ins Web stellen. Wir sind langsam in einer Zeit angekommen, wo man fragen kann, wo man denn KEINEN Internetzugang hat. Das allermeiste ist ausserdem doch mittlerweile so oft verfügbar, dass ich es verstehen würde, wenn es langsam mal einen Filter gibt, der nach der Massgabe einen Upload verhindert, dass es das beabsichtigte schon mehrfach gibt.
> die die selben Infos ins Web stellen
Das taeuscht.
Beispiel: TCPMP-Player fuer Windows.
Gibt es, allerdings weitgehend unbrauchbar, zigmal an zig Stellen
zum Download.
Das fehlende AAC (oder war es das AVC?)-Plugin gab es mal an
genau einer Stelle.
Allerdings wird der TO mit seinen Downloads auch nicht gluecklich
werden. Viele Publikationen sind nur mit dem entsprechenden
Fachwissen verstaendlich. Der TO scheitert ja schon an einfachen
technischen Dingen.
>curl
in der letzten c't gab es einen Artikel dazu. In Firefox soll es damit
recht einfach sein, Videos herunterzuladen. Von pdf ist nicht die Rede.
Ich habe diesen Tipp noch nicht ausprobiert, klingt aber
vielversprechend.
CRT schrieb: > Das taeuscht. > Beispiel: TCPMP-Player fuer Windows. > Gibt es, allerdings weitgehend unbrauchbar, zigmal an zig Stellen > zum Download wieso, das IST doch gerade das was ich meine. Wenn es das Ding schon an einigen Stellen gibt, warum müssen es dann erst noch zig Stellen werden?
● Des I. schrieb: > der nach der Massgabe einen Upload verhindert, > dass es das beabsichtigte schon mehrfach gibt. Das ist gegen die Natur des Internets. Ein Berufsfotograf, der vor Jahren eine bekannte Ansicht eines Canyons in den USA aufgenommen und veröffentlicht hat, wollte 20 Jahre später mal sehen, was aus seinem Bild geworden ist - bei Instagram fand er 26000 Fast-Kopien davon, und im Canyon gibt es an vielen Tagen kaum noch Stehplätze. Selbst wenn man weiss, dass es ein Bild vom Kölner Dom schon 10000 mal im Netz gibt, das hält niemanden davon ab seine persönliche Version der Welt zu präsentieren. Georg
Christoph db1uq K. schrieb: >>curl > in der letzten c't gab es einen Artikel dazu. In Firefox soll es damit > recht einfach sein, Videos herunterzuladen. Von pdf ist nicht die Rede. > > Ich habe diesen Tipp noch nicht ausprobiert, klingt aber > vielversprechend. Funktioniert.
Angehängte Dateien:
-

firefox_cUrl.png
71 KB
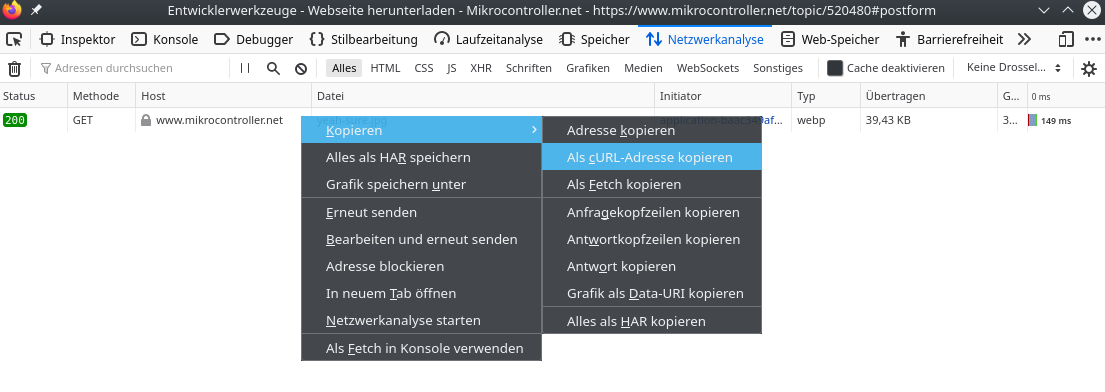
Christoph db1uq K. schrieb: > Was heißt "Funktioniert"? Für Videos oder auch für das Problem des TO? Du kannst im Firefox-Debugger auf einen beliebigen Netzwerk-Request klicken, und dort "copy as cUrl" auswählen. In der Zwischenablage hast du dann eine Kommandozeile, die den Request 1:1 mittels cUrl nachbaut, also mit allen Headers, Cookies, Referer usw. Hilft, wenn der Download nur wegen solcher Sachen nicht automatisch klappt. Hilft dem TE aber vmtl. nicht viel weiter, denn er braucht ja die URLs zuerst, und die kommen aus Javascript. Und jede Datei erst einmal von Hand im Firefox herunterzuladen, nur um sie anschließend ein zweites Mal per Kommandozeile laden zu können, ist eher Sinnbefreit. Insofern: Headless Chrome, Seite aufrufen lassen, Suche ausführen lassen, Downloads auf "automatisch akzeptieren" stellen, querySelektor auf alle PDF-Links, alle anklicken lassen, fertig. Und wenn es nicht ganz ohne GUI laufen muss, tut's vielleicht auch der normale Webbrowser und ein wenig Copy&Paste-JavaScript in der Konsole oder als Bookmarklet.
> wieso, das IST doch gerade das was ich meine.
Was an "unbrauchbar" ist dir nicht verstaendlich?
Ohne AAC/AVC funktioniert kein MP4.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.