Werden verlustlose Kompressionsalgorithmen noch weiter entwickelt? Ich meine solche für alle Dateien. Also werden zip & Co noch weiter entwickelt? Ist das heutige Format von zip noch das selbe pkzip-2 von vor 25 Jahren? Das pkzip-1 ist glaube ich nicht mehr gebräuchlich und kann von vieler Software auch nicht mehr ausgepackt werden. Werden noch neue Algorithmen entwickelt? Jedenfalls gab es schon lange kein Update mehr von http://compression.ca/act/ Heute scheint ja fast jeder den alten zip (pkzip-2) oder in der Linux-Welt den gz bzw tgz zu verwenden. Früher gab es ja eine ganze Reihe. arj, lha, lzh fallen mir da zuerst ein, aber es gab noch mehr.
Google ist da (neben anderen) in der Forschung recht aktiv. z.B. "snappy" (schnell, wenig CPU) und "brotli" (auf HTML&Co optimiert). Auch die Nachfahren des 1977er Lempel-Ziv werden weiteroptimiert, LZMA (z.B. in xz, 7zip) und LZ4 (z.B. im SquashFS) haben einigermaßen Verbreitung.
In Linux findet man auch bzip2 und gelegentlich xz. Als Algorithmus ist Zstandard schwer im kommen.
(prx) A. K. schrieb: > Als Algorithmus ist > Zstandard schwer im kommen Übrigens auch eine "Verfeinerung" des 1977er Lempel-Zivs, diesmal von Facebook. Also: es tut sich was.
Zstandard ist momentan so ziemlich der Platzhirsch was generische Kompressionsalgorithmen angeht. Es hat am unteren Ende einen ziemlich guten Durchsatz, wie es z.B. in VPNs benötigt wird, wo bisher LZO sehr populär war. Mit Zugabe von RAM und CPU-Zeit/Kernen skaliert der Kompressionsfaktor am oberen Ende sehr gut. Quasi der Opus-Codec unter den Kompressoren ;-)
Maik schrieb: > Heute scheint ja fast jeder den alten zip (pkzip-2) oder in der > Linux-Welt den gz bzw tgz zu verwenden. Die sind in ihrer Urform wohl eher mausetot. Da wo Heutzutage Zip draufsteht kann sehr viel verschiedenes drin sein: - https://de.wikipedia.org/wiki/ZIP-Dateiformat#Packalgorithmen Und die Anzahl der verfügbaren Programme die das bzw. Teile davon verarbeiten können ist jetzt auch nicht gerade klein: - https://de.wikipedia.org/wiki/Liste_von_Datenkompressionsprogrammen Maik schrieb: > Werden noch neue Algorithmen entwickelt? Dazu müsste erstmal jemand eine Idee haben wie er die bestehenden (und erprobten) signifikant verbessern könnte. Und selbst wenn jemand da mal einen Geistesblitz hätte muss sich dessen Idee auch erstmal am Markt durchsetzen und eine breite Unterstützung erfahren. Viele Formate die mit der Zeit mal so gab haben sich nie durchgesetzt, weil die Verbesserung gegenüber den etablierten einfach viel zu gering war und somit auch wenige Interesse daran hatten das zu integrieren.
Beitrag #6739199 wurde von einem Moderator gelöscht.
Maik schrieb: > Werden verlustlose Kompressionsalgorithmen noch weiter entwickelt? Da Speicher immer billiger werden, lohnt sich das m.E. nicht wirklich.
Zstandard wurde mit Fokus auf Tempo entwickelt, nicht auf Kompressionsrate. So ist beim Einsatz in Filesystemen nicht das letzte Prozent wichtig, aber sehr wohl das Tempo.
(prx) A. K. schrieb: > Zstandard wurde mit Fokus auf Tempo entwickelt, nicht auf > Kompressionsrate. So ist beim Einsatz in Filesystemen nicht das letzte > Prozent wichtig, aber sehr wohl das Tempo. Trotzdem packt Zstandard besser als gzip und bzip2 https://lutz.donnerhacke.de/Blog/Kompressionsverfahren-im-Vergleich
GNU tar kann übrigens schon Zstandard. https://www.golem.de/news/komprimierung-gnu-tar-unterstuetzt-zstandard-1901-138505.html Die offizielle Ausgabe von 7-Zip kann es leider noch nicht.
Auch heise schreibt dazu ziemlichen Bullshit https://www.heise.de/news/C-Library-Libzip-1-8-erstellt-ZIP-Files-mit-Zstandard-Kompression-6113648.html Nein Zstandard ist kein Standard des ZIP-Formates.
grrr schrieb: > GNU tar kann übrigens schon Zstandard. Naja, was heißt "kann"? Wie bei gzip, bzip2, xz und noch ein paar anderen hat tar die Möglichkeit, das Kompressionsprogramm gleich mit aufzurufen, damit man das nicht per Pipe selbst machen muss. Aber ansonsten hat tar mit Kompression nix am Hut.
Am besten mal im Forum https://encode.su/ umsehen, da gibt's auch regelmaessige Wettbewerbe und Benchmarks. Besonders in der Bildkompression gibt's immer wieder neue Ansaetze, recht interessant sind Praediktoren, die sich dem Kontext anpassen. z.B. lassen sich so multispektrale Bilder sehr gut mit einfacher Hardware komprimieren. Ist aber eher was, was man in der freien Wildbahn (Browser) nicht zu sehen kriegt. Bei generischen Daten ist allerdings nicht mehr so wahnsinnig viel rauszuholen.
:
Bearbeitet durch User
Hallo interessant - wenn man den erstmal ein "Studium" hinter sich hat um zu verstehen was du da geschrieben hast ;-) Etwas Alltagtauglicher formuliert darf es auch in einen Technischen forum sein... Jemand
Angehängte Dateien:
-

packer.png
5,3 KB
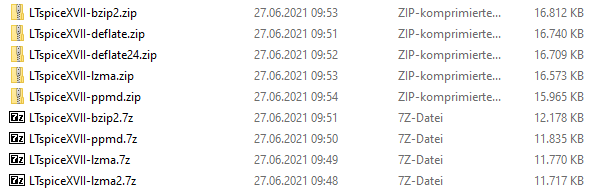
Mein nicht repräsentativer Test mit 7-Zip 21.02 alpha hat ergeben -> siehe screenshot.
grrr schrieb: > Mein nicht repräsentativer Test mit 7-Zip 21.02 alpha hat ergeben > -> > siehe screenshot. Blödsinnige Angabe Wichtig ist die Summe der Zeiten komprimieren und dekomponieren! Der Rest ist Pea….!
??? schrieb: > grrr schrieb: >> Mein nicht repräsentativer Test mit 7-Zip 21.02 alpha hat ergeben >> -> >> siehe screenshot. > > Blödsinnige Angabe > > Wichtig ist die Summe der Zeiten komprimieren und dekomponieren! > > Der Rest ist Pea….! Blödsinniger Kommentar. Wenn für dich nur die Zeit wichtig ist und der Rest Pea.. ist, dann komprimiere eben gar nicht. ??? schrieb: > Vergaß unkomprimiert wie groß? Die Relation sagt doch auch was aus. Aber bitteschön: Größe: 29,1 MB (30.587.884 Bytes) Größe auf Datenträger: 50,3 MB (52.834.304 Bytes) 9.894 Dateien, 37 Ordner
Maik schrieb: > Werden noch neue Algorithmen entwickelt? Nein. Vor allem bei H265 ist jetzt endgültig und für immer Ende Gelände! Andernfalls rasten die Obsoleszenz/DVB-T Zausels hier total aus, wenn sie nen H266 Reciver kaufen müssen. :-)
grrr schrieb: > Die Relation sagt doch auch was aus. > Aber bitteschön: > Größe: 29,1 MB (30.587.884 Bytes) > Größe auf Datenträger: 50,3 MB (52.834.304 Bytes) > 9.894 Dateien, 37 Ordner Nein Da nicht bekannt ist, um welche Daten es sich handelt, ist deine „Messung“ ebenfalls nichtssagend.
funker1 schrieb: > Zstandard ist momentan so ziemlich der Platzhirsch was generische > Kompressionsalgorithmen angeht. Wobei man zstd mit '--train' auch etwas optimieren kann. Lohnt sich aber wohl nur für kurze Dateien..
Beitrag #6739670 wurde von einem Moderator gelöscht.
Future-TV schrieb: > Maik schrieb: > >> Werden noch neue Algorithmen entwickelt? > > Nein. Vor allem bei H265 ist jetzt endgültig und für immer Ende Gelände! > Andernfalls rasten die Obsoleszenz/DVB-T Zausels hier total aus, wenn > sie nen H266 Reciver kaufen müssen. :-) Es wäre mir neu, dass h265 zur verlustlosen Komprimierung jeglicher Art von Daten gedacht ist.
Harald W. schrieb: > Da Speicher immer billiger werden, lohnt sich das m.E. nicht wirklich. Schon mal dran gedacht, dass Daten nicht nur gespeichert, sonder evtl. auch uebertragen werden muessen? Gerade bei Technologien wie LoRaWAN, wo man nur recht kleine Pakete senden kann, kann Datenkompression schnell ein Thema werden.
Kaj schrieb: > Schon mal dran gedacht, dass Daten nicht nur gespeichert, sonder evtl. > auch uebertragen werden muessen? Speziell bei Cloudsystemen kommt das zum Tragen. Speicher ist zwar recht günstig, Du musst aber auch die zu übertragenen Daten bezahlen und das ist dann nicht ohne. Daher ist eine gute Komprimierung sehr wichtig. Die Zeit ist hier oft irrelevant. Beispielsweise bei Datensicherungen.
Der theoretisch mögliche Kompressionserfolg für einen Bitstrom lässt sich doch m.E. ausrechenen (Entropie usw.), unabhängig davon, ob man einen Algorithmus hat, der das auch erreicht. Gibts eigentlich irgendwo einen Vergleich, wie nahe die real verfügbaren Verfahren an diesen theoretischen Wert herankommen?
Frank E. schrieb: > Der theoretisch mögliche Kompressionserfolg für einen Bitstrom lässt > sich doch m.E. ausrechenen (Entropie usw.), unabhängig davon, ob man > einen Algorithmus hat, der das auch erreicht. Es gibt wissenschaftliche Ansätze, dass Masse, Energie und Information äquivalente Größen sind. Jemand hat mal ausgerechnet, was pysikalisch die kleinste Energieeinheit ist, um eine informatische Zustandsänderung (von 0 nach 1 oder umgekehrt) zu bewerkstelligen.
Gibt es eigentlich auch real nutzbare Kompressions-Algos, die mit Hilfe von Pi oder anderen irrationalen Zahlen arbeiten? Das würde sich ja anbieten. Meine siebenstellige Telefonnummer findet sich bei Pi z.B. ungefähr bei der 300000sten Stelle (kann man online ausprobieren).
johann schrieb: > Es gibt wissenschaftliche Ansätze, dass Masse, Energie und Information > äquivalente Größen sind. Und jemand juxte folglich mit der These, dass zu viel konzentrierte Information zu Materie kondensiert. Also sollten wir vielleicht aufpassen, dass wir nicht zu viel Redundanz rausnehmen. Sonst haben wir hinterher zwar ein paar Sandkörner mehr, aber die Information ist verschütt. ;-)
:
Bearbeitet durch User
johann schrieb: > Gibt es eigentlich auch real nutzbare Kompressions-Algos, die mit Hilfe > von Pi oder anderen irrationalen Zahlen arbeiten? Das würde sich ja > anbieten. > Meine siebenstellige Telefonnummer findet sich bei Pi z.B. ungefähr bei > der 300000sten Stelle (kann man online ausprobieren). Und wie viele Stellen braucht der Index, um die Position jeder erdenklichen Telefonnummer (oder von mir aus auch nur jeder erdenklichen 7-stelligen Nummer) darstellen zu können? Das wäre doch mal eine schöne Aufgabe für einen Mathematiker.
(prx) A. K. schrieb: > johann schrieb: >> Es gibt wissenschaftliche Ansätze, dass Masse, Energie und Information >> äquivalente Größen sind. > > Und jemand juxte folglich mit der These, dass zu viel konzentrierte > Information zu Materie kondensiert. Dieser 'Juxende Jemand' war der berühmte SF-Autor und Philosoph "Stanislaw Lem". Er schlug damit einen Bogen zur Bibelstelle "Am Anfang war das Wort und das Wort war bei Gott. ... Und das Wort ward Fleisch" (Johannesevangelium, Verse 1 - 4 ) . Ja als Pole kannte sich Lem auch in der Katholischen Glaubenslehre aus. Leider fällt mir gerade nicht der Titel von der Geschichte ein. In dieser wurde beschrieben, wie alles Wissens und Information in einem Grossrechner gespeichert wurde,welcher auf eine Präzesionswaage stand und dessen Speicher sich nach Überschreiten einer kritischen Dichte leerten aber anschliessend der Computer ein paar Nanogramm schwerer war. -- Im Zusammenhang mit Datenkompression ist allerdings ein anderes Werk von S. Lem interessanter: "Die Stimme des Herrn". Es beginnt damit das in einer vermeidliche Zufallsfolge (Radiosignal Neutronenstern) eine Periodizität entdeckt wird, was die Folge als hochkomprimierte ausserirdische Nachricht erkennbar macht. https://de.wikipedia.org/wiki/Die_Stimme_des_Herrn Das ist übrigens das Kennzeichen einer maximal komprimierten Information, die Symbole darin sind zufällig verteilt. Und diese Grundwissen aus der Codierungstheorie kennt der aufmerksame SF-Leser spätestens seit den Sechszigern ... -- >Meine siebenstellige Telefonnummer findet sich bei Pi z.B. ungefähr bei >der 300000sten Stelle (kann man online ausprobieren). Tolle Komprimierung :-( ; statt den ca 24 bit der Telefonnummer übermittelt man 19bit der Position innerhalb der Tranzendenten Konstante plus einen Algorithmus zu deren Ermittlung ...
Fpgakuechle K. schrieb: > Leider fällt mir gerade nicht der Titel von der Geschichte ein. Im Deutschen ist sie als Teil der Sterntagebücher erschienen. Das Original erschien separat 1973. "Professor A. Donda": "Der titelgebende Professor Affidavit Donda entdeckt während seiner Arbeit in einem afrikanischen Entwicklungsland, dass auf Computern gespeicherte Information eine Masse hat. Dies wird jedoch zu spät entdeckt, sodass sich eine kritische Masse an Daten bildet, deren Explosion alle elektronischen Geräte weltweit zerstört und damit die menschliche Zivilisation stark beeinträchtigt." (Wikipedia)
:
Bearbeitet durch User
Frank E. schrieb: > Der theoretisch mögliche Kompressionserfolg für einen Bitstrom lässt > sich doch m.E. ausrechenen (Entropie usw.), unabhängig davon, ob man > einen Algorithmus hat, der das auch erreicht. Hab mal im Studium in ner Übungsstunde gemacht. Also komprimierte Datei genohmen, Histogramm über die Symbole gemacht und geschaut wie zufällig das ist. Kann man auch mit den üblichen Statistitools (Erwartungswert, Varianz) machen. Das war nicht weit weg vom Optimum (zufällig verteilt) in der Blockgröße ca. 1% vom Optimum - und das vor ca 30 Jahren mit Algos die mindestens doppelt so alt waren. Nachher mischt man sowieso wie Redundanz zur Fehlererkennung und Protokolldaten dazu. Deshalb bringt ja verlustlose Komprimierung nicht so viele bei Streams. Besser man schneidet das Rauschen aus dem Original, indem man beispielsweise statt 24bit RGB-Farbtiefe 10bit Grauwert nimmt (reicht für Kontourextraktion völlig) - ist auch nicht wirklich ein Informationsverlust, da letzlich Rauschunterdrückung in den lsb.
Es gibt eben verschiedene verschiedene Anwendungen von verlustfrei. Die Eine ist Multipass und die Andere ist Singlepass. Multipass bringt eine hoehere Kompression, weil sie erst drueber gehen kann und eine Statistik der Zeicher aufstellen kann, bevor die Erstellung kommt. Das andere ist Singlepass, wo man schlicht die Zeit nicht hat, weil man zB in einem Streaming Mode ist. Bedeutet man senden muss, bevor man das Ende hat. In diesem Fall muss man sich eh ueberlegen wie man einen Retry machen soll. Ueber welche Blockgroesse, und ob nicht allenfalls eine Feedforward Correction geeigneter ist, oder eine Kombination von Blockgroessen und Forward Correction. Aber das gabs ja alles schon zur Zeit der DSL Modems.
Rolf M. schrieb: > Und wie viele Stellen braucht der Index, um die Position jeder > erdenklichen Telefonnummer (oder von mir aus auch nur jeder erdenklichen > 7-stelligen Nummer) darstellen zu können? Das wäre doch mal eine schöne > Aufgabe für einen Mathematiker. Zumal man ja nicht bei der ersten Stelle von Pi anfangen muss. Wenn es für die zu bearbeitende Datenmenge günstiger ist, kann man ja auch bei Position x beginnen und von da die Adressierungen relativ zu x vornehmen. Darüber hinaus kann man auch auf andere Naturkonstanten zurückgreifen. Oder: gibt es eine ("künstliche") Zahlenfolge, die besonders gut für diese Art von Datenkompression geeignet ist? Fpgakuechle K. schrieb: > Tolle Komprimierung :-( ; statt den ca 24 bit der Telefonnummer > übermittelt man 19bit der Position innerhalb der Tranzendenten Konstante > plus einen Algorithmus zu deren Ermittlung ... Wenn der Algo bekannt ist, was meistens der Fall sein dürfte, hat man 5 bit gespart. Lem ist cool! :)
Fpgakuechle K. schrieb: >>Meine siebenstellige Telefonnummer findet sich bei Pi z.B. ungefähr bei >>der 300000sten Stelle (kann man online ausprobieren). > > Tolle Komprimierung :-( Irgendwo in der Zahlenfolge von Pi findet sich auch Goethes Faust, und da lohnt sich das schon eher - besonders wenn man extrem grosse Zahlen in einer Darstellung wie 10 hoch x hoch y hoch z -a schreiben kann. Man muss diese Darstellung bloss finden... Es gibt auch eine SF-Story, wo mit einer solchen Zahl der Inhalt einer Enzyklopädie an ein interstellares Raumschiff übertragen wird, heisst in der Story Gödelisierung. Georg
Literarisch auch: https://de.wikipedia.org/wiki/Die_Bibliothek_von_Babel Musst nur übertragen, wo es steht.
:
Bearbeitet durch User
Fpgakuechle K. schrieb: >> Tolle Komprimierung :-( ; statt den ca 24 bit der Telefonnummer >> übermittelt man 19bit der Position innerhalb der Tranzendenten Konstante >> plus einen Algorithmus zu deren Ermittlung ... >Wenn der Algo bekannt ist, was meistens der Fall sein dürfte, hat man 5 >bit gespart. Nein hat man nicht, weil man die Endposition der Nachricht nicht mitgeteilt hat. Kennt man, wieviel Stellen die Telefonnummer hat? Statt der Ensposition könnte man auch die Länge der Information im π-Stream mitteilen, aber dann braucht es auch noch eine Vereinbarung, wie man die beiden Infos - Länge und Startposition - voneinander trennt (bspw. Komma-Symbol). Also dieses 'Rumgemache mit Transzendenten Zahlen' ist IMHO weniger Komprimierung als Verschlüsselung, wobei π der Schlüssel ist. Das hat man schon in den Zwanziger genacht, nur übermittelte man nicht die Position innerhalb von π sondern innerhalb eines vereinbarten Buches: https://de.wikipedia.org/wiki/Buch-Verschl%C3%BCsselung -- > Es gibt auch eine SF-Story, wo mit einer solchen Zahl der Inhalt einer > Enzyklopädie an ein interstellares Raumschiff übertragen wird, heisst in > der Story Gödelisierung. 'Gödelisierung' ist eigentlich ein (Beweis-)Verfahren, um zu zeigen, das es keine widerspruchsfreie Axiomssysteme geben kann, wenn die Komplexität des benutzen (Zahlen-)Systems zu gering ist. Geht zurück auf den Mathematiker Kurt Gödel (1906-1978). Empfehlenswerte Bücher dazu ISBN:978-3608949063 und ISBN: 978-3492048842
johann schrieb: > Oder: gibt es eine ("künstliche") Zahlenfolge, die besonders gut für > diese Art von Datenkompression geeignet ist? Ich tippe da mal auf den goldenen Schnitt.
Molch schrieb: >> Oder: gibt es eine ("künstliche") Zahlenfolge, die besonders gut für >> diese Art von Datenkompression geeignet ist? > > Ich tippe da mal auf den goldenen Schnitt. Einfach so?
Solche Tricks funktionieren natürlich nicht. Die Informationstheorie ist da unerbittlich, so wie die Thermodynamik das Perpetuum Mobile verhindert. Selbst wenn in Pi an Stelle eins Goethe’s Faust beginnen würde, dann kann man mit einem Bit nur die Information übertragen “Nachricht ist Faust”/“Nachricht ist nicht Faust”, d.h. der Informationsgehalt ist ein Bit.
Andreas schrieb: > Die Informationstheorie ist > da unerbittlich Ist sie nicht - sie berücksichtigt nämlich nicht, dass die Information in einem gemeinsamen "Geheimnis" enthalten sein kann, in diesem Fall der Ziffernfolge von Pi, die jede Intelligenz im Universum kennen sollte. Diese Information muss also nicht übermittelt werden, sie ist ja beim Sender und beim Empfänger vorhanden. Eine andere Möglichkeit wäre die Übermittlung von Seitenzahl und Wortposition in einem Buch das beide haben, wird praktisch genutzt, ev. mit speziellen code books. Eine milliardenfach genutzte Möglichkeit der Umgehung der "unerbittlichen" Gesetze sind Links - ich sende dir eine URL zu einem von mir veröffentlichten Foto und mit den paar Bytes erhältst du Megabytes an Daten. Auch wenn sich der alte Shannon im Grab umdreht. Das wird er aber nicht tun, denn er weiss natürlich, dass solche Gesetze nur unter bestimmten Voraussetzungen anwendbar sind. Man kann die Zahl 265252859812191058636308480000000 übermitteln, unter Mathematikern genügt aber auch 30! - was ist da jetzt der Informationsgehalt? Die Zahlentheorie bietet unendliche Möglichkeiten extrem grosse Zahlen durch viel kürzere Formeln zu definieren. Goethes Faust ist auch nur eine sehr sehr grosse Zahl. Georg
Georg schrieb: > Andreas schrieb: >> Die Informationstheorie ist >> da unerbittlich > > Ist sie nicht - sie berücksichtigt nämlich nicht, dass die Information > in einem gemeinsamen "Geheimnis" enthalten sein kann, in diesem Fall der > Ziffernfolge von Pi, die jede Intelligenz im Universum kennen sollte. > Diese Information muss also nicht übermittelt werden, sie ist ja beim > Sender und beim Empfänger vorhanden. Das Problem ist aber, dass die Information in einem unendlich großen Buch steht und ich jetzt Seite, Zeile, Wort und Buchstabe, an dem die gewünschte Information steht sowie deren Länge übertragen muss. Und ich kann nicht steuern, wo in dem Buch welche Information steht. Kann z.B. gut sein, dass Faust irgendwo an ca. der 10^300000000sten Stelle zu finden ist (also nur mit einer 300 Millionen Stellen großen Zahl beschrieben werden kann), kann aber auch sein, dass es noch viiiiel weiter hinten ist. > Eine andere Möglichkeit wäre die Übermittlung von Seitenzahl und > Wortposition in einem Buch das beide haben, wird praktisch genutzt, ev. > mit speziellen code books. Klar geht das, aber zur Kompression allgemeiner Daten geht das auch nicht. Ein Wort, das dem Buch nicht vorkommt, kann man nicht beschreiben. Deshalb machen übliche Komprimieralgorithmen es ja so, dass sie das Buch selbst schreiben und dann mit übertragen. > Eine milliardenfach genutzte Möglichkeit der Umgehung der > "unerbittlichen" Gesetze sind Links - ich sende dir eine URL zu einem > von mir veröffentlichten Foto und mit den paar Bytes erhältst du > Megabytes an Daten. Damit überträgst du aber nicht das Bild. Das musst du schon vorher auf einen Server übertragen haben. Und von dem muss es auch noch zum Empfänger übertragen werden. > Auch wenn sich der alte Shannon im Grab umdreht. Dem Shannon ist das egal, weil du hier nicht das Bild, sondern eine ganz andere Information überträgst. Mit deine Methode könntest du Goethes Faust auf ein Bit komprimieren, das einfach die Information enthält, ob es sich um Goethes Faust handelt oder nicht. Wenn man das Buch dann vorliegen hat, hat man ja den kompletten Text. Ist aber wenig sinnvoll. > Man kann die Zahl 265252859812191058636308480000000 übermitteln, unter > Mathematikern genügt aber auch 30! Ja, ganz bestimmte Zahlen kann man so reduzieren, aber nicht pauschal alle. Du hast dir jetzt eine ganz besonders geschickte rausgesucht. Wenn du jede beliebige Zahl im Bereich z.B. zwischen 0 und 10^50 wählen willst, musst du auch die Information übertragen, die es ermöglicht, zwischen 10^50 verschiedenen Werten unterscheiden zu können. > Die Zahlentheorie bietet unendliche Möglichkeiten extrem grosse Zahlen > durch viel kürzere Formeln zu definieren. Aber auch hier wieder nur ganz bestimmte, nicht jede beliebige. > Goethes Faust ist auch nur eine sehr sehr grosse Zahl. Aber die Zahl, die angibt, wo es in PI zu finden ist, kann durchaus noch viel größer sein.
:
Bearbeitet durch User
Rolf M. schrieb: > Aber die Zahl, die angibt, wo es in PI zu finden ist, kann durchaus noch > viel größer sein. Wenn eine dem Pointer entsprechende Zahl vorher kommt, kann man "Pointer auf Pointer @ x, Länge y" senden.
Jens M. schrieb: > Rolf M. schrieb: >> Aber die Zahl, die angibt, wo es in PI zu finden ist, kann durchaus noch >> viel größer sein. > > Wenn eine dem Pointer entsprechende Zahl vorher kommt, kann man "Pointer > auf Pointer @ x, Länge y" senden. Wenn hilft nicht, wenn wenn nicht zutrifft ...
Rein nachrichtentheoretisch können Kompressionsverfahren nur die Redundanz der jeweiligen Information herausrechnen. Viel mehr ist da wohl nicht drin?
Elektrofan schrieb: > Rein nachrichtentheoretisch können Kompressionsverfahren nur die > Redundanz der jeweiligen Information herausrechnen. Im Prinzip ja, wobei dafür die gesamte Information zählt, einschliesslich der beim Empfänger bereits vorhandenen Information. Es hängt also auch vom verwendeten Code ab: Wenn man davon ausgeht, dass der Empfänger kein mathematischer Laie ist, reicht die Übertragung des Zeichens π an Stelle der für ihn erforderlichen Stellen aus.
:
Bearbeitet durch User
Elektrofan schrieb: > Viel mehr ist da wohl nicht drin? Doch, aber dann kommt man in den Bereich der verlustbehafteten Verfahren, weil man Information weglässt, die man als mehr oder weniger irrelevant ansieht. Wie bei Bild/Ton-Übertragung.
:
Bearbeitet durch User
Elektrofan schrieb: > Viel mehr ist da wohl nicht drin? Lustigerweise kommen auch heute Kompressionsalgorithmen für "normalen" englischen Text nicht wirklich unter die ca. 0,6 … 1,3 Bit/Buchstabe, die schon 1950 vorhergesagt wurden.
Ist doch gut! ASCII codiert jeden Buchstaben stumpf mit 8 bit. Egal, ob es das häufige "e" ist oder das kaum benutzte Paragraphen-Zeichen "§".
Εrnst B. schrieb: > Lustigerweise kommen auch heute Kompressionsalgorithmen für "normalen" > englischen Text nicht wirklich unter die ca. 0,6 … 1,3 Bit/Buchstabe, > die schon 1950 vorhergesagt wurden. Wobei der Claude von 27 Symbolen ausgeht (26 Buchstaben und Leerzeichen) und damit Großbuchstaben und Interpunktionen ignoriert. OK - für englische Texte liegt er damit nicht sonderlich falsch. Der Teutone vermisst dann aber schon einiges: A:Z,öüäß!?=€;-) und hier im Forum hat man auch gern µC .
cerebrum donatore schrieb: > Wobei der Claude von 27 Symbolen ausgeht (26 Buchstaben und Leerzeichen) Also ungefähr dem, was Schlüsselmaschinen wie die Enigma boten. Ziffern wurden als Worte geschrieben und auf Satzzeichen wurde verzichtet.
cerebrum donatore schrieb: > Εrnst B. schrieb: >> Lustigerweise kommen auch heute Kompressionsalgorithmen für "normalen" >> englischen Text nicht wirklich unter die ca. 0,6 … 1,3 Bit/Buchstabe, >> die schon 1950 vorhergesagt wurden. > > Wobei der Claude von 27 Symbolen ausgeht (26 Buchstaben und Leerzeichen) > und damit Großbuchstaben und Interpunktionen ignoriert. OK - für > englische Texte liegt er damit nicht sonderlich falsch. Der Teutone > vermisst dann aber schon einiges: A:Z,öüäß!?=€;-) und hier im Forum hat > man auch gern µC . Dann überleg dir mal was das für Auswirkungen hat. Man könnte denken, dass sich mit Groß- und Kleinschreibung die Anzahl der benötigten Bits verdoppelt. Aber nicht jeder Buchstabe in einem Text darf groß geschrieben werden. Es ist immer der erste Buchstabe in einem Wort. Gehen wir davon aus, dass es keine Interpunktion gibt, dann steht vor den ersten Buchstaben eines Worts ein Leerzeichen. Wir brauchen also nur zwei verschiedene Leerzeichen, um Groß- und Kleinschreibung zu codieren. Bei einer mittleren Wortlänge von 6 Buchstaben (laut Duden) bzw. 7, wenn man das Leerzeichen mitzählt, ändert sich nicht so viel an den benötigten Bits/Buchstabe.
(prx) A. K. schrieb: > cerebrum donatore schrieb: >> Wobei der Claude von 27 Symbolen ausgeht (26 Buchstaben und Leerzeichen) > > Also ungefähr dem, was Schlüsselmaschinen wie die Enigma boten. Wahrscheinlich bezug sich Claude bei der Alphabetauswahl nicht auf die Teutonische Enigma sondern auf das International Telegraph Alphabet 2 von 1924 mit 5 bit: https://en.wikipedia.org/wiki/Baudot_code#ITA2
mh schrieb: > Es ist immer der erste Buchstabe in einem Wort. Nö, ich sag nur UK oder Elizabeth II . Real wird es wohl so gemacht das man lediglich ein Zeichen für die Umschaltung in den Zweiten Zeichensatz definiert. Eben die Shift-Taste oder Typenhebel - so was hatte schon eine Schreibmaschine von Anno Tobak: https://img.fotocommunity.com/schreibmaschine-typenhebel-b1df9511-3961-477c-9f0a-b7d7675f27f2.jpg?height=1080 https://www.typewriters.ch/wp-content/uploads/Brauner_Lexikon_169-Kopie.jpg
{kind=link}
{kind=link}
mh schrieb: > Man könnte denken, > dass sich mit Groß- und Kleinschreibung die Anzahl der benötigten Bits > verdoppelt. Nein, es reichen 5 Bits: https://de.wikipedia.org/wiki/Baudot-Code Bei Varicode sollen es im Durchschnitt nur 6 bis 7 bit sein, mit denen sich ASCII-7 abbilden lässt: http://bipt106.bi.ehu.es/psk31theory.html Also gerade mal 14% Einsparung. Was mich im Nachhinein wundert ist, dass für die Entwicklung englischsprachiger Klartext verwendet wurde, statt amateurfunktypischem Text. Ich hätte*) mir zunächst eine Statistik über die weltweit zugeteilten Rufzeichen erstellt aus dem Callbook. Damit hat man schon mal die Verteilung der Großbuchstaben A-Z und Ziffern 0-9. "K, W, N, A"-Calls sind nämlich häufiger vertreten, als z.B. "3Y0J" Dann eine Statistik über typischen Amateurfunkverkehr. "CQ CQ CQ de" kommt eben häufiger vor als irgendwelcher Klartext. Die meisten QSOs werden ja eh aus Makros abgespult, obwohl man bei PSK31 eigentlich noch ganz gut in Echtzeit chatten konnte. Damit ließen sich bestimmt noch ein paar Bits einsparen. *) Ich bin natürlich auch der welt-beste Autofahrer und Bundestrainer ;-)
Marek N. schrieb: > Nein, es reichen 5 Bits: https://de.wikipedia.org/wiki/Baudot-Code Dann ist es allerdings keine verlustfreie Komprimierung mehr.
cerebrum donatore schrieb: > mh schrieb: >> Es ist immer der erste Buchstabe in einem Wort. > > Nö, ich sag nur UK oder Elizabeth II . Und wieviel machen diese Sonderfälle in einem echten Text aus? > Real wird es wohl so gemacht das man lediglich ein Zeichen für die > Umschaltung in den Zweiten Zeichensatz definiert. Möglich, aber im Mittel vermutlich etwas teurer. Marek N. schrieb: > mh schrieb: >> Man könnte denken, >> dass sich mit Groß- und Kleinschreibung die Anzahl der benötigten Bits >> verdoppelt. > > Nein, es reichen 5 Bits: https://de.wikipedia.org/wiki/Baudot-Code Ich glaube wir reden über unterschiedliche Dinge.
cerebrum donatore schrieb: > Real wird es wohl so gemacht das man lediglich ein Zeichen für die > Umschaltung in den Zweiten Zeichensatz definiert. So ist es. Es wird ein Zustandsautomat realisiert, mit durch das (gelegentliche) Senden eines Umschaltsymbols (5 Bit) weitere 31 Zeichen erschließt. Das ganze macht natürlich nur Sinn, wenn nicht zu oft umgeschaltet werden muss. Der Worst-Case wäre, wenn ständig Groß- und Kleinschreibung im Wechsel gesendet werden würde, weil dann immer 10 Bit pro Symbol gesendet werden müssten, obwohl man eigentlich wieder mit den 6 Bit auskäme, um alle 63 Symbole zu codieren. Hinzu kommt die Synchronisationsproblematik, wenn z.B. das Umschaltsymol bei der (Funk-)Übertragung verloren geht. Sieht man z.b. bei RTTY, wenn statt der Buchstaben reihenweise Ziffern oder Sonderzeichen kommen. Eigentlich müsste man eine zweite State-Machine kreieren im Sender und Empfänger, die quasi ein "Stuffing" macht und regelmäßig Umschaltsymbole nachsendet zur Synchronisation und bei einem verlorenen Umschaltsymbol nach garantiert N Symbolen wieder autmatisch zurückschaltet. Hm... ich glaube, von da an ist es nicht mehr weit zur Trellis-Codierung und Viterbi-Decoder... Schon ein spannendes Thema!
Warum soll Baudot nicht verlustfrei sein? Abgesehen von der o.g. Synchronisationsproblematik. kopfkratz
Marek N. schrieb: > Warum soll Baudot nicht verlustfrei sein? Abgesehen von der o.g. > Synchronisationsproblematik. *kopfkratz* Bei "Marek N" => "MAREK N" geht m.E. schon etwas verloren.
:
Bearbeitet durch User
mh schrieb: > cerebrum donatore schrieb: >> mh schrieb: >>> Es ist immer der erste Buchstabe in einem Wort. >> >> Nö, ich sag nur UK oder Elizabeth II . > Und wieviel machen diese Sonderfälle in einem echten Text aus? Unnötige Frage, bereits ein fehlendes Satzzeichen kann zwischen leben und tod entscheiben. Beispiel: "haengen nicht laufen lassen". Häufige vorkommende Grossbuchstabensequenzen: GMT, ETA, USD, ASAP, COVID, WWII, BC, AM, PM, AC, DC, HIV, AIDS, VAT, ...
cerebrum donatore schrieb: > Unnötige Frage, bereits ein fehlendes Satzzeichen kann zwischen leben > und tod entscheiben. Beispiel: "haengen nicht laufen lassen". Ok wir reden auch über unterschiedliche Dinge.
(prx) A. K. schrieb: >> Warum soll Baudot nicht verlustfrei sein? Abgesehen von der o.g. >> Synchronisationsproblematik. *kopfkratz* > > Bei "Marek N" => "MAREK N" geht m.E. schon etwas verloren. Auch ein schönes Beispiel, wie durch Verlust von Klein/Grossschreibung entscheidende Information verloren gehen kann: HELFT DEN ARMEN VÖGELN
:
Bearbeitet durch User
(prx) A. K. schrieb: > Auch ein schönes Beispiel, wie dadurch entscheidende Information > verloren gehen kann, ist: > HELFT DEN ARMEN VÖGELN Das sind zuviele Informationen! Ich will nicht wissen was du mit deinen Armen machst!
Marek N. schrieb: > Ist doch gut! > ASCII codiert jeden Buchstaben stumpf mit 8 bit. 7 Bit. > Egal, ob es das häufige "e" ist oder das kaum benutzte > Paragraphen-Zeichen "§". "§" gibt es in ASCII gar nicht. johann schrieb: > Rolf M. schrieb: >> Und wie viele Stellen braucht der Index, um die Position jeder >> erdenklichen Telefonnummer (oder von mir aus auch nur jeder erdenklichen >> 7-stelligen Nummer) darstellen zu können? Das wäre doch mal eine schöne >> Aufgabe für einen Mathematiker. > > Zumal man ja nicht bei der ersten Stelle von Pi anfangen muss. Wenn es > für die zu bearbeitende Datenmenge günstiger ist, kann man ja auch bei > Position x beginnen und von da die Adressierungen relativ zu x > vornehmen. Ja, "wenn". Wenn das Wörtchen "wenn" nicht wär, dann wär ich jetzt Millionär. Auch hier der selbe Punkt: Für bestimmte Werte mag das passend sein, für andere dafür umso schlechter. Deine Idee würde nur funktionieren, wenn alle Sachen, die du komprimieren willst, innerhalb von PI zufällig nah bei einander liegen. Dass aber Faust und die Bibel in PI direkt hintereinander kommen, ist eher unwahrscheinlich. > Darüber hinaus kann man auch auf andere Naturkonstanten zurückgreifen. Die ändern an der Grundproblematik aber nichts. > Oder: gibt es eine ("künstliche") Zahlenfolge, die besonders gut für > diese Art von Datenkompression geeignet ist? Nein, denn auch das ändert nichts daran. Es funktioniert nur, wenn du erhebliche Einschränkungen bezüglich dessen, was du komprimieren willst, hinnimmst.
:
Bearbeitet durch User
(prx) A. K. schrieb: > Elektrofan schrieb: >> Rein nachrichtentheoretisch können Kompressionsverfahren nur die >> Redundanz der jeweiligen Information herausrechnen. > > Im Prinzip ja, wobei dafür die gesamte Information zählt, > einschliesslich der beim Empfänger bereits vorhandenen Information "nachrichtentheoretisch" (Shannon-Theorem) geht es darum, wieviel Information über eine Leitung übertragen werden kann. Folglich sind Informationen, die der Empfänger bereits hat, völlig irrelevant. Georg
Georg schrieb: > (prx) A. K. schrieb: >> Elektrofan schrieb: >>> Rein nachrichtentheoretisch können Kompressionsverfahren nur die >>> Redundanz der jeweiligen Information herausrechnen. >> >> Im Prinzip ja, wobei dafür die gesamte Information zählt, >> einschliesslich der beim Empfänger bereits vorhandenen Information > > "nachrichtentheoretisch" (Shannon-Theorem) geht es darum, wieviel > Information über eine Leitung übertragen werden kann. Folglich sind > Informationen, die der Empfänger bereits hat, völlig irrelevant. > > Georg "Nachrichtentheoretisch" ist also mit einem "Shannon-Theorem" gleichzusetzen? Was genau meinst du mit "Shannon-Theorem"? Die Information ist bei der Übertragung wohl verloren gegangen. Das Internet ist heute ziemlich verrauscht ...
mh schrieb: > "Nachrichtentheoretisch" ist also mit einem "Shannon-Theorem" > gleichzusetzen? Was genau meinst du mit "Shannon-Theorem"? Das Internet > ist heute ziemlich verrauscht ... Sorry, aber wenn das Internet deine eizige Informationsquelle ist, biste bei dieser Diskussion etwas falsch. Um über Claude's Arbeiten mitreden zu können, wäre es schon gut im Studium oder während anderer höherer Ausbildung damit in Kontakt gekommen zu sein. Wenigstens so etwas Halbgares wie "Shannon hat bewiesen, das man auch bei maximal verrauschten Kanälen Information übertragen kann solange die bandbreite passt", sollte man wissen. Nach aktueller Wikipedia-Nomenklature heisst das wohl: https://de.wikipedia.org/wiki/Shannon-Hartley-Gesetz Da eine Kurzfassung für Codierschweine: https://www.itwissen.info/Shannon-Theorem-shannon-theorem.html
Beitrag #6744687 wurde von einem Moderator gelöscht.
Beitrag #6744693 wurde von einem Moderator gelöscht.
Beitrag #6744704 wurde von einem Moderator gelöscht.
Rückwärts gerichtete Überlegungen sind eigentlich auch ganz nett (abgesehen davon, dass die Arbeiten von Shannon (oder anderen..) immer noch Leuchturm-Charakter haben) - beispielsweise hatte das TX16W Betriebsystem "Typhoon" von NuEdge http://nuedge.net/typhoon2000/WhatIsTyphoon.htm " Audio file compression to save time and space (30 to 60% savings) " im Angebot, Kawai R-50 https://www.youtube.com/watch?v=m4Sqyvom2vo (Videobeschreibung lesen) und andere Geräte wohl eher nicht. In vielen Musikstudios/Musikschulen sammeln sich vermutlich mehrere solcher nicht mehr ordentlich funktionierenden Gerätschaften, weshalb sich möglicherweise eine Nachfrage nach einem willigen Pimp-Testobjekt durchaus lohnen könnte. ;)
PAQ ist ein Kompressionsalgorithmus der mit viel Speicher und Rechenzeit deutlich mehr Reduktion als die gängigen Verfahren erreicht: https://en.wikipedia.org/wiki/PAQ Zur Frage ob sich Daten noch weiter komprimieren lassen ist es hilfreich das Konzept der Kolmogorov-Komplexität verstanden zu haben.
Martin S. schrieb: > Zur Frage ob sich Daten noch weiter komprimieren lassen ist es hilfreich > das Konzept der Kolmogorov-Komplexität verstanden zu haben. Wikizitat: .."ist ein Maß für die Strukturiertheit einer Zeichenkette.." Problem: sieht möglicherweise KI-Algo1 etwas anderes als KI-Algo2. Besser, bzw. hat sich in der Vergangenheit bewährt: Wahrscheinlichkeitsrechnungen und Testtheorie: Zufall, oder nicht Zufall? ..weswegen es gut ist, Shannon nochmal zu lesen ;) Ein zweiter, in diesem Zusammenhang wichtiger Punkt ist die Verschlüsselung. Wieviel Verschlüsselung/Sicherheit/Passwortkomplexität usw. kann ich mir im Alltag erlauben? Und wenn man schon dabei ist, .."if the hunger stays the night" ..kann man sich noch ein paar Gedanken machen, welcher Aufwand tatsächlich nötig ist, um z.B. Erinnerung oder Konservierung - oder einfach mur mal etwas Ordnung/Wiederholung - zu schaffen. Ist leider kein Allgemeinwissen (!): https://de.wikipedia.org/wiki/Malen_nach_Zahlen
Beitrag #6751820 wurde von einem Moderator gelöscht.
Fun fact: Man weiß gar nicht, ob in Pi alle möglichen Ziffernfolgen vorkommen. Diese Eigenschaft einer Zahl nennt sich Normalität und man weiß nicht, ob Pi normal ist. Man vermutet das nur. https://de.wikipedia.org/wiki/Normale_Zahl#Kreiszahl_%CF%80 Dazu kommt noch das Problem, dass der Index ja kleiner als die zu suchende Ziffernfolge sein muss, sonst hat man ja nichts gespart. Laut diesem Artikel https://www.angio.net/pi/whynotpi.html kommen aber 1/3 der 8-stelligen Zahlen nicht in den ersten 100 Millionen Stellen von Pi vor, d.h. der Index hat mehr als 8 Stellen. Dass der Index größer als die zu komprimierende Zahl ist, ist also keine seltene Ausnahme, sondern kommt sehr häufig vor.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.