Hi
Ich möchte aus einer Datei nur die Dateien heruasfiltern, die
alphanumerische Zeichen und Klammern enthalten. Ich verwende dazu
folgendes:
awk '/^[@ABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz1234567890]*$/ { print }' input.txt
>output.txt
hier fehlen natürlich noch die Klammern (Runde, eckige und geschwungene)
Die muss ich jedeoch escapen. Ich hab für jede Klammer folgendes
versucht \\{\\
Dies hat aber nicht geklappt. Kann hier jemand helfen?
PapaSchlumpf schrieb: > hier fehlen natürlich noch die Klammern (Runde, eckige und geschwungene) > Die muss ich jedeoch escapen. Ich hab für jede Klammer folgendes > versucht \\{\\ > Dies hat aber nicht geklappt. Kann hier jemand helfen? Warum escapest du zweimal? Ich würde das nur einmal machen.
Angehängte Dateien:
-

awk.png
98 KB
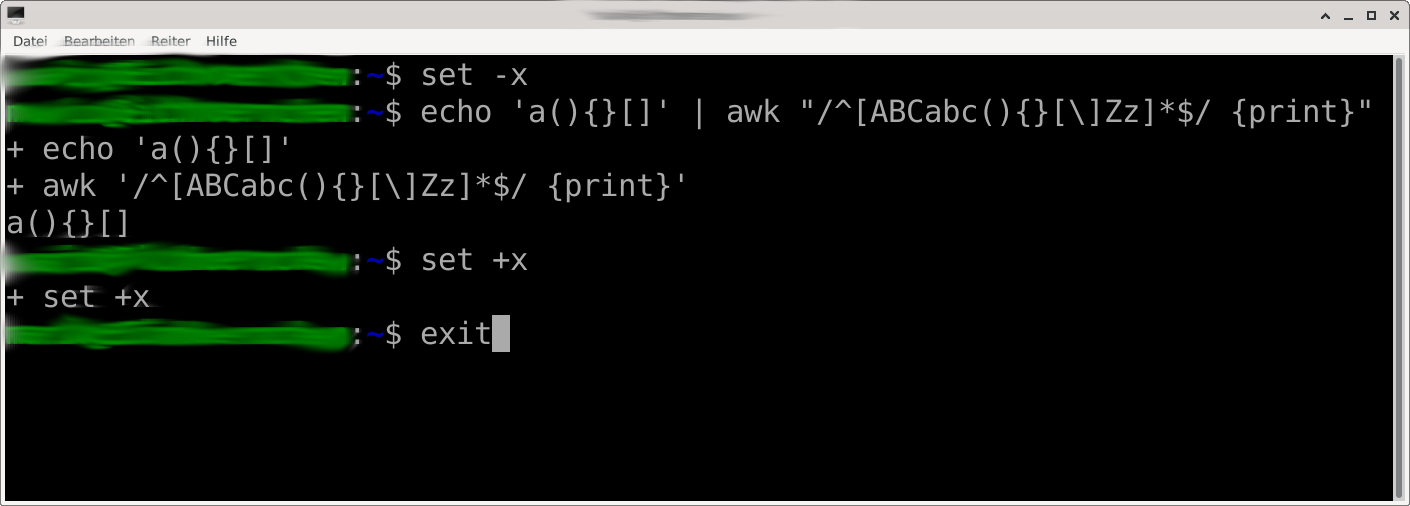
Ich nutze GNU awk 5.1.0. Da muß ich nut die schließende eckige Klammer mit einem einfachen Backslash schützen. Das 'set -x' schaltet die Anzeige der Shell-Expansion ein. Dadurch entstehen die Zeilen, die mit einem '+' beginnen und ich kann recht schnell erkennen, wie der letztlich ausgeführte Befehl nach der Shellexpansion aussieht. Ist ein Hilfsmittel.
Nur Maedchen packen sowas in Apostrophe. Richtige Maenner escapen einfach die Zeichen, die die Shell nicht interpetieren soll. Meine persoenliche Bestleistung waren einmal: \\\\\\\\\\\\\\\\ fuer ein Shellkommando in einem mwm-Menue. Da haetten Apostrophe sowieso nicht verwendet werden duerfen. Auch sehr hilfreich zum Verstaendnis und dem richtigen Umgang mit Escapen und Quotieren, ist der Windowskommandointerpreter CMD.EXE mit seinen besonders abartigen Escapemechanismen. Ansonsten: Frohen Sonntag und den Kirchbesuch nicht vergessen!
Gibt es bei awk keine Buchstaben - und Zahlengruppen [A-Za-z0-9]?
Bei meiner Programmiersprache geht das so :
"(~(|~{|~[)[A-Za-z0-9]{1,}(~)|~}|~])"
wobei die Tilde (~) das Escape einleitet und das |
die jeweiligen Alternativen (also bei dir die Klammerarten)
trennt.
Also ~ durch \ ersetzen. Zeichen für Alternativen bei dir
weiß ich jetzt nicht.
udok schrieb: > tut was anderes, je nach der current LOCALE Ja, ich hatte - so wie du - den Eindruck das er in Wirklichkeit alt-tibetanisch des dreizehnten Jahrhunderts parsen wollte. Ganz klar mein Fehler. Sorry.
ich bin immer noch am herumexpermimentieren mit awk wie schaffe ich es, dass im folgenden Beispiel:
1 | awk '/^[1234567890]*$/ { print }' <in.txt >out.txt
|
neben Zeilten die nur Nummern enthalten, auch folgende Zeichen berücksichtigt werden:
1 | - |
2 | ] |
3 | \ |
4 | ' |
Grundsätzlich kannst du alles ›escapen‹ was nicht bei drei auf den Bäumen ist. Das ist ganz sicher nicht ästhetisch ansprechend, aber es geht. Was nicht an erster Stelle hinter einer öffnenden eckigen Klammer stehen darf ist ›-‹. Das heißt dann nämlich ›nicht die folgenden…‹ und ist nicht das was du willst. Ich empfehle - wenn du's öfter brauchst - kostenlos in der shell verfügbar ›man regex‹, da lernt man eine Menge. Für die Windows Nutzer, kauft ein Buch ;-)
Norbert schrieb: > Was nicht an erster Stelle hinter einer öffnenden eckigen Klammer stehen > darf ist ›-‹. Das heißt dann nämlich ›nicht die folgenden…‹ und ist > nicht das was du willst. https://www.gnu.org/software/gawk/manual/html_node/Regexp-Operator-Details.html ‘[^awk]’ matches any character that is not an ‘a’, ‘w’, or ‘k’. > Ich empfehle - wenn du's öfter brauchst - kostenlos in der shell > verfügbar ›man regex‹, da lernt man eine Menge. $man regex No manual entry for regex crap ;) dürfte eher selten ab Werk dabei sein. 7: Overviews, conventions, and miscellaneous. https://man7.org/linux/man-pages/dir_section_7.html man gawk https://www.gnu.org/software/gawk/manual/html_node/GNU-Regexp-Operators.html hier im aktuellen Zusammenhang; https://www.gnu.org/software/gawk/manual/html_node/Bracket-Expressions.html To include one of the characters ‘\’, ‘]’, ‘-’, or ‘^’ in a bracket expression, put a ‘\’ in front of it.
folgendes hat nun geklappt:
1 | \] |
2 | \\ |
3 | '\'' |
das minus Zeichen musste ich ans ende der Liste stellen und klappt nun auch. noch eine letzte Frage. Ist es möglich mit awk zwei Dateien zu erzeugen, eine mit den Zeilen die der Abfrage entsprechen und eine zweite mit dem Rest?
Du kannst dem print-Befehl die Ausgabedatei mitgeben: mein Testcode als Einzeiler:
1 | mario@Wolke:~$ echo -e 'abc\nABC\n123' | awk '/^[A-Za-z]*$/ {print >"./match_grossklein.txt"}; /^[a-z]*$/ {print >"./match_klein.txt"; next}; /^[A-Z]*$/ {print >"./match_gross.txt"; next}; {print >"./rest.txt"}'
|
Das echo dient nur zur Bereitstellung der drei Testzeilen für das awk-Script. Das awk-Script nochmal aufgedröselt zur besseren Lesbarkeit; es kann so auch in eine awk-Scriptdatei geschrieben werden welche dem awk-Befehl über die Option -f übergeben wird; im Einzeiler zuvor sind diese Abschnitte durch jeweils ein Semikolon getrennt:
1 | /^[A-Za-z]*$/ {print >"./grossklein.txt"} #Zeile mit Buchstaben
|
2 | /^[a-z]*$/ {print >"./klein.txt"; next} #Zeile mit Kleinbuchstaben
|
3 | /^[A-Z]*$/ {print >"./gross.txt"; next} #Zeile mit Großbuchstaben
|
4 | {print >"./rest.txt"} #Zeile ohne Treffer zuvor
|
Ist eine Zeile in eine Zieldatei eingetragen, wird durch die 'next'-Anweisung die Bearbeitung der aktuellen Datenzeile beendet und zur nächsten übergegangen. Soll eine Zeile in mehrere Zieldateien eingetragen werden, darf die Bearbeitung der Datenzeile nicht mit 'next' beendet werden (#Zeile mit Buchstaben). So wird die Bearbeitung dieser Datenzeile mit den folgenden Mustern fortgesetzt und die dortigen Anweisungsblöcke werden ausgeführt .
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.