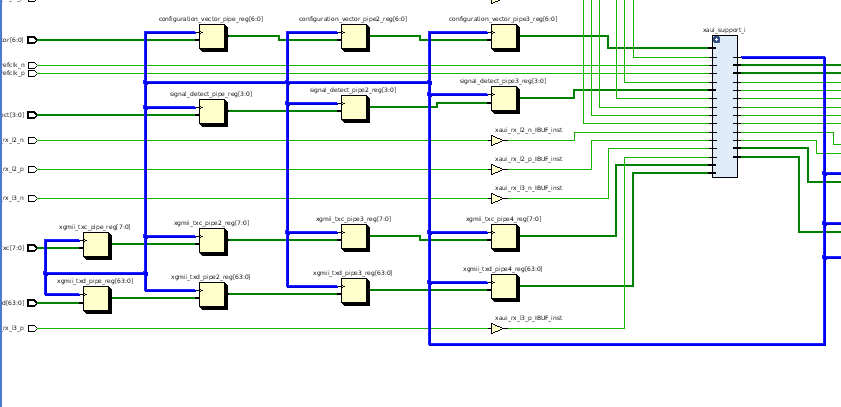
Hallo guten Tag, ich habe hier ein Design, wo man einem IP Core einen Konfigurationsvektor übergeben kann. Was ich seltsam finde ist, dass dort drei D FF davor sind. Warum wird das dem Baustein nicht direkt übermittelt xD
Angehängte Dateien:
-

fraghexaui.png
12 KB
So kann man Synthesetools, die Register Retiming beherrschen, erklären, dass es nix macht, wenn's schnell geht: die Tools können die "überzähligen" FF's im Timing-Pfad verschieben, um das Timing zu optimieren. Dafür hat man natürlich - wie immer beim Pipelining - zusätzliche Latenz.
{kind=link}
ist es für einen ersten Test wichtig, diese D-FFs dort zu lassen, oder könnte ich die für einen Testentwurf auch erst mal weglassen?
Sicher. Für die reine Logik sind die erst mal unerheblich (allerdings schaden sie auch nicht). Wenn Du hinterher aber doch Register Retiming brauchst, weil Du dein gesetztes Fmax nicht erreichst, dürfte es allerdings deutlich schwieriger und fehlerträchtiger sein, die Latency nachträglich ins Design reinzufummeln als sie gleich von Beginn an zu berücksichtigen. Ich nehme an, es gibt einen guten Grund, daß die da sind. Sagt die Core-Dokumentation nichts darüber? [edit: dein zuletzt gepostetes Bild zeigt, dass da auch weitere Signale direkt (ohne die Pipeline-FF's) in das Design reingehen. Der Umstand ist sicher im Core berücksichtigt. Du kannst die FF's also höchstwahrscheinlich doch nicht weglassen, ohne die Funktionalität zu (zer)stören.]
Markus F. schrieb: > Du kannst die FF's also > höchstwahrscheinlich doch nicht weglassen, ohne die Funktionalität zu > (zer)stören.] Vielen Dank^^ Ja ich finde es nur schwer einzuschätzen was die genau machen. Aber wenn es mindestens schaffe an bereits beschriebene Stellen solche FFs setzen zu lassen wäre das schon mal gut. Dann muss ich aber noch schauen ob an andere Stellen meines Entwurfs solche FFs eingesetzt werden müssen^^ So ist meine Vermutung.
Naja, ist halt eine undokumentiert Lösung für ein Problem, das nicht formuliert wurde (jedenfalls ist es nicht aus dem Eingangspost ersichtlich) Und das Gezeigte muss nicht die optimale Lösung sein. Wenn es nur um clk-verzögerung geht, hätt man das auch mit einen CE D-FF lösen können. Oder mit einem Shiftregister-Makro. Oder vielleicht soll einfach nur die STA ausgetrickst werden. Einsynchronisation wäre auch so eine Überlegung, aber das löst man für parallel Busse nicht auf diese Weise. Vielleicht wurde bei der Core-Generierung auch ein Haken/Parameter suboptimal gesetzt, mal 'Optimize for size statt for speed ausprobieren. Vielleicht hat es auch was mit Bustiming zu tun: damit der Bus schnell freigegeben wird, werden die daten busnah weggespeichert um in sfolgenden Takten zum Modul physisch 'fern' vom Bus, durchgereicht zu werden.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.