Moin,
Mein SPI-Master (STM32) pollt den Slave (ATmega128) alle 10ms und holt
jeweils ein 16 bytes langes Paket ab. Die andere Richtung wird nicht
benutzt, MOSI ist nur zu Testzwecken mit dem LogicAnalyser verbunden.
Die Verbindung an sich funktioniert: Der STM32 erzeugt CSN und SCK,
sendet auf MOSI die (hier nicht genutzten) bytes in seinem
SPI-Datenregister (alle Bytes == 0x03), und empfängt auf MISO die Bytes
vom AVR.
Nach jedem übertragenen Byte wird im AVR die InterruptServiceRoutine
getriggert. Ich schreibe darin jeweils das nächste Byte meines zu
übertragenden Arrays ins SPI-Datenregister SPDR und zähle meinen
Byte-Zähler hoch. Kurz nach jedem Paket (getriggert über Timer0) setze
ich außerhalb der ISR den Byte-Zähler zurück und schreibe das erste zu
übertragende Byte des nächsten Pakets ins SPDR.
Dieses erste Byte wird jedesmal korrekt übertragen, egal ob ich einen
festen Wert ins SPDR schreibe oder einen beliebigen Wert des Arrays fest
indexiere (z.B. spi_tx_bytes[13]). Bei den weiteren Bytes, die dann von
der ISR in SPDR geschrieben werden, habe ich aber einen komischen
Effekt: Wenn ich testweise den Byte-Zähler reinschreibe, wird dieser
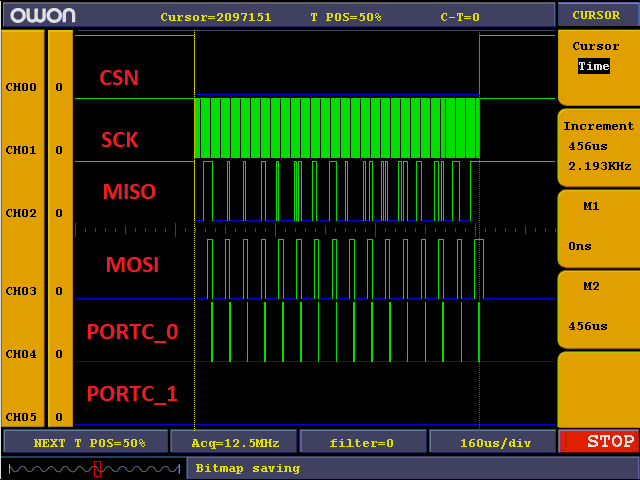
auch korrekt auf dem Bus ausgegeben, auf dem LogicAnalyser und im
Empfänger sehe ich dann also der Reihe nach die Werte von 0 bis 15
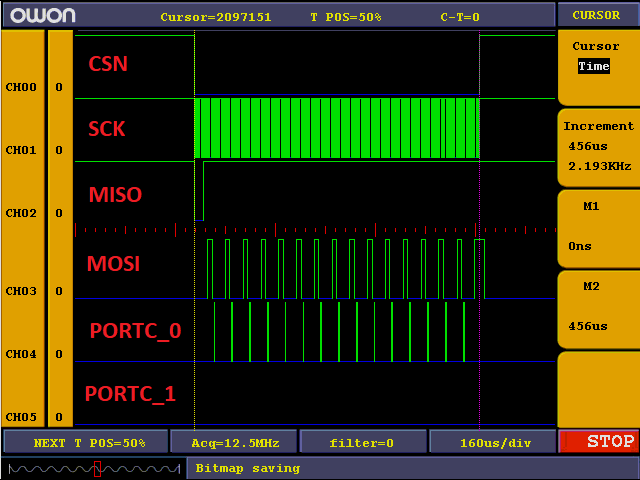
hochzählen (Bild 1). Wenn ich aber stattdessen über den besagten
Byte-Zähler einen Wert im Array indexiere, schreibt der AVR nichts auf
MISO, der Pegel bleibt für den Rest der vom Master abgefragten 16 bytes
auf high (Bild 2).
Folgende Ansätze habe ich bisher untersucht:
1) Der Effekt tritt identisch auf, wenn ich den ATm128 durch einen ATm48
ersetze (jeweils mit 20MHz Taktrate).
2) Wenn ich statt des "Arrays mit Byte-Zähler als Index" einen
"Struct-Pointer mit Byte-Zähler als Offset" benutze, tritt der Effekt
identisch auf -> Nach dem ersten Byte kommt kein weiteres durch.
3) Der Effekt ist unabhängig von der eingestellten Bit-Rate des
SPI-Busses. Aktuell benutze ich die langsamste Einstellung (im Master,
also im STM32), die weit unter der maximalen Geschwindigkeit liegt, die
der AVR laut Datenblatt kann.
4) Wenn ich den ISP-Programmierstecker des AVR (nutzt ebenfalls dessen
SPI) abziehe, bleibt der Effekt gleich, nur der MISO-Ruhepegel zwischen
den SPI-Paketen ist dann low (statt high wenn ich den Stecker drauf
lasse).
5) Wenn ich in der ISR als Index für das Array nicht den Byte-Zähler
benutze, sondern einen festen Wert zwischen 0 und 15, dann wird der
entsprechende Wert aus dem Array korrekt übertragen (dann halt 16
mal...).
Kann jemand diesen Effekt erklären, hat jemand ähnliches schonmal
gesehen oder hat jemand Ideen, was ich noch probieren könnte?
Besten Dank, Nils
So sieht der Code zu Bild 1 aus, der einzige Unterschied zwischen den
beiden Screenshots ist in Zeile 17:
1
// ATmega1284P as SPI slave; 20MHz; sending only counter variable
Nils schrieb:> Aktuell benutze ich die langsamste Einstellung
Und die da wäre?
Der AVR hat nur 0,5 SPI-Takt Zeit, in den Interrupt zu springen, seine
Register zu retten und den neuen Wert zu laden, da ungepuffert.
Der Master sollte also nach jedem Byte eine Wartepause einlegen, z.B.
per Timerinterrupt.
Die SPI-Frequenz ist 284 kHz.
D.h. ein Takt auf SCK dauert ungefähr 3.5 µs, während beim AVR ein Takt
0.05 µs lang ist (F_CPU==20 MHz). Dazwischen liegt ein Faktor von
ungefähr 70 (bzw. 35 wegen der "0.5 SPI-Takte" aus dem AVR-Datenblatt).
Ich hätte gedacht, daß die ISR schneller ist, bin ich da zu
optimistisch?
Nils schrieb:> Ich hätte gedacht, daß die ISR schneller ist, bin ich da zu> optimistisch?
Dein Code ist schlecht. Volatile schaltet die Optimierungen aus und
Division in der ISR ist ein ganz böses Foul.
Peter D. schrieb:> Dein Code ist schlecht. Volatile schaltet die Optimierungen aus und> Division in der ISR ist ein ganz böses Foul.
Das kommt davon wenn ein Programmierer einfach alles von der
Hardware fordert was er braucht ohne Rücksicht zu nehmen was
man ihr abverlangen kann. Das Verhalten muss wohl aus der
Java-Ecke stammen .....
Peter D. schrieb:> Nils schrieb:>>> Ich hätte gedacht, daß die ISR schneller ist, bin ich da zu>> optimistisch?>> Dein Code ist schlecht. Volatile schaltet die Optimierungen aus und> Division in der ISR ist ein ganz böses Foul.
Wenn man durch Zweierpotenzen mit Konstanten dividiert, kriegt die
Optimierung das schon hin.
Peter D. schrieb:> Dein Code ist schlecht. Volatile schaltet die Optimierungen aus und> Division in der ISR ist ein ganz böses Foul.
Die (Modulo-)Division hatte ich erst bei der Fehlersuche hinzugefügt, um
100%ig auszuschließen, daß ich nicht irgendwie vesehentlich Werte größer
als 15 zum Indexieren meines 16-byte-Arrays benutze. Was eigentlich
schon dadurch nicht passieren sollte, daß ich zwischen den Telegrammen
den Zähler zurücksetze. Das Verhalten war also schon da, bevor ich diese
Zeile eingefügt hatte, ich werde das aber heute Abend noch mal
verifizieren und die Zeile löschen. Danke für den Hinweis. Ich hatte das
hier tatsächlich nur als Bereichs-Begrenzung gesehen, nicht als
Division. Ist es aber natürlich, und damit innnerhalb der ISR ne dumme
Idee...
Kann ich hier auf das Volatile verzichten? Ich hätte gedacht, daß ich
Variablen, die (nur) in ISRs geändert werden, volatile machen muß. Eben
damit sie nicht wegoptimiert werden?
Was sagt denn der Assembler Output für
SPDR = spi_tx_bytes[spi_byte_count];
Wird da ein Zugriff gemacht und auf SPI-Register geschrieben?
Und das vergleichen mit
SPDR = spi_byte_count;
Oder wenn Du nicht fit in Assembler bist versuche mal
SPDR = spi_byte_count;
SPDR = spi_tx_bytes[spi_byte_count];
-> wird das SPI-Register überschrieben oder passiert nix?
Nils schrieb:> Kann ich hier auf das Volatile verzichten?
Man kann im Interrupt Tempvariablen benutzen, die einmalig die volatile
Variable einlesen bzw. zurückschreiben.
Oder man kann sie nur im Main als volatile casten:
1
#define IVAR(x) (*(volatile typeof(x)*)&(x))
Du kannst ja mal den Master irgendein Pattern senden lassen (z.B. 0xA5),
dann sollte zu sehen sein, ob das bei ner Kollision zurück kommt.
Auch kannst Du im Slave das WCOL auswerten.
Peter D. schrieb:> Nils schrieb:>> Ich hätte gedacht, daß die ISR schneller ist, bin ich da zu>> optimistisch?>> Dein Code ist schlecht. Volatile schaltet die Optimierungen aus und> Division in der ISR ist ein ganz böses Foul.
Ich habe das volatile gelöscht, ohne daß das was geändert hätte. Die
Optimierung steht im MicrochipStudio auf "-Og" (Voreinstellung) und läßt
diesen Code also wohl auch ohne volatile in Ruhe.
Die relativ banale Lösung des Problems: Die ISR war wohl tatsächlich
einfach nur zu lang.
Nachdem ich die Modulo-Division wieder rausgeschmissen (hat alleine noch
nicht geholfen) und auch das Setzen und Rücksetzen des Testausgangs
gelöscht habe, sieht sie jetzt so aus:
Ich bin nicht fit mit ASM und schaue da normalerweise nicht hin, aber
das war hier die richtige Stelle für die Fehlersuche (danke an
Bastler_HV). Ich hätte nicht gedacht, daß der Overhead mit push/pop für
den Aufruf der ISR das ganze so aufbläht und damit das ganze trotz des
langsamen SPI-Takts zu einem Zeitproblem macht (danke an peda).
Da habe ich dem AVR mit seinen 20MHz wohl erstmal zu viel zugetraut. Mal
schauen, ob ich so in meinem Projekt weiterkomme oder ob ich die
SPI-Geschwindigkeit im Master noch weiter reduzieren muß/kann. Oder ob
ich ihn wie von peda vorgeschlagen nach jedem Byte warten lasse.
Nils schrieb:> Die relativ banale Lösung des Problems: Die ISR war wohl tatsächlich> einfach nur zu lang.
Das ist mir auch schon zum Verhängnis geworden.
Wenn Du da noch einzelne Befehle einsparen willst, kannst Du die
Reihenfolge noch umdrehen:
Zusätzlich musst Du dann natürlich noch beim erstmaligen Vorbereiten der
Übertragung die beiden Variablen spi_byte_count++ und spi_next_byte =
spi_tx_bytes[spi_byte_count] passend setzen.
Thomas
Nils schrieb:> Ich bin nicht fit mit ASM
Das könnte man ja ändern...
> Ich hätte nicht gedacht, daß der Overhead mit push/pop für> den Aufruf der ISR das ganze so aufbläht und damit das ganze trotz des> langsamen SPI-Takts zu einem Zeitproblem macht (danke an peda).
Tja, in Asm ist es recht einfach, die Performance massiv zu erhöhen.
Aber im konkreten Fall überhaupt nicht nötig, da du ja auch den Sender
in der Hand hast.
Also, folgende Optimierungen helfen der Sache auf die Beine:
1) Du veränderst das Protokoll. Eigentlich: du SCHAFFST erstmal ein
Protokoll. Nacktes SPI kann man nämlich nicht wirklich ein Protokoll
nennen. Das zu schaffende Protokoll muss natürlich so gestaltet sein,
dass es die ersten beiden der folgenden Punkte ermöglicht und
bestmöglich unterstützt.
2) Du sorgst dafür, dass die ISR nach dem ersten Byte vom Master genug
Zeit bekommt, um überhaupt erstmal sicher zum Zuge zu kommen.
3) Du behandelst die Daten in der ISR als Block, d.h.: sie wird über die
Dauer der Blockgröße "blocking".
4) Du benutzt den Timer ausschließlich als "Watchdog", um dafür zu
sorgen, dass auch im Fehlerfall (z.B. Kabelbruch) die ISR nicht endlos
blockt, sondern spätestens nach der nominalen Dauer des Blocks + X
(Sicherheitsfaktor) definiert zurückkehrt.
Das hört sich erstmal nach viel Overhead an, ist aber tatsächlich in
Summe viel effizienter und zuverlässiger als der Ansatz mit einer
byteweisen ISR. Denn: du kannst dann die SPI-Bitrate mal eben um den
Faktor 30 erhöhen.
> Da habe ich dem AVR mit seinen 20MHz wohl erstmal zu viel zugetraut.
Naja, der kann schon deutlich mehr als dein Programm zeigt. Nur eben
nicht in C...
Aber ehrlicherweise muss man natürlich zugeben, dass das Hauptproblem
auch in Asm massiv stört: die lausige SPI-Hardware, die Atmel da
umgesetzt hat. Ohne Double-Buffering ist sie als Slave praktisch
nutzlos, nur als Master ergibt sie einen Sinn.
Im Übrigen wäre noch zu erwähnen, dass es durchaus viele SPI-Slaves
(sogar reine Hardware!) gibt, die mehr oder weniger exakt das oben
beschriebene Konzept benutzen.
c-hater schrieb:> die lausige SPI-Hardware, die Atmel da> umgesetzt hat. Ohne Double-Buffering ist sie als Slave praktisch> nutzlos
Bei einigen AVRs hat Atmel ja den UARTs einen SPI-Mode verpaßt mit
Pufferung. Aber nur als Master und nicht als Slave, wo es wirkliche
Probleme gelöst hätte. Wie man als MC-Entwickler solche Blackouts haben
kann, ist mir ein Rätsel.
Kritisch wird die Sache erst, wenn der Slave nicht nur SPI machen muß,
sondern auch noch andere Tasks, die auch weitere Interrupts benötigen.
Dann kann es passieren, daß sporadisch der SPI wieder Fehler macht, da
er andere Interrupts erstmal beenden lassen muß. Eine CRC ist daher
unumgänglich.
Zuverlässiger wäre daher, die UART zu nehmen oder I2C, was SCL als
Handshake benutzt.
CAN-Bus wäre auch sehr einfach und sehr zuverlässig, aber die Auswahl
ist bei den AVRs recht dürftig.
Peter D. schrieb:> Kritisch wird die Sache erst, wenn der Slave nicht nur SPI machen muß,> sondern auch noch andere Tasks, die auch weitere Interrupts benötigen.> Dann kann es passieren, daß sporadisch der SPI wieder Fehler macht, da> er andere Interrupts erstmal beenden lassen muß. Eine CRC ist daher> unumgänglich.>
Das ist u.a. bei meinem Programm (siehe
Beitrag "Probleme mit SPI Uebertragung") der Fall - der
Slave bedient nicht nur den SPI per Interrupt, es laufen auch Timer-ISRs
und ADC.
Eine CRC zu verwenden bei Master und Slave ist unumgänglich (habe ich
bei mir), man muss das 0-Byte des Slaves beim CRC aber verwerfen, da
dies falsche Werte beinhalten kann (und wird).
c-hater schrieb:> Nils schrieb:>>> Ich bin nicht fit mit ASM>> Das könnte man ja ändern...
Klar könnte man. Und auf dem Schirm habe ich das dank dieser Diskussion
jetzt auch, fragt sich nur ob ich außerhalb akuter Probleme auch Zeit
und Gelegenheit dafür finde. Man kommt ja zu nix :-)
> 2) Du sorgst dafür, dass die ISR nach dem ersten Byte vom Master genug> Zeit bekommt, um überhaupt erstmal sicher zum Zuge zu kommen.>> 3) Du behandelst die Daten in der ISR als Block, d.h.: sie wird über die> Dauer der Blockgröße "blocking".
Damit meinst du, daß ich das ganze Paket (bei mir 16 bytes) in einer
einzigen ISR behandle und darin jeweils auf die Status-Flags nach jedem
Byte warte, anstatt die ISR neu aufzurufen? Das klingt eigentlich auch
nicht schlecht. Damit willst du dafür sorgen, daß der Overhead nur
einmal anfällt statt bei jedem Aufruf/Byte?
> 4) Du benutzt den Timer ausschließlich als "Watchdog", um dafür zu> sorgen, dass auch im Fehlerfall (z.B. Kabelbruch) die ISR nicht endlos> blockt, sondern spätestens nach der nominalen Dauer des Blocks + X> (Sicherheitsfaktor) definiert zurückkehrt.
Der Timer sollte ursprünglich sowas ähnliches wie ein Watchdog sein: Ich
wollte den Bytezähler in der ISR bei Erreichen von NBYTES wieder nullen
und das Rücksetzen in main() war nur für den Fall gedacht, daß sich der
Bytezähler irgendwo "verschluckt".
Blocken kann die ISR in meiner aktuellen Version glaube ich nicht. Du
meinst sicher eine Version wie oben erwähnt, wo ich in der (nur einmal
pro Paket aufgerufenen) ISR jeweils auf die Statusbits nach Übertragung
der einzelnen Bytes warte. Und die könnten ausbleiben, wenn wegen
Drahtbruchs keine SCK-Pulse mehr kämen?
>> Da habe ich dem AVR mit seinen 20MHz wohl erstmal zu viel zugetraut.>> Naja, der kann schon deutlich mehr als dein Programm zeigt. Nur eben> nicht in C...
Touché...
Peter D. schrieb:> Kritisch wird die Sache erst, wenn der Slave nicht nur SPI machen muß,> sondern auch noch andere Tasks, die auch weitere Interrupts benötigen.> Dann kann es passieren, daß sporadisch der SPI wieder Fehler macht, da> er andere Interrupts erstmal beenden lassen muß. Eine CRC ist daher> unumgänglich.>> Zuverlässiger wäre daher, die UART zu nehmen oder I2C, was SCL als> Handshake benutzt.> CAN-Bus wäre auch sehr einfach und sehr zuverlässig, aber die Auswahl> ist bei den AVRs recht dürftig.
Ich bin durch meine Anwendung auf SPI festgelegt. Der AVR mißt die
Signale eines RC-Empfängers, und schickt sie an den STM32. Ursprünglich
sollte das direkt im STM32 passieren, aber weil es bei der RC-Messung
auf genaue Zeiten ankommt (Codierung der Werte am RC-Ausgang über Zeit
zwischen Pulsflanken) und mir im STM32 andere Interrupts manchmal die
Zeitmessung versauen, musste ich ausweichen. Und die einzigen noch
freien Ports am STM32 gehören zu dessen SPI2, weswegen ich jetzt das
Vergnügen habe, erstmals mit SPI zu arbeiten. Schöner Lerneffekt, siehe
Diskussion oben :-)
Die Festlegung auf AVR (ATm48 oder ATm128) kommt übrigens auch nur
daher, daß ich die halt noch hier rumliegen habe. Andere µCs bzw. andere
Schnittstellen wären vielleicht tatsächlich technisch besser geeignet,
aber die Frage stellt sich bei meinem Bastelprojekt gerade nicht. CRC
ist übrigens bei mir auch vorgesehen.
Nils schrieb:> aber weil es bei der RC-Messung auf genaue Zeiten ankommt> (Codierung der Werte am RC-Ausgang über Zeit zwischen Pulsflanken)
Also brauchst du letztlich eine Auflösung von ca. 2..5µs. Genauer wird
der Wert sowieso nicht übertragen.
> mir im STM32 andere Interrupts manchmal die Zeitmessung versauen
Dass du beim ARM Interrupts priorisieren kannst ist dir aber schon klar?
Was machst du denn da in den Interrupts? Meine sind im einstelligen
µs-Bereich abgehandelt.
Ich würde für diese Aufgabe eines der vielen STM32-Capture-Register
nehmen (ich habe sie ja schließlich auch bezahlt) und habe dann den
Zeitstempel auf den Bruchteil einer µs genau. Und für die Reaktion auf
den im Captureregister erfassten Zeitstempel und den dadurch ausgelösten
Interrupt kann ich mir dann ja mindestens 1ms Zeit lassen. Denn kürzer
wird der RC-Impuls nicht (und wenn eine deiner Interruptroutinen länger
als 1ms dauert, dann habe ich einen Mega-Programmfehler gefunden). Und
bei getrennter Erfassung der steigenden und fallenden Flanke in 2
Captureregistern noch wesentlich länger...
Siehe z.B. dort unter "Measuring Pulse Width":
https://controllerstech.com/input-capture-in-stm32/
Und generell gibt es viele Beispiele dafür:
https://www.google.com/search?q=stm32+capture> musste ich ausweichen.
Da ist nun eben die SPI-Schnittstelle annähernd die schlechteste Wahl.
SPI als Slave auf einem Controller laufen zu lassen ist nicht so
optimal, da die Hardware Unterstuetzung fehlt. SPI ist eher geeignet
fuer Schiebe Register, seien das 74595, oder aehnlich, oder FPGAs mit
SPI interface zum Controller.
Falls die Interrupt Routine ueberschaubar wenig macht, koennte man sie
auch in ASM schreiben und die unnoetigen Push/Pop weglassen. Die
compiler sichern immer alle Register, egal ob sie verwendet werden. Was
etwas unverstaendlich ist. Denn der Compiler weiss ja was die Interrupt
routine macht.
Pandur S. schrieb:> Die> compiler sichern immer alle Register, egal ob sie verwendet werden.
Wie kommst Du auf dieses schmale Brett?
Im obigen Listing werden 5 Register gesichert, der AVR hat aber 32.
5 < 32
Die Orgie mit R0, R1 ist einer unglücklichen Wahl geschuldet, da sie von
einigen Befehlen verändert werden (MUL, LPM).
R2, R3 wären besser geeignet gewesen für Status und Zero.
Pandur S. schrieb:> Die> compiler sichern immer alle Register, egal ob sie verwendet werden.
Nein, nein. So schlecht sind die Compiler schon lange nicht mehr.
Aber ziemlich behindert sind sie leider immer noch.
Was insbesondere fehlt, ist ein einfacher Mechanismus, um Register für
ISRs zu "reservieren", denn das ist fast immer die mit weitem Abstand
effizienteste Methode, um die Laufzeit von ISRs zu minimieren. Hier
rächt sich das Konzept, ISRs einfach als void fn(void) mit ein wenig
Drumrum zu betrachten, dieses Trivial-Konzept wird der Bedeutung der
ISRs in kleinen Architekturen in keinster Weise gerecht.
Diese "Reservierung" sollte in zwei Spielarten möglich sein.
1) Register ist "volatile", die Benutzung aber auf exclusiv ausgeführten
Code beschränkt, also ISRs und Code, der durch explizite Interruptsperre
zu exclusiv ausgeführtem Code gemacht wird.
Die so reservierten Register können dann in jedem exclusiv
ausgeführten Code benutzt werden, ohne sie zuvor sichern und und am Ende
wiederherstellen zu müssen. Allerdings ist der Inhalt nur innerhalb
einer Instanz des exclusiven Codes definiert, der nächste Aufruf beginnt
wieder mit unbekanntem initialen Registerinhalt (weil zwischenzeitlich
anderer exclusiver Code gelaufen sein könnte).
Diese Art reservierter Register bringt am meisten und es ist relativ
billich. Zumindest auf Architekturen mit einer großen Anzahl verfügbarer
Register.
2) Register ist an eine konkrete "Funktion" gebunden (hier ist nicht
eine C-Funktion gemeint). Also im Prinzip sowas wie eine globale
Variable, bloß halt nicht im RAM, sondern in Register(n).
Das ist teuer (weil halt das Register nur noch für genau einen Zweck
verwendet wird). Deswegen lohnt es typisch nur bei extrem häufig
aufgerufenen ISRs und ggf. deren Datenübergabe zu main().
Oder halt, wenn sowieso noch ungenutzte Register verfügbar sind. Für die
gibt's nämlich kein Geld an der Kasse zurück!