Hallo,
ich denke zu folgendem Problem fehlen mir gewisse Grundlagen:
Die fillDisplay Funktion unten überträgt nur beim ersten SPI.transfer
den array Inhalt "0xff, 0x00, 0xff" (also bei i=0), danach wird bis i <
102400 immer 3mal 0x00 übertragen.
Wieso das?
Leider verschweigst du die Definition von SPI1.transfer(). Damit können
wir nur raten.
SPI1.transfer(&array,3) ist vermutlich falsch. Das überträgt einen
Zeiger auf einen Zeiger auf ein Array.
Entweder SPI1.transfer(&array[0],3) (Zeiger auf das erste Element des
Arrays) oder SPI1.transfer(array,3) (Zeiger auf das Array) wäre hier
vermutlich korrekt.
Das es beim ersten Aufruf funktioniert ist vermutlich Zufall, da an der
Speicherstelle (vermutlich Stack) zufällig noch der korrekte Wert aus
der Initialisierung steht.
Michael H. schrieb:> SPI1.transfer(array,3) (Zeiger auf das Array)
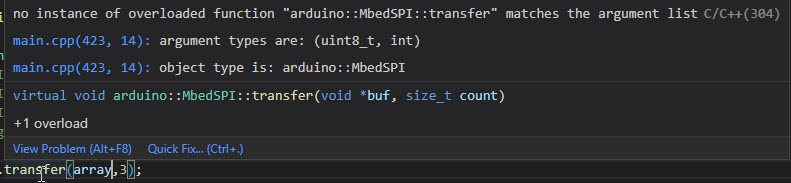
das gibt ein Fehler zurück, siehe Anhang.
unten die Klasse...
Verwendet wird, oder sollte wohl folgende Funktion:
Epi K. schrieb:> danach wird bis i <> 102400 immer 3mal 0x00 übertragen.
Vermutlich weil in dem Array für die Sendedaten danach die Empfangsdaten
stehen. Den SPI sendet und empfängt parallel. Dummerweise überschreibt
diese Funktion deine Sendedaten. Das könnte man auch intelligenter
lösen, hat man aber nicht.
Epi K. schrieb:> überträgt nur beim ersten SPI.transfer den array Inhalt
Hast du das mit dem Oszi auf dem Bus gemessen?
> SPI.transfer
Du hast dich aber schon informiert, wie SPI prinzipiell funktioniert?
Du weißt, dass bei SPI gleichzeitig mit jedem gesendeten Bit auch ein
Bit empfangen wird? Was macht also diese Funktion? Gibt sie evtl. im
Puffer die gleichzeitig empfangenen SPI-Daten zurück?
Epi K. schrieb:> das gibt ein Fehler zurück, siehe Anhang.
Ist ja eigentlich klar: die Funktion möchte einen void Pointer und du
übergibst einen char Pointer.
Probiers mal so: SPI1.transfer((void*)array,3);
Und dann arbeite doch einfach mal irgendein Grundlagenbuch zum Thema C
durch. Darin besonders den Abschnitt Pointer und Arrays.
Epi K. schrieb:> Michael H. schrieb:>> SPI1.transfer(array,3) (Zeiger auf das Array)>> das gibt ein Fehler zurück, siehe Anhang.
Ja logisch. array IST schon ein Zeiger auf das Array! &array ist Unsinn,
das wäre ein Zeiger auf den Zeiger auf das Array. Bestenfalls &array[0]
wäre OK, was ein Zeiger auf das erste Element ist, was gleichbedeutend
mit array ist. Ja, die Zeiger in C sind manchmal etwas verwirrend.
SPI.transfer() ist hier ungünstig und langsam, Grund wurde ja schon
genannt. Besser ist es eine ganze Zeile im RAM zu initialisieren und
diese per SPI.write() zu senden, ohne das Rücklesen was die meisten
Displays eh nicht unterstützen.
J. S. schrieb:> SPI1.transfer(array,3)
das geht nicht
Lothar M. schrieb:> Du weißt, dass bei SPI gleichzeitig mit jedem gesendeten Bit auch ein> Bit empfangen wird?Lothar M. schrieb:> Was macht also diese Funktion? Gibt sie evtl. im> Puffer die gleichzeitig empfangenen SPI-Daten zurück?Wilhelm M. schrieb:> Die Signatur der Funktion hat explizit einen Input/Output-Parameter. Das> Array wird wohl mit der Antwort überschrieben.
wird wohl das Hauptproblem sein. Ich denke man erkennt es daran?
J. S. schrieb:> SPI.transfer() ist hier ungünstig und langsam, Grund wurde ja schon> genannt. Besser ist es eine ganze Zeile im RAM zu initialisieren und> diese per SPI.write() zu senden, ohne das Rücklesen was die meisten> Displays eh nicht unterstützen.
hmm interessant, kann man mit write() auch Buffer / Arrays übertragen?
Naja muss ich mich wohl mal schlau machen.
Arduino F. schrieb:> for(const uint8_t zelle:array)
das habe ich noch nie gesehen, und diesen Code verstehe ich auch
nicht...
Epi K. schrieb:> das habe ich noch nie gesehen,
Nennt sich: "Range based for loop"
Sollte sich in jedem halbwegs guten/aktuellen C++ Grundlagenbuch finden
lassen
Auch möglich: (erfordert libstdc++)
J. S. schrieb:> SPI.transfer() ist hier ungünstig und langsam, Grund wurde ja schon> genannt. Besser ist es eine ganze Zeile im RAM zu initialisieren und> diese per SPI.write() zu senden, ohne das Rücklesen was die meisten> Displays eh nicht unterstützen.
da würde mich schon interessieren wie das gehen soll und ob es schneller
ist, mit SPI.write kann man ja nur 1 Byte übertragen, kein Buffer...?
Siehe Anhang Bild, ich verliere aktuell ca. 2 Clocks an Zeit zwischen
jedem Byte...
Epi K. schrieb:>> diese per SPI.write() zu senden, ohne das Rücklesen was die meisten>> Displays eh nicht unterstützen.>> da würde mich schon interessieren wie das gehen soll und ob es schneller> ist, mit SPI.write kann man ja nur 1 Byte übertragen, kein Buffer...?
Doch, die Methode write überträgt auch Arrays. Ein "Experte" hat es
geschafft, die überaus sinnvolle Methode zu verkrüppeln, indem die
Empfangsdaten die Sendedaten überschreiben. Man hätte schlicht die
Methode write DIREKT nutzen sollen! Es leben die 1001
Abstraktionsschichten!
nun ja, ich verstehe diese transfer Funktion noch nicht richtig (sie
greift ja schlussendlich auch auf write zu)...
ich kann eine Variable wie folgt anlegen:
uint32_t a = 0xFF00FF;
und mit SPI.transfer(&a,3), wird mir 0xFF, 0x00, 0xFF ausgegeben mit ca.
1-2 Clock Pause zwischen den Bytes.
Jetzt möchte ich mit SPI.transfer gleich ein Inhalt von 102400 * 3 Bytes
aufeinmal übertragen, wie stelle ich das am besten an (also ohne
mehrmals SPI.transfer aufrufen zu müssen)?
Da es sich um C++ handelt, ist es einfach unverständlich, wieso man so
eine vermurkste Signatur schreibt.
Besser wäre
[c]
struct MbedSPI {
template<auto N> void transfer(char (&a)[N]);
template<auto N>
void transfer(std::array<std::byte, N>& a);
};
Falk B. schrieb:> Epi K. schrieb:>> Michael H. schrieb:>>> SPI1.transfer(array,3) (Zeiger auf das Array)>>>> das gibt ein Fehler zurück, siehe Anhang.>> Ja logisch. array IST schon ein Zeiger auf das Array! &array ist Unsinn,> das wäre ein Zeiger auf den Zeiger auf das Array.
Nein, das ist falsch.
a ist ein Array-Objekt. In den meisten Kontexten zerfällt a zu einem
Zeiger, was ein Zeiger auf das erste Element ist.
&a ist ein Zeigr auf das Array-Objekt, was auch ein Zeiger auf das erste
Element ist vom Wert her.
Allerdings zerfällt a dann zu char* während &a den Type char(*)[3] hat.
Dies ist hier zwar egal wegen des void* (Polymorphie für Arme ala C),
jedoch merkt man das, wenn man (&a + 1) schreibt. Das ist dann ein
Zeiger (&a[0] + 3), da das Array-Objekt 3 Bytes groß ist.
> Ja, die Zeiger in C sind manchmal etwas verwirrend.
Ganz genau!
Wilhelm M. schrieb:> Da es sich um C++ handelt, ist es einfach unverständlich, wieso man so> eine vermurkste Signatur schreibt.>> Besser wäre>> struct MbedSPI {> template<auto N> void transfer(char (&a)[N]);>> template<auto N>> void transfer(std::array<std::byte, N>& a);> };
(da fehlte das schließende Tag)
Wilhelm M. schrieb:> a ist ein Array-Objekt. In den meisten Kontexten zerfällt a zu einem> Zeiger, was ein Zeiger auf das erste Element ist.
deshalb verstehe ich nicht warum SPI.transfer(array, 3) einen Fehler
werfen soll. Nur wenn es zu uint32_t array = 0xFF00FF; geändert wurde.
Oder?
Falk B. schrieb:> Doch, die Methode write überträgt auch Arrays. Ein "Experte" hat es> geschafft, die überaus sinnvolle Methode zu verkrüppeln, indem die> Empfangsdaten die Sendedaten überschreiben. Man hätte schlicht die> Methode write DIREKT nutzen sollen! Es leben die 1001> Abstraktionsschichten!> void arduino::MbedSPI::transfer(void *buf, size_t count) {> dev->obj->write((const char*)buf, count, (char*)buf, count);> }
ja, das wurde hier von Arduino 'vereinfacht'. Das Mbed write ist sehr
komplex weil ja auch unterschiedliche Anzahlen für transmitt/receive
count möglich sind.
Und das Arduino transfer ist das blockierende Mbed write, in Mbed gibt
es noch eine asynchrone Methode wenn es das Target unterstützt, und die
heißt da dann transfer. Es sollte aber möglich sein auf das komplette
Mbed API zuzugreifen und kann dann für receive buffer nullptr übergeben,
dann sollte die Targetabhängige Implementierung das Optimieren.
Wenn es um den RP2040 geht, dann ist in dem Fall der core von
EarlePhilPower besser. Und man kann die Bodmer/eTFT_SPI Lib nehmen, die
nutzt da SPI mit PIO und DMA. Diese Lib unterstützt den offiziellen core
leider nicht, die Krux mit den Arduino cores... Arduino hat hier für den
RP2040 aber in zwei Jahren nicht viel gemacht und der andere core ist
hier beliebter. Hat halt nur nicht die angenehmen Dinge von Mbed.
Wenn das Target ein H7 ist, dann geht das SPI noch durch die STM HAL, da
ist die asynchrone (Mbed)Transfer Funktion deutlich schneller.
Arduino33BLE habe ich nicht benutzt, mit Nordic MCU, k.A. wie es da
Implementiert ist.
Die Anzahl 102400 ist auch krumm, ist das wirklich ein 320*320 Display
oder welche Größe?
J. S. schrieb:> Wenn es um den RP2040 geht, dann ist in dem Fall der core von> EarlePhilPower besser. Und man kann die Bodmer/eTFT_SPI Lib nehmen, die> nutzt da SPI mit PIO und DMA. Diese Lib unterstützt den offiziellen core> leider nicht, die Krux mit den Arduino cores... Arduino hat hier für den> RP2040 aber in zwei Jahren nicht viel gemacht und der andere core ist> hier beliebter. Hat halt nur nicht die angenehmen Dinge von Mbed.> Wenn das Target ein H7 ist, dann geht das SPI noch durch die STM HAL, da> ist die asynchrone (Mbed)Transfer Funktion deutlich schneller.> Arduino33BLE habe ich nicht benutzt, mit Nordic MCU, k.A. wie es da> Implementiert ist.>> Die Anzahl 102400 ist auch krumm, ist das wirklich ein 320*320 Display> oder welche Größe?RP2040, und 320*320, jap.
Mit EarlePhilPower Core (und platformio / VS) kriege ich leider ein
Fehler.
Ich versuche gerade folgendes, leider ohne Erfolg. Beim ausgeklammerten
funktioniert es, aber beim Zweiten nicht, wieso??
Ziel ist nur alles mit einem SPI.transfer übertragen zu können.
J. S. schrieb:>> Abstraktionsschichten!>> void arduino::MbedSPI::transfer(void *buf, size_t count) {>> dev->obj->write((const char*)buf, count, (char*)buf, count);>> }>> ja, das wurde hier von Arduino 'vereinfacht'.
Verschlimmbessert!
Epi K. schrieb:> Ich versuche gerade folgendes, leider ohne Erfolg. Beim ausgeklammerten> funktioniert es, aber beim Zweiten nicht, wieso??> Ziel ist nur alles mit einem SPI.transfer übertragen zu können.
Was soll denn der Unsinn? Ich mein dein Ziel ist zwar richtig, der Weg
aber aus Holz!
Deine Funktion benötig ein 300kB lokales Array! Das hat dein RSP2040
nicht! Und für ein konstantes Füllmuster ist das Unfug. Bestenfalls für
eine Zeile!
Falk B. schrieb:> Deine Funktion benötig ein 300kB lokales Array! Das hat dein RSP2040> nicht! Und für ein konstantes Füllmuster ist das Unfug. Bestenfalls für> eine Zeile!
nur zum Testen, stimmt, dass mit den 300kB ist gerade zuviel.
Aber leider geht es auch nicht mit 51200*3 Bytes..., und dass der RAM
voll wäre meldet mir der Compiler nicht.
Epi K. schrieb:> nur zum Testen, stimmt, dass mit den 300kB ist gerade zuviel.> Aber leider geht es auch nicht mit 51200*3 Bytes..., und dass der RAM> voll wäre meldet mir der Compiler nicht.
Weil so ein Compiler nicht hellsehen kann und Programmieren nicht
idiotensicher ist. Stackverbrauch kann der Compiler im Normalfall nicht
anzeigen. Es gibt einige Ausnahmen, die das können.
Naja, eigentlich will man ja beim Füllen eine konstante Farbe haben und
nicht für RGB immer den gleichen Wert, was ja nur Grauwerte ergibt. Also
eher so.
Falk B. schrieb:> Naja, eigentlich will man ja beim Füllen eine konstante Farbe haben und> nicht für RGB immer den gleichen Wert, was ja nur Grauwerte ergibt. Also> eher so.
ich habe es jetzt so gelöst (array global):
1
for(uint8_ti=0;i<2;i++){
2
for(uint32_ti=0;i<(51200);i++){
3
array[i*3]=a>>16;
4
array[i*3+1]=a>>8;
5
array[i*3+2]=a;
6
}
7
SPI1.transfer(array,3*51200);
8
}
Falk B. schrieb:> Was soll denn der Unsinn? Ich mein dein Ziel ist zwar richtig, der Weg> aber aus Holz!
Aber ja, zwischen jedem Byte verliert die SPI1.transfer Funktion noch
1-2 Clock an Zeit... deshalb ist es wohl wirklich Unsinn :-( ...
Das sieht auch nach 20 MHz SPI clock aus, mit der genannten Lib kommt
man auf 62,5 MHz und DMA. Das macht sich beim Bildaufbau schon
bemerkbar.
Allerdings wird da auf das Ende des DMA gewartet, auch da gibt es noch
Optimierungsmöglichkeiten.
Falk B. schrieb:> Naja, eigentlich will man ja beim Füllen eine konstante Farbe haben und> nicht für RGB immer den gleichen Wert, was ja nur Grauwerte ergibt. Also> eher so.>>
1
>voidfillDisplay(uint32_tcolor){// RGB
2
>uint32_tline[240];// 320*3=240*4
3
>uint32_tp1,p2,p3;
4
>
5
>p1=(color<<8)|(color>>16);
6
>p2=(color<<16)|(color>>8);
7
>p3=(color<<24)|color;
8
>
9
>for(uint32_ti=0;i<320;i++){
10
>for(intj=0;j<240;j+=3){
11
>line[j]=p1
12
>line[j+1]=p2;
13
>line[j+2]=p3;
14
>}
15
>SPI1.transfer(line,320*3);
16
>}
17
>}
18
>
Das Array line mit einem repetitiven Pattern vollzuschreiben, macht
eigentlich auch keinen Sinn.
Da das ganze in C++ realisiert ist, könnte man bis zur Treiber-Ebene mit
Containern arbeiten. Für diesen speziellen Fall würde man einen
"Folding-Container" benutzen, der ein Wertemuster wiederholt an
bestimmten Indexpositionen sichtbar macht. Dann bräuchte man bei
intelligenter Auslegung nur 3 Byte RAM.
Da das ganze Interface aber eigentlich ein C-Interface ist (s.a.
Anmerkungen oben), geht das natürlich nicht so einfach. Zudem ist das
RAM ja da, und ungenutzter Speicher bringt kein Geld zurück ;-)
J. S. schrieb:> Das sieht auch nach 20 MHz SPI clock aus, mit der genannten Lib kommt> man auf 62,5 MHz und DMA. Das macht sich beim Bildaufbau schon> bemerkbar.> Allerdings wird da auf das Ende des DMA gewartet, auch da gibt es noch> Optimierungsmöglichkeiten.
welche Lib meinst du jetzt? TFT_eSPI ?
Wie kriege ich ohne GUI Library eine SPI.transfer Funktion hin, die kein
1-2 Clock zwischen jedem Byte verliert?
Ich suche quasi nur ein Code (Bare-Metal?) für die SPI denn ich in
meinem "Arduino-Code" integrieren könnte... (RP2040)
Zahle gerne was dafür...
Wilhelm M. schrieb:> Das Array line mit einem repetitiven Pattern vollzuschreiben, macht> eigentlich auch keinen Sinn.
Es ist ein Workaraund. Man kann ja auch die dämliche transfer-Methode
aufräumen.
> Da das ganze in C++ realisiert ist, könnte man bis zur Treiber-Ebene mit> Containern arbeiten. Für diesen speziellen Fall würde man einen> "Folding-Container" benutzen, der ein Wertemuster wiederholt an> bestimmten Indexpositionen sichtbar macht. Dann bräuchte man bei> intelligenter Auslegung nur 3 Byte RAM.
Und der ist schneller als die Variante oben? Da habe ich meine Zweifel.
> Da das ganze Interface aber eigentlich ein C-Interface ist (s.a.> Anmerkungen oben), geht das natürlich nicht so einfach. Zudem ist das> RAM ja da, und ungenutzter Speicher bringt kein Geld zurück ;-)
Die 960 BYTE kann ein RP2040 wohl verschmerzen, zumal lokal auf dem
Stack.
Epi K. schrieb:> Wie kriege ich ohne GUI Library eine SPI.transfer Funktion hin, die kein> 1-2 Clock zwischen jedem Byte verliert?
Die normale SPI-Lib kann das.
https://www.arduino.cc/reference/en/language/functions/communication/spi/transfer/
Ohhh, dort steck der gleiche Mist dahinter! Wer produziert so einen
Käse?
Nimm die Variante mit der einen Zeile von mir, das ist ein sehr guter
Kompromiss aus Geschwindigkeit und RAM-Bedarf.
So einen Buffer (oder zwei) kann man sehr gut auch für die
Zeichenfunktionen gebrauchen, siehe lvgl. Das RAM kann die CPU in
nullkommanix füllen, jeden SPI Transfer einzeln starten und abwarten
dauert ewig. Und wenn man dann noch DMA hat und den nächsten Buffer
vorbereiten kann, dann macht es richtig Sinn.
Das SPI aus der eTFT Lib ist mit den EarlePhilPower Core verwurschtelt,
ich habe lvgl auf dem Pico daher auch erstmal mit diesem Core
angefangen.
oder probieren das Mbed SPI direkt zu benutzen:
Falk B. schrieb:> Nimm die Variante mit der einen Zeile von mir, das ist ein sehr guter> Kompromiss aus Geschwindigkeit und RAM-Bedarf.
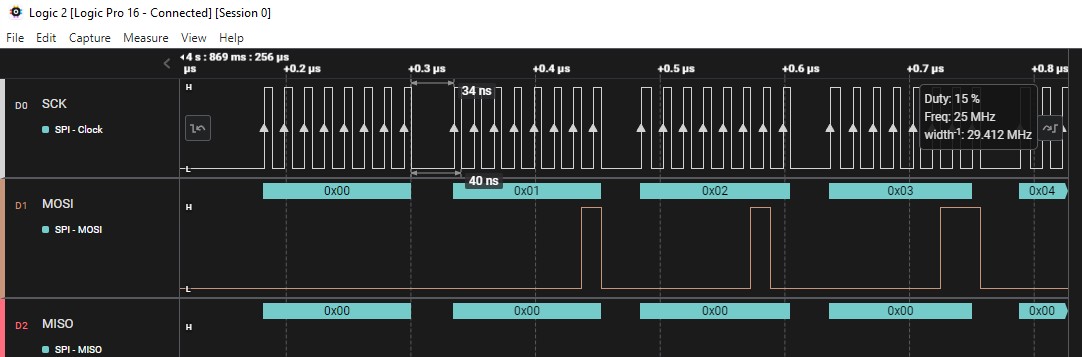
nee, ich weiss nicht ob du mich verstehst,
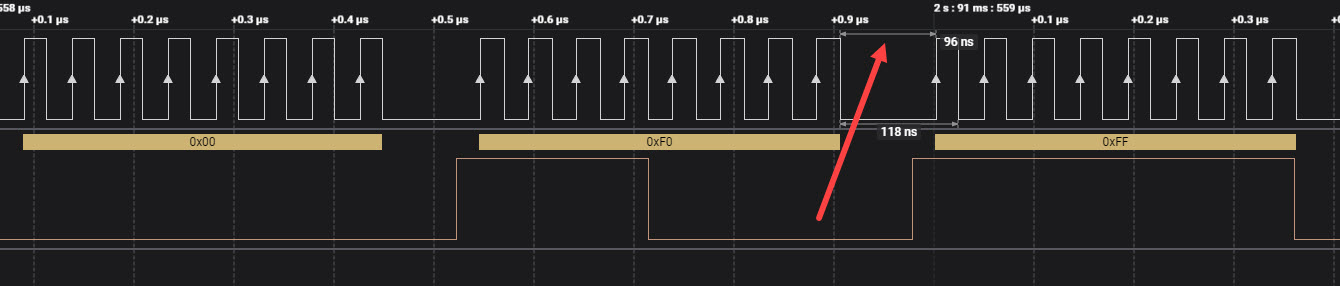
das Problem ist siehe Anhang, diese Pause (roter Pfeil, 96ns, bzw. 1-2
Clocks), die muss ich weghaben, dann wäre die SPI.transfer perfekt...
Ich weiss jetzt wie ich mit einem einzigen SPI.transfer Aufruf fast den
ganzen Displayinhalt beschreiben kann, jedoch ist das ganze eben noch zu
langsam, wegen dieser verflixten Pause im SPI.transfer...
Wie löse ich dies - ohne verwurschtelte Bibliotheken wo ich nicht weiss
wo jetzt was ist...
J. S. schrieb:> spi.frequency(30'000'000);> spi.write((const char*) array, n, nullptr, 0);
mm sehr interessant, und wo, wie setze ich MOSI, SCK Pins?
"n" wird wohl die Anzahl bytes sein, und was ist nullptr?
Epi K. schrieb:> mm sehr interessant, und wo, wie setze ich MOSI, SCK Pins?
die sind als Konstanten so vorhanden, 19,16,18.
Normalerweise darf man da gültige andere Pins wählen, aber das ist in
der kompilierten Mbed Lib nicht so umgesetzt. Andere Pins führen zum
'Blink of Death'.
J. S. schrieb:> oder probieren das Mbed SPI direkt zu benutzen:mbed::SPI spi(SPI_MOSI,> SPI_MISO, SPI_SCK);> ...> spi.frequency(30'000'000);> spi.write((const char*) array, n, nullptr, 0);>> kann es jetzt nur nicht testen.
ich erhalte folgenden Fehler, siehe Anhang...
Epi K. schrieb:> Falk B. schrieb:>> Nimm die Variante mit der einen Zeile von mir, das ist ein sehr guter>> Kompromiss aus Geschwindigkeit und RAM-Bedarf.>> nee, ich weiss nicht ob du mich verstehst,>> das Problem ist siehe Anhang, diese Pause (roter Pfeil, 96ns, bzw. 1-2> Clocks), die muss ich weghaben, dann wäre die SPI.transfer perfekt...
Ja und? Gewinnst du dann einen Preis? Ist dann dein Leben lebenswert?
Vermutlich entsteht die Pause zwischen den einzelnen Bytes durch das
nicht sonderlich gute Nachladen des nächsten Werts. Das wird vermutlich
per CPU und einer Warteschleife gemacht, die halt erstmal erkennen muss,
daß das aktuelle Byte komplett übertragen wurde und dann erst das
nächste in das SPI-Register schreiben kann. Und da das SPI vermutlich
keine Doppelpufferung hat, entsteht halt die Lücke. Mein Gott, dadurch
läuft dein SPI anstatt mit vollen 20 MHz effektiv nur mit ca. 16MHz.
D.h. das Schreiben des LCDs mit 307200 Bytes dauert statt 123ms eben
147ms. Das macht das Kraut nicht fett.
> Ich weiss jetzt wie ich mit einem einzigen SPI.transfer Aufruf fast den> ganzen Displayinhalt beschreiben kann, jedoch ist das ganze eben noch zu> langsam, wegen dieser verflixten Pause im SPI.transfer...
Was ist denn zu langsam? Wieviele Jahre Pause liegen denn dazwischen?
Kann es sein, daß du die Verhältnisse LEICHT verkennst?
> Wie löse ich dies - ohne verwurschtelte Bibliotheken wo ich nicht weiss> wo jetzt was ist...
Das schrieb ich bereits, du verstehst es leider nicht.
Falk B. schrieb:> Was ist denn zu langsam? Wieviele Jahre Pause liegen denn dazwischen?> Kann es sein, daß du die Verhältnisse LEICHT verkennst?
stimmt, das habe ich vor lauter Bäume übersehen... ist nicht viel.
Danke an alle.
Harald K. schrieb:> Wilhelm M. schrieb:>> Öffentliche Vererbung.>> Ja. Und? Taucht da irgendwo eine Klasse namens "SPI" auf? Ich sehe da> andere Klassennamen.
Die heisst auch SPIClass ;-)
Harald K. schrieb:>> class MbedSPI : public SPIClass
und wird sich in einer der nicht gezeigten Header-Dateien befinden.
Das ist ja der ArduinoMbed core, da sind beide APIs drin. SPI ist die
Klasse aus Mbed, die Arduino Funktionen greifen darauf zu, Mbed hat viel
mehr Funktionalität als das Arduino API.
Das Arduino API ist einem eigenen Repo wo nur das API drin ist, da ist
die SPIClass per define gleich HardwareSPI gesetzt.
https://github.com/arduino/ArduinoCore-API/blob/master/api/HardwareSPI.h
Das scheint an der halbherzigen Umsetzung des Mbed API zu liegen.
Transfer benutzt spi_write_read_blocking vom Pico SDK, und das erwartet
einen gültigen Pointer für den receive Buffer. Transfer müsste das
prüfen und entsprechend read oder write only aufrufen, das gibt es im
SDK.
Also Core patchen und PR einreichen, aber Arduino sieht da träge aus.
Oder gucken wie man an das spi Handle kommt und eine Subclass vom SPI
bauen.
Ich gucke nachher mal, wollte auch mal meine picoProbe ausprobieren.
Und dann wäre da noch die Frage ob man den 2. core nutzen kann.
J. S. schrieb:> ja, der ILI9488 ist nicht gut für SPI. Über 8 Bit parallel kann der> RGB565,
Warum kann der das per SPI nicht? Waren die Entwickler zu faul oder
doof?
>das wäre noch schneller wenn es so angeklemmt werden kann.
Sicher, aber SPI ist halt ein Kompromiss aus Geschwindigkeit und
Pinbedarf.
Falk B. schrieb:> Waren die Entwickler zu faul oder> doof?
Das würde ich denen nicht unterstellen. Ilitek hat viele Controller,
dieser hat SPI, aber eben nur 1 oder 6 Bit pro Farbkanal. Dafür kann er
noch MIPI, 8/9/16/18/24 Bit parallel, das ist doch schon was. Wenn man
kann, dann sucht man sich einen Controller mit passendem Interface aus.
Es gibt aber nun mal günstige fertige Kombis von Displays und
Controller, da muss man mit den Schnittstellen leben die man angeboten
bekommt.
J. S. schrieb:> Über 8 Bit parallel kann der> RGB565, das wäre noch schneller wenn es so angeklemmt werden kann.
jäjo, aber mit Arduino-Code, da müsste ich irgendwie direkt die Port /
GPIO -Register des RP2040 ansprechen können (und viel im Datenblatt
herumstudieren), und ob das so einfach geht wie für ein 8bit MCU a la
Attiny oder so (DDRB = 255; PORTB &= ~(1<<PB0);) - wage ich zu
bezweifeln.
Und die TFT_eSPI Library ist mir zu unübersichtlich um es nur hierfür zu
verwenden.
Tja und cool wäre wenn man auch SPI DMA mit paar Register setzen
aktivieren könnte :D ..., ich denke da gibt es noch kein Beispiel-Code?
also zahlen würde ich gerne für solchen Code..
habe das auch mal ausprobiert:
Das spi.write((const char*)array,sizeof(array), nullptr, 0); läuft in
assert rx_len != tx_len und stoppt dann mit hardfault.
Um das zu sauber zu umgehen muss man die libFrameworkArduino.a neu
bauen, aufwändig...
Ein 10 kB Buffer kann mit der vorhandenen transfer Funktion gesendet und
gelesen werden (überschreibt den Buffer dann) und das dauert dann 3,705
ms @ 62,5 MHz.
Quick and dirty kann man aber das write aus dem SDK aufrufen mit