Hallo, ich habe ein paar Fragen zum M4F, Lazy Stacking und Automatic Stacking: *Allgemein:* • Warum sind S0..S15 als Caller Caller Saved Registers“ und S16..S31 als “Callee Defined Registers” definiert. Was ist der Hintergrund und wie sollten diese in der praktischen Implementierung genutzt werden? Leider habe ich kein einziges Dokument gefunden dass auf das Konzept näher eingeht und es erklärt. *Lazy Stacking:* • Wenn eine Funktion, welche die die FPU verwendet, eine andere Funktion aufruft, die ebenfalls die FPU verwendet, sichert dann Lazy-Stacking die Register S0—S15? Oder ist die nur bei Exceptions/Interrupts der Fall? • Wenn ich es korrekt verstehe reserviert Lazy-Stacking Speicher auf dem Stack für S0..S15. Wenn die FPU von de aufgerufenen Funktion verwendet wird, werden S0..S15 gesichert und wiederhergestellt. Wenn eine Funktion in C implementiert wird, ist für den Programmierer nicht ersichtlich ob der der Caller und Callee auch möglicherweise S16..S31 verwenden, was bei Lazy-Stacking zu einem Fehler führen würde, weil nur S0..S15 abgedeckt sind. Wie kann das bei Lazy-Stacking vermieden werden? *Automatic Stacking:* • Wenn eine Funktion, welche die FPU verwendet, eine andere Funktion aufruft, welche ebenfalls die FPU verwendet, sichert dann automatic-stacking S0..S31 und stellt diese wieder her? Vielen Dank. Mit freundlichen Grüßen, Seppel
Angehängte Dateien:
-

419_fpu_register_bank.gif
84 KB -

426_lazy_stacking.gif
120 KB -

427_lazy_stacking.gif
100 KB -

428_lazy_stacking.gif
82 KB -

429_lazy_stacking.gif
82 KB -

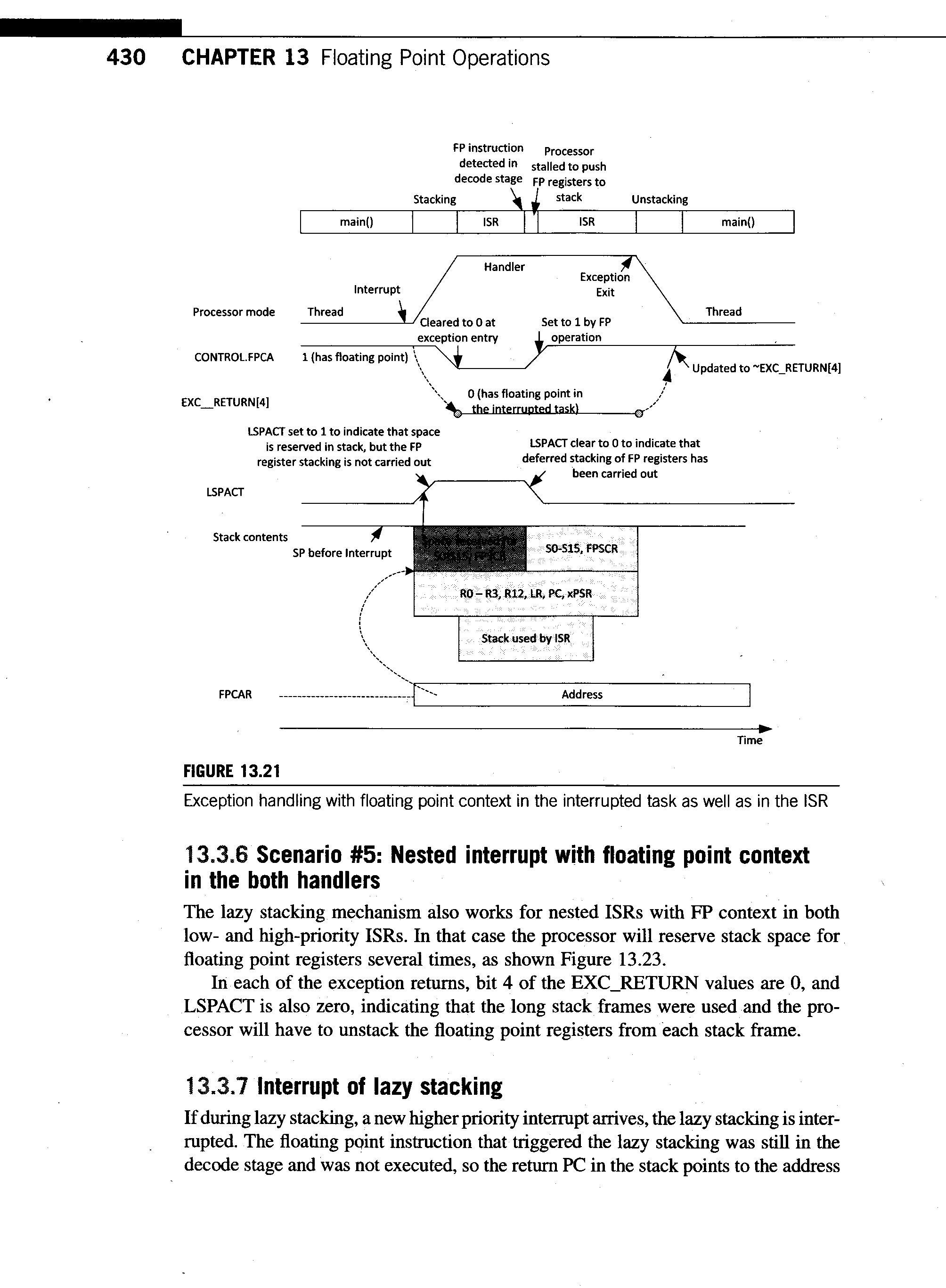
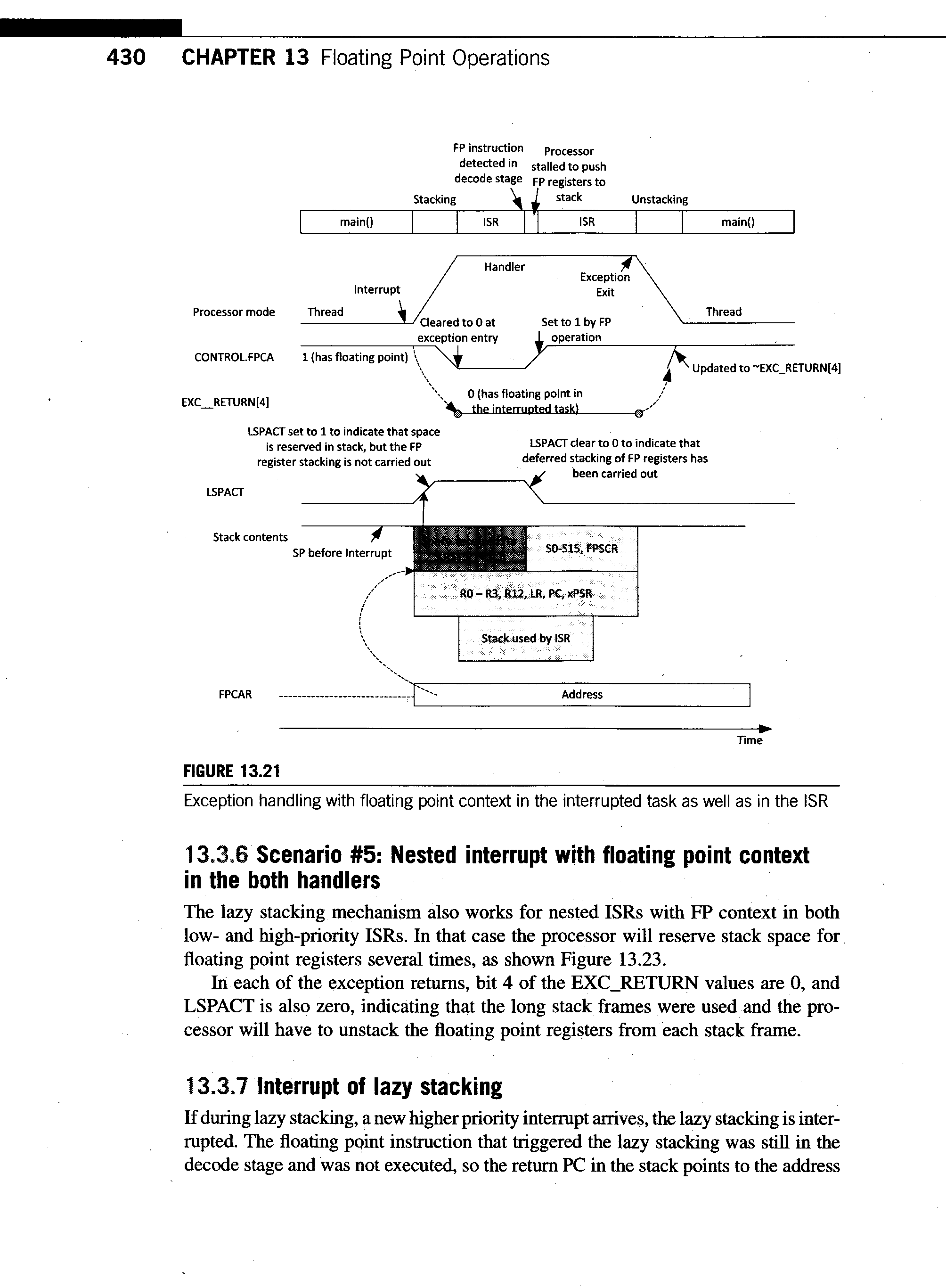
430_lazy_stacking.gif
80 KB -

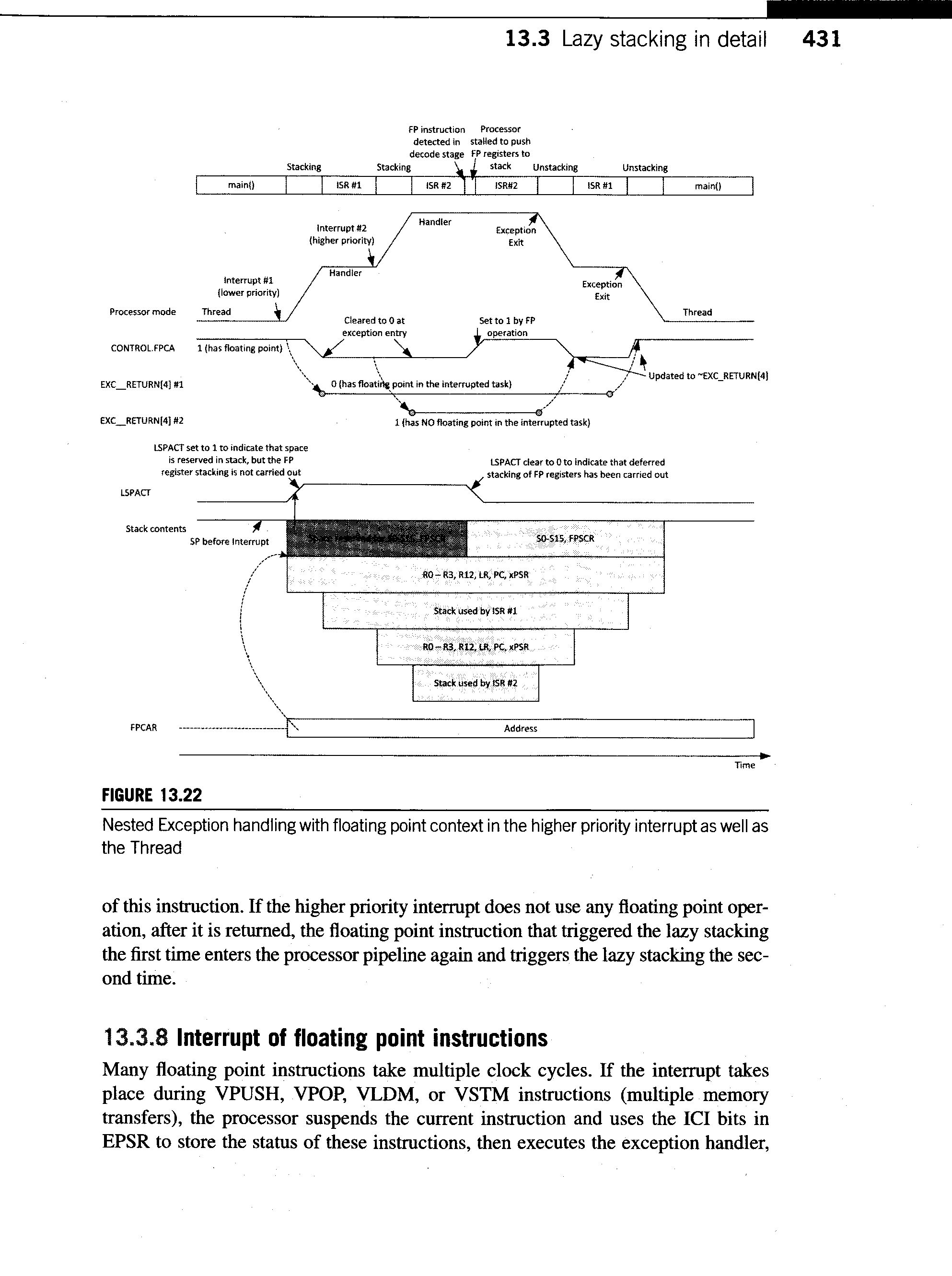
431_lazy_stacking.gif
75 KB -

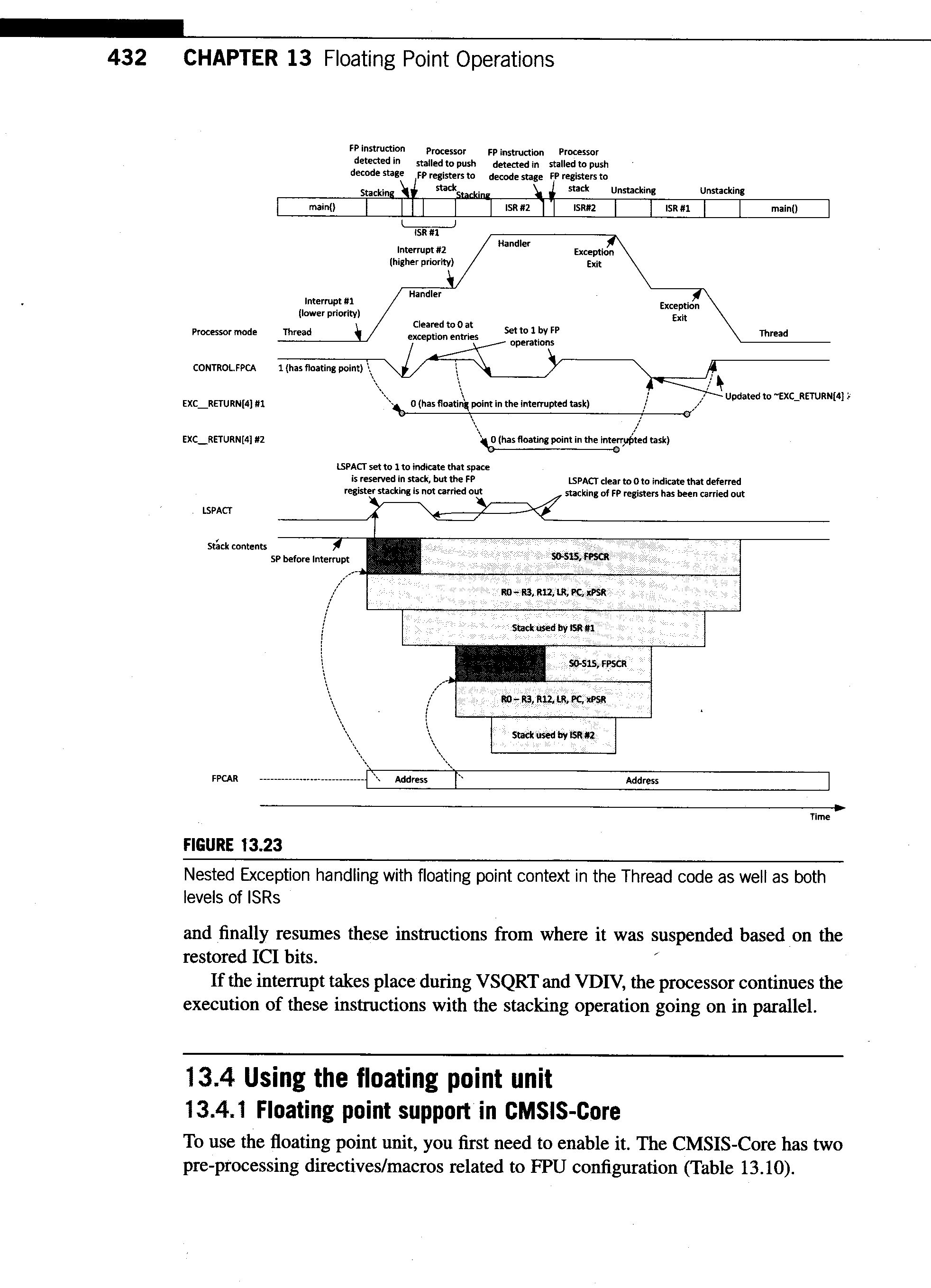
432_lazy_stacking.gif
76 KB





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ich habe praktisch keine Ahnung von Assembler und den internen Details der ARM Kerne. Bisher habe ich mich auf den gcc verlassen können. Aber ich erinnere mich, in dem Buch "The Definitive Guide to ARM Cortex-M3 and Cortex-M4 Processors" von Joseph Yiu etwas dazu gelesen zu haben. Mal sehen, ob ich das wieder finde ... hab's leider nur in Papierform vorliegen ... Wenn dir diese Seiten helfen, dann nutze dies als Anregung, das Buch zu kaufen.
Noch ein vielversprechendes Dokument zum Thema: https://www.trustedfirmware.org/docs/FP-support-in-TF-M.pdf
Beitrag #7435739 wurde von einem Moderator gelöscht.
Beitrag #7435846 wurde von einem Moderator gelöscht.
ARM hat in einem Dokument spezifiziert (EABI), welche Register von der aufrufenden und welche von der aufgerufenden Funktion zu sichern sind. Was ARM bei den Cortex-M getan hat, ist diese Spezifikation in Hardware zu gießen. Alle Register die von der aufrufenden Funktion zu sichern sind, werden von der Hardware bei einem Interrupt gesichert und so lässt sich dort ein Interrupt Handler komfortabel in C ohne Assembler programmieren. Also die Hardware sichert S0-S15, jede Funktion muss S16-S31 selbst sichern, wenn sie sie denn verwendet (ganz egal ob das jetzt in einem Interrupt passiert oder im Normalen Programmablauf). Das tun auch alle Compiler die sich an die EABI von ARM halten. Und das sind IMHO alle (mir bekannt clang und gcc). Und nur mit gleicher ABI kann man eine von einem Compiler compilierte Lib auch mit einem anderen Compiler/Linker einbinden. Natürlich könnte ein Compiler eine andere ABI implementieren. In diesem Fall würde das Konzept mit dem "die Hardware sichert das passend" bei dem Cortex-M gegebenenfalls nicht mehr funktionieren und dann wäre Assemblercode erforderlich um die fehlenden Register zu sichern.
Ich erlaube mir mal eine kleine Zusatzfrage, wenns recht ist. Dafür extra einen Thread erstellen wäre auch doof... Also, bei der Cortex M4 FPU hat sich ARM ja nicht lumpen lassen und 32 Register spendiert. Warum hat die CPU nur 16 Register? gibts dafür einen technischen Grund? der AVR hat ja auch 32. Mit mehr Registern könnte man doch mehr Operanden vorhalten, ohne dass man diese immer mit Load und Store aus dem Memory holen muss. Zumal ja von den 16 sowieso noch 3 verloren gehen für PC, SP und LR. (den Vorteil des LR habe ich auch nie verstanden, denn wenn die Verschachtelungstiefe der Subroutinen >1 ist, dann muss das LR ja auch auf den Stack, man hätte die Returnadresse also eigentlich auch immer gleich auf den Stack tun können).
Tobias P. schrieb: > Warum hat die CPU nur 16 Register? Gehe einfach davon aus, dass ARM Anzahl der Register und Befehle praxisnah optimiert hat. Denkbar wären ja auch 256 Register, die die Befehlslänge sprengen und überhaupt nicht benötigt würden. > den Vorteil des LR habe ich auch nie > verstanden, denn wenn die Verschachtelungstiefe der Subroutinen >1 ist, Aber auch nur dann. Und alles zusammen macht die Cortexe richtig schnell. Gunnar F. schrieb im Beitrag #7435846: > Immerhin hat Stefan geholfen. Und du? Deinen Beitrag habe ich jetzt nicht verstanden. Und dass Stefanus mal wieder auf unterstem Niveau startet ("... eigentlich habe ich von Nichts eine Ahnung ...") verhindert zielführende Diskussionen.
Tobias P. schrieb: > Warum hat die CPU nur 16 Register? gibts dafür einen technischen Grund? > der AVR hat ja auch 32. Mit mehr Registern könnte man doch mehr > Operanden vorhalten, ohne dass man diese immer mit Load und Store aus > dem Memory holen muss. Warum nicht 64 Register, oder gar 256 Register? Irgendwer hat sich irgendwann halt festgelegt. 16 Register ist schon viel. Ich habe mit Mikrocontrollern angefangen, die hatten nur 5 Register, wovon 2 für Zeiger reserviert waren.
Tobias P. schrieb: > Warum hat die CPU nur 16 Register? Die erste ARM Architektur, entstanden in den 1980ern, war nicht darauf optimiert, aus der damaligen Chiptech das Maximum rauszuholen. Das taten die Anderen. Sondern eine adäquate Leistung bei geringem Anspruch an die Fertigungstechnik und die Chipdesigner zu entwickeln. Nebeneffekt: Das erwies sich viele Jahre später als ein entscheidendes Argument für ARM als wichtigstem 32-Bit CPU-Core für Custom-Chips. Die meisten anderen waren dafür zu komplex. Die Anzahl Register ist daher natürlich ein wenig eine Ressourcenfrage, aber hat auch mit der Befehlscodierung und der Entscheidung für Predication zu tun, also der bedingten Ausführung jedes einzelnen Befehls und der Integration eines Barrel-Shifters in einen Datenpfad der ALU. Die Predication frisst 4 Bits Befehlscode, dazu 4 Registernummern, und schon sind 20 Bits von 32 bereits vergeben. Bei dem späteren ersten Thumb-Befehlssatz war es ähnlich. Wenn der Befehlscode nur 16 Bits breit ist, kommt man mit 8 Registern besser zurecht als mit 16, weshalb Thumb eigentlich 8 Register präferiert. Die übrigen 8 sind eher ein Anhängsel der anfangs mit beiden Befehlssätzen ausgestatteten ARM7er. Um Performance ging es bei Thumb ja nicht, sondern um Platz.
Stefan F. schrieb: > Ich habe mit > Mikrocontrollern angefangen, die hatten nur 5 Register, wovon 2 für > Zeiger reserviert waren. Einer der ersten 8-Bit Mikroprozessoren hatte bereits 16 Stück 16-Bit Register. Was man dem Die-Shot auch ansieht: https://www.cpu-world.com/CPUs/1802/die/L_RCA-CDP1802.jpg Gebracht hat es wenig. Er war nicht zuletzt aufgrund der damals noch langsamen CMOS-Technik selbst ausgesprochen langsam, und obendrein umständlich zu programmieren. Aber das hatte andere Gründe.
{kind=link}
Tobias P. schrieb: > Also, bei der Cortex M4 FPU hat sich ARM ja nicht lumpen lassen und 32 > Register spendiert. Warum hat die CPU nur 16 Register? gibts dafür einen > technischen Grund? der AVR hat ja auch 32. Naja, beim AVR belegt ein 16-Bit int ja schon 2 Register; so gesehen steht es unentschieden. > Mit mehr Registern könnte man > doch mehr Operanden vorhalten, ohne dass man diese immer mit Load und > Store aus dem Memory holen muss. Zumal ja von den 16 sowieso noch 3 > verloren gehen für PC, SP und LR. Schlimmer: R12 ist für den Linker reserviert, weil z.B. der Offset bei relativen Sprüngen zu klein ist. Ein Framepointer ist manchmal auch ganz nützlich und dann gibt's noch das ominöse R9. https://community.arm.com/arm-community-blogs/b/architectures-and-processors-blog/posts/on-the-aapcs-with-an-application-to-efficient-parameter-passing beantwort evt. auch Seppels Frage nach S0..S15 vs. S16..S31. Das ist das gleiche Prinzip wie R0..R3 vs. R4..R7. > (den Vorteil des LR habe ich auch nie > verstanden, denn wenn die Verschachtelungstiefe der Subroutinen >1 ist,m > dann muss das LR ja auch auf den Stack, man hätte die Returnadresse also > eigentlich auch immer gleich auf den Stack tun können). Aber unter dem Strich spart es bei jeder inneren Funktion push und pop. Wahrscheinlich spart es beim exception handling einen Haufen Transistoren. Von gesparten Taktzyklen garnicht zu reden. Selbst wenn das LR gepusht werden muss, geht das fast gratis mit STM,LDM.
Tobias P. schrieb: > Mit mehr Registern könnte man > doch mehr Operanden vorhalten, ohne dass man diese immer mit Load und > Store aus dem Memory holen muss. Als diese Entscheidung getroffen wurde, war der Zugriff auf externes RAM schnell genug, um pro Ausführungszyklus des ARM-Prozessors ein Wort aus dem Speicher holen zu können. Bei nichtsequentiellem Zugriff auf DRAM kam ein Zyklus hinzu. Der Druck, sehr viel in Registern halten zu müssen, war dementsprechend gering. Heute dauert dies einige Hundert CPU-Zyklen und selbst der L1-Cache braucht schon 4-5.
Bauform B. schrieb: > Wahrscheinlich spart es beim exception handling einen Haufen > Transistoren. Von gesparten Taktzyklen garnicht zu reden. Selbst wenn > das LR gepusht werden muss, geht das fast gratis mit STM,LDM. Im ursprünglichen ARM war genau dies eigentlich eine Fehlkonstruktion. Verschachtelte normale Interrupts hatte man überhaupt nicht auf der Rechnung gehabt. Ohne Verschachtelung ist eine Umschaltung der Registersätze bei Exceptions sehr effizient, besonders beim Fast-Interrupt. Mit ihr wurden Interrupt sehr umständlich. Das erklärt, weshalb man bei den Cortex-M so viele Gedanken in dieses Thema investierte.
Tobias P. schrieb: > dann muss das LR ja auch auf den Stack, man hätte die Returnadresse also > eigentlich auch immer gleich auf den Stack tun können). Die Verwendung eines Link-Registers ist eine typische Eigenheit von RISC-Architekturen und hat viel mit deren Philosophie zu tun: keep it simple, keine Befehle mit komplexer Ausführungsstruktur. Stacks sind darin oft nur Konvention, nicht in Hardware gegossen. So auch bei der ursprünglichen ARM-Architektur - LDM/STM verletzten eigentlich dieses Prinzip.
(prx) A. K. schrieb: > Einer der ersten 8-Bit Mikroprozessoren hatte bereits 16 Stück 16-Bit > Register. Was man dem Die-Shot auch ansieht: > https://www.cpu-world.com/CPUs/1802/die/L_RCA-CDP1802.jpg > Gebracht hat es wenig. Er war nicht zuletzt aufgrund der damals noch > langsamen CMOS-Technik selbst ausgesprochen langsam, und obendrein > umständlich zu programmieren. Aber das hatte andere Gründe. Was heißt umständlich, es ist ein echter RISC, so einer braucht nunmal ein paar Zeilen Quelltext extra. Wir hatten etwas wie ARMs AAPCS, 12 Register waren reserviert, u.a. eine Art LR, zwei für call und switch/case u.ä. und mit den 4 freien bin ich ziemlich gut ausgekommen. Aber das Beste ist: jedes Register kann PC sein, damit geht quasi selbstmodifizierender Code im EPROM ;)
Bauform B. schrieb: > Was heißt umständlich, es ist ein echter RISC, so einer braucht nunmal > ein paar Zeilen Quelltext extra. Der 1802 ist zwar simpel strukturiert, hat aber nicht die für die klassische RISC Philosophie typische Load/Store-Architektur mit etlichen Datenregistern. Im Gegenteil. Nicht alles, was aus Altersgründen noch einfach strukturiert war, gilt als RISC. Die umständliche Programmierung des 1802 resultiert nicht aus irgendwas mit solchem RISC. Es war schlichtweg ausgesprochen umständlich, an eine beliebige Speicheradresse heran zu kommen, oder ein beliebiges Unterprogramm von vielen aufzurufen. Natürlich hat man dafür angepasste Programmiertechniken verwendet. Trotzdem ein PITA, verglichen mit den anderen damaligen Typen. Wer es einfach haben wollte, implementierte mit dem Teil sowas wie FORTH. Löste sich also so schnell wie möglich vom nativen Befehlssatz. Das ging einigermassen, denn dazu passte die Architektur leidlich. Indirekt adressieren konnte sie, wenn schon sonst nichts. Schneller wurde es dadurch allerdings nicht gerade.
Tobias P. schrieb: > Warum hat die CPU nur 16 Register? gibts dafür einen > technischen Grund? der AVR hat ja auch 32. Bei ARM64 haben sie genau das getan: Dort gibt es 30 Register (und jedes ist 64Bit groß) und davon sind die ersten 8 laut ABI für die Parameterübergabe der Funktionen. Dafür ist jetzt jeder Opcode wieder 32Bit breit. Und die ldm stm Befehle sind, ebenso wie das bedingte ausführen jeder Instruktion, weggefallen. Es gibt nur noch ein "push/pop von 1-2 Registern" und bedingtes Ausführen bei einem Branch.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.