Was ist das? Und wie benutzt man es?
Esmu P. schrieb: > Was ist das? Ein SCM. Eine dezentrale Vereinsverwaltung. Esmu P. schrieb: > Und wie benutzt man es? git init git status git add ... git commit -m "mein erster commit" git branch git clone [url] usw... mfg mf
Versionskontrollsystem. Das wichtigste Werkzeug zum Programmieren, sollte man vor der Programmiersprache selber lernen.
Esmu P. schrieb: > Was ist das? Und wie benutzt man es? Nur im dunklen und ohne Zucker. Diese dahingerotzten Threads werden langsam zur Pest;-( Am besten über /dev null ins Delete verschieben.
Moin, Wie so oft, gilt fuer git insbesondere: RTFM! Hier werden sie geholfen: https://git-man-page-generator.lokaltog.net/ scnr, WK
Angehängte Dateien:
-

InCaseOfFire.jpg
17 KB

Roland E. schrieb: > Gibts das auch lokal oder nur in der Wolke? git ist erstmal nur lokal. Es wird immer gern mit github durcheinander geworfen. Mit git erzeugt man aus einem 'dummen' Arbeitsverzeichnis ein Repository, da stecken dann zusätzlich die Verwaltungsdaten und die ganze Historie mit drin. Bei git ist es Prinzip, es ist ein dezentrales System und jede Arbeitskopie enthält für sich die gesamte Historie (kann aber auch gestrippt werden). github ist einer von vielen möglichen remotes, hier ist es ein öffentlicher Server über den git mit seinem eigenen Protokoll die Repos synchronisieren kann. Ein remote kann im einfachen Fall aber auch ein anderes Verzeichnis auf dem gleichen oder einem anderen Rechner sein, oder man kann z.B. gitlab als Community Edition selber hosten oder mit gitea gibt es eine weitere, sparsamere Server Möglichkeit.
J. S. schrieb: > Roland E. schrieb: >> Gibts das auch lokal oder nur in der Wolke? > > git ist erstmal nur lokal. Es wird immer gern mit github durcheinander > geworfen. > Mit git erzeugt man aus einem 'dummen' Arbeitsverzeichnis ein > Repository, ... OK. Wie SVN nur in bunt... Wenns weiter nix ist...
Roland E. schrieb: > OK. Wie SVN nur in bunt... > > Wenns weiter nix ist... Ne, das kann man nur im entferntesten Vergleichen im Hinblick auf Versionierung.
Frank K. schrieb: > Hier gibt es eine detaillierte :-) Zusammenfassung: > https://git-scm.com/book/de/v2 Na Klasse. Jetzt hab' ich wieder 14MB weniger auf meinem Tolino. <Thumbs up>
Esmu P. schrieb: > Was ist das? Und wie benutzt man es? Je nach Vorbildung / Erfahrung ist git unterschiedlich schwer zu verstehen. Ich selbst nutze es nur rudimentär, vor allem als externes backup auf github. Im Grunde genommen ist es dafür da, die Änderungen in einem Projekt zu dokumentieren. Ich glaube in Word gibt es es, rudimentär, etwas vergleichbares. Der wirklich große Vorteil von git kommt aber dann zum tragen, wenn mehrere Menschen an einem Projekt zusammen arbeiten. Dann nimmt einfach jeder sich den aktuellen Stand des Projektes (main branch) und entwickelt darauf sein neues Feature (feature branch). Wenn es fertig ist, gibt man es zur Vereinigung (merge) frei. Diese Anfrage kann von dem Team eingesehen, kommentiert und oder geändert werden. Wenn keiner etwas einzuwenden hat, wird der eigene Code dem Projekt (main branch) hinzugefügt.
Ich halte es auch für einen 1 Personen Haushalt für sehr sinnvoll. Du entwickelst etwas alleine linear vor dich hin. Eine Tasterabfrage, funktioniert, commit. Displayausgabe, funktioniert, commit. usw. Und wenn etwas nicht mehr funktioniert kannst du genau die Änderungen zurückverfolgen und gucken wo das passiert sein muss. Mag da trivial sein, aber daran kann man üben. Wenn man dann komplexen fremden Code bekommt, dann ist das die wahre Wonne wenn man sowas hat.
Flöte schrieb: > Roland E. schrieb: >> OK. Wie SVN nur in bunt... >> >> Wenns weiter nix ist... > > Ne, das kann man nur im entferntesten Vergleichen im Hinblick auf > Versionierung. Kannst du das mal näher erläutern?
Roland E. schrieb: > Gibts das auch lokal oder nur in der Wolke? Ja, siehe http://stefanfrings.de/git/index.html
Frank K. schrieb: > Hier gibt es eine detaillierte :-) Zusammenfassung: > https://git-scm.com/book/de/v2 Sehr schön! Eine sehr gute, finde ich, Zusammenfassung. Ich hatte noch nie damit zu tun und habe auch keinerlei Ahnung über Github. Das kann ja sein, aber wie einer hier oben, nicht du :-), herum stänkert das geht gar nicht. Ich bin bei einer Kompilierung einer Software darüber gestolpert. Daher meine Frage. Sollte doch erlaubt sein finde ich. Vielen Dank nochmals. :-)
Roland E. schrieb: > OK. Wie SVN nur in bunt... > Wenns weiter nix ist... Eben nicht. Git kommt im Gegensatz zu SVN ohne (zentrales) Repository aus. Danach hattest du doch gefragt.
Stefan F. schrieb: > Esmu P. schrieb: >> Was ist das? Und wie benutzt man es? > > http://stefanfrings.de/git/index.html Wer hat deinen Beitrag mit -1 bewertet? Ein angemeldeter Stammposter? Der soll sich schämen.
Frank K. schrieb: > Hier gibt es eine detaillierte :-) Zusammenfassung: > https://git-scm.com/book/de/v2 Mit 546 Seiten scheint dieses "git" ja sehr einfach zu sein. Ist das eine Programmiersprache die man lernen muß um programmieren zu können? Duck und weg.
Hans H. schrieb: > Frank K. schrieb: >> Hier gibt es eine detaillierte :-) Zusammenfassung: >> https://git-scm.com/book/de/v2 > > Mit 546 Seiten scheint dieses "git" ja sehr einfach zu sein. > Ist das eine Programmiersprache die man lernen muß um programmieren zu > können? > Duck und weg. Bücher schaden nur demjenigen der sie nicht besitzt bzw. nicht gelesen hat. Von dieser Regel gibt es nur recht wenige Ausnahmen. Die Bibel hat vermutlich 1000 Seiten und da steht überhaupt gar nichts von Interesse drin.
Stefan F. schrieb: > Eben nicht. Git kommt im Gegensatz zu SVN ohne (zentrales) Repository > aus. Danach hattest du doch gefragt. SVN lässt sich sehr wohl mit lokalen Repositories verwenden. Die entsprechenden URL beginnen dann mit file:// statt svn:// o.ä.. Ein wesentlicher Unterschied besteht aber darin, dass es bei Subversion nur eine einzige Repository-Instanz geben kann, d.h. man kann nicht nur lokal arbeiten und versionieren und das ganze dann in einem separaten Schritt auf ein anderes Repository "hochladen" (push).
Hat jemand Erfahrung mit TortoiseGit? Kann man das gut nutzen um nicht das Terminal von git nutzen zu wollen?
TortoiseGit ist ok, aber nicht für den Einstieg. Wenn man nicht weiß was man eigentlich tun muss, dann führen die vielen Buttons die man einfach drücken kann zu schnell zum Chaos. Für den Anfang tatsächlich genau die Kommandos aus der ersten Antwort hier im Thread von Achim ausprobieren und den Ablauf mit ‚git commit‘ verinnerlichen. Bei Fehlern ist git sehr hellseherisch und gibt Tipps was vielleicht gemeint war. In VSCode der git client ist auch gut und einfach zu bedienen. Mit PlatformIO als Ersatz zur Arduino IDE ist das ein Quantensprung.
Andreas S. schrieb: > Stefan F. schrieb: >> Eben nicht. Git kommt im Gegensatz zu SVN ohne (zentrales) Repository >> aus. Danach hattest du doch gefragt. > > SVN lässt sich sehr wohl mit lokalen Repositories verwenden. Die > entsprechenden URL beginnen dann mit file:// statt svn:// o.ä.. Ein > wesentlicher Unterschied besteht aber darin, dass es bei Subversion nur > eine einzige Repository-Instanz geben kann, d.h. man kann nicht nur > lokal arbeiten und versionieren und das ganze dann in einem separaten > Schritt auf ein anderes Repository "hochladen" (push). Najaaa... bei Git ist jedes Arbeitsverzeichnis ein eigenes Repository. Man kann Git auch mit einem zentralen Repo aufsetzen ("git init --shared --bare /var/git/MingDing.git"), aber für den Anwendungsfall, für den Herr Torvalds (ebender, ja) es entwickelt hat, nämlich die Entwicklung des Linux-Kernels (mit mehreren tausend Entwicklern) funktioniert das eher... suboptimal. Darum ist Git auf Anwendungsfälle ausgelegt, die klassische Version Control Systems (VCS) wie VCS, CVS, Subversion und Co. eher schlecht abbilden, also insbesondere Branching und Merging. Dabei ist Git besonders mächtig und die Basis für "echte" Workflow-Modelle wie beispielsweise Gitflow. Heute möchte ich nicht mehr ohne Git arbeiten -- nicht einmal in privaten Projekten. Dabei kenne ich noch andere VCS, aber an die Mächtigkeit und Flexibilität von Git kommt keins davon auch nur ansatzweise heran.
Andreas S. schrieb: > Stefan F. schrieb: >> Eben nicht. Git kommt im Gegensatz zu SVN ohne (zentrales) Repository >> aus. Danach hattest du doch gefragt. > > SVN lässt sich sehr wohl mit lokalen Repositories verwenden. Es wurde ja nicht gesagt, dass das Repo nicht lokal sein kann, sondern, dass es nur ein einziges zentrales Repo gibt. Sheeva P. schrieb: > Darum ist Git auf Anwendungsfälle ausgelegt, die klassische Version > Control Systems (VCS) wie VCS, CVS, Subversion und Co. eher schlecht > abbilden, also insbesondere Branching und Merging. Dabei ist Git > besonders mächtig und die Basis für "echte" Workflow-Modelle wie > beispielsweise Gitflow. Solche Workflows sind bei Arbeit mit mehreren Entwicklern die größte Stärke von git. Damit lässt sich so ein Software-Entwicklungsprojekt sehr viel strukturierter bearbeiten, vor allem wenn man das noch mit den Features von z.B. gitlab oder Atlassian kombiniert. > Heute möchte ich nicht mehr ohne Git arbeiten -- nicht einmal in > privaten Projekten. Dabei kenne ich noch andere VCS, aber an die > Mächtigkeit und Flexibilität von Git kommt keins davon auch nur > ansatzweise heran. Ich finde, wer halbwegs ernsthaft Software entwickelt, bracht zwingend ein Versionierungstool. Ich bin immer wieder überrascht, wie viele da noch mit x verschiedenen Verzeichnissen oder dutzenden von .zip-Archiven ihres Codes halbwegs den Überblick zu behalten versuchen. Bis auf die dezentrale Eigenschaft von git brauche ich aber dessen spezielle Features privat nicht unbedingt, da würde es sonst auch svn tun. Da ich es geschäftlich aber auch viel nutze, nehme ich es natürlich privat auch. Bei git ist es auch besonders einfach, ein neues Projekt zu starten - eifach "git init", und schon habe ich ein neues Repo + Arbeitskopie.
Wer auch nur im entferntesten Sinne professionell Code entwickeln möchte, muss heutzutage Git lernen. Es ist der Standard und das gesamte ecosystem moderner Tools setzt darauf. Es ist essentiell trotz der Lernkurve, die durchaus existiert ;)
Hans H. schrieb: > Mit 546 Seiten scheint dieses "git" ja sehr einfach zu sein. In diesem Buch wird Git vollständig beschrieben. Das ust halt eine sehr mächtige ausgereifte Software. Die Basics sind einfach, die lernt man besser durch ein Tutorial. Das Buch braucht man eher selten für Soezialfälle und Detail Fragen.
Andreas S. schrieb: > SVN lässt sich sehr wohl mit lokalen Repositories verwenden. Ja stimmt. Ali K. schrieb: > Hat jemand Erfahrung mit TortoiseGit? > Kann man das gut nutzen um nicht das Terminal von git nutzen zu wollen? Habe ich mal probiert und letztendlich als weitgehend nutzlos empfunden. TortoiseSvn und TortoiseHg sind 20 mal nützlicher. TortoiseGit ist völlig anders (leider). Allerdings ist das Git Kommandozeilen-Tool sehr gut gemacht und in Kombination mit der mitgelieferten gitk Gui und einem Merge Tool wie Winmerge oder Meld gut zu handhaben. Wenn man nur alleine lokal arbeitet merkt man den Unterschied zwischen Git, SVN und Mercurial kaum. Deren Basis- Funktionen sind fast identisch. Erst beim Arbeiten im Team werden die Unterschiede wichtig. Die Open Source Projekte haben fast alle auf Git gewechselt. Die Programmiersprache Go lädt fremde Bibliotheken von öffentlichen Git Repositories, da hat man also keine freie Wahl.
Stefan F. schrieb: > Roland E. schrieb: >> OK. Wie SVN nur in bunt... >> Wenns weiter nix ist... > > Eben nicht. Git kommt im Gegensatz zu SVN ohne (zentrales) Repository > aus. Danach hattest du doch gefragt. Ist für eine Datensicherung aber nicht optimal. Wobei ich SVN ja auch dezentral lokal aufsetzen könnte...
Roland E. schrieb: > Ist für eine Datensicherung aber nicht optimal. "Kommt ohne aus" bedeutet nicht "kann nicht verwenden". Du kannst natürlich einen zentralen upstream verwenden, dann ists ähnlich zu SVN, du kannst aber auch mehrere gleichzeitig verwenden, egal ob Webservice wie Github/lab, NAS-Netzwerklaufwerk, SSH-Server in Australien, USB-Stick im Tresor, ...
Roland E. schrieb: > Stefan F. schrieb: >> Roland E. schrieb: >>> OK. Wie SVN nur in bunt... >>> Wenns weiter nix ist... >> >> Eben nicht. Git kommt im Gegensatz zu SVN ohne (zentrales) Repository >> aus. Danach hattest du doch gefragt. > > Ist für eine Datensicherung aber nicht optimal. > > Wobei ich SVN ja auch dezentral lokal aufsetzen könnte... Es ist nicht dezentral. Auch dann nicht wenn man es rein lokal aufsetzt.
Hallo Kolja L. schrieb: > Im Grunde genommen ist es dafür da, die Änderungen in einem Projekt zu > dokumentieren. > Ich glaube in Word gibt es es, rudimentär, etwas vergleichbares. >... Daumen Hoch. Das ist endlich mal eine Erklärung, die jeder versteht, im Gegensatz zu den "Erklärungen", die soviel voraussetzen, dass eine so allgemein (aber wichtige, der TO ist ganz sicher nicht alleine mit seinen Fragen, nur traut sich kaum einer diese zu stellen) gestellte Frage keinen Sinn machen würde. Es ist immer wieder erstaunlich, welch große Probleme viele "Nerds" (eigentlich eine Ehrenbezeichnung, aber... ) haben über ihren Horizont zu schauen, bzw. sich daran zu erinnern, dass auch sie mal klein angefangen haben, bzw. dass halt nur sehr wenige Super talentiert in irgendeinen Technischen Bereich , in der Mathematik und oder der Informatik sind. "Es ihnen zufliegt" Auch bedauerlich zu sehen, wie negativ die Frage des TO bewertet wird. Dabei handelt es sich doch um eine Frage, wie sie genau (im besten Sinne, keine Ironie, keine versteckte Kritik - nein ganz ernst gemeint) ins Forum passt. Und ich kann es schon "sehen": "Nutze Google" "Nutze die Wikipedia" "Bla Bla Bla" Nein eben nicht - weil dort wird oft genauso tief eingestiegen, letztendlich wird dort ebenfalls nichts erklärt, zumindest wenn man Laie ist, der GIT usw. typischer Weise nur als Quelle für ein Nachbauprojekt oder zum Download eines Programms nutzt, und man sich Fragt: "Warum so kompliziert, warum nicht einfach ein fertiger "normaler" Download? Genau das wie du Kolja L. es erklärt hast, sieht eine gute Erklärung, die sich an einen echten (erkennbaren) Laien wendet aus. Von da aus kann man ja gerne tiefer einsteigen, wenn man selbst (in einer Gruppe - im "einfachen" nach Feierabend und wenn man Lust hat Hobbyumfelds auch nicht üblich) aktiv werden will. Diederich
Dieterich schrieb: > Es ist immer wieder erstaunlich ... Git ist ein Arbeitsmittel für Entwickler, dementsprechend ist die offizielle Anleitung gestaltet. Nicht-Entwickler sollen das gar nicht benutzen.
Dieterich schrieb: > Hallo Ähh, danke für deine Ausführung. Ich bin etwas rot geworden. Und du sprichst mMn ein wirkliches Problem an. Jemand fragt etwas auf seinem Niveau, jemand anderes antwortet auch auf seinem Niveau. Ich habe sehr oft das Gefühl, das viele Antworten den Fragenden nicht weiterbringen, obwohl sie korrekt sind.
Hallo Stefan F. schrieb: > Nicht-Entwickler sollen das gar nicht > benutzen. Aber auch als "nur" mit einem µC hantierender Bastler der ein Projekt nachbaut und jemand der gerne quelloffene und kostenlose Software ("Open-Source") nutzt, kommt man halt ganz schnell mit GitHub und ähnliches in Verbindung - und sei es nur durch einen Link. Da fragt man sich als reiner Anwender schon: Warum so komisch, warum gibt es da ganze Ordner, was soll das? Ich möchte doch nur den Download, den hex code, den fertigen Sketch...?! Warum die "1001" anderen Dateien, die doch "keiner" braucht? Warum macht der Autor (dass es oft ein Team ist und oft aus Profis mit entsprechendem Background und Workflow aus dem Arbeitsleben besteht, ist halt oft viel zu fern, von der "Welt" des einfachen Anwenders und Freizeit µC Nutzers - ja nicht nur bei "Nerds" ist der Horizont nun mal begrenzt und das meist ganz ohne bösen Willen) es sich scheinbar so schwer und "komisch" ? Man kennt als reiner Anwender ja nur die fertigen Programme bzw. die Firmware, den Sketch und selbst wenn man mal dann sogar selbst was Kleines als reiner Hobbyist ohne beruflichen Background was macht (halt oft im Arduinouniversum) landet es halt auf der lokalen Festplatte und die "Versionen" -falls überhaupt vorhanden sind in Unterordnern mit entsprechendem Datum "sortiert". Man kennt die ganzen Zwänge und Notwendigkeiten halt nicht und wird halt doch manchmal (recht oft wenn es um µC Code oder Open Source Software geht) nach GitHub und Co. weiterleitet. Da ist die Frage nach dem Sinn und was ist das überhaupt alles soll und wie es funktioniert (auch wenn man es nie aktiv als Anbieter nutzen wird) schon berechtigt, nur scheint das bei den "Profis" niemand mehr zu verstehen... Kolja L. schrieb: > Ich habe sehr oft das Gefühl, das viele Antworten den Fragenden nicht > weiterbringen, obwohl sie korrekt sind. Das Gefühl habe ich auch - je spezieller und technischer das Thema ist, umso mehr fällt auch mir das immer wieder auf. Dietrich
Dieterich schrieb: > Da fragt man sich als reiner Anwender schon ... Offenbar kannst du nicht richtig zwischen Anwender und Entwickler trennen. Als Anwender von Ibuprofen kaufe eine eine fertige Packung Ibuprofen. Ich setze mich nicht mit dem Rezept und den einzelnen Zutaten auseinander um das Medikament selbst zu produzieren. Und wenn doch, sollte ich dazu bereit sein, alles nötige zu lernen.
Hallo Stefan F. schrieb: > Ich setze mich nicht mit dem Rezept und den einzelnen Zutaten > auseinander um das Medikament selbst zu produzieren. Und wenn doch, > sollte ich dazu bereit sein, alles nötige zu lernen. Aber vielleicht interessiert es mich, wie und warum das jeweilige Medikament funktioniert - jetzt aber nicht auf Mediziner oder "Entwickler" Niveau, aber mal eben "ganz grob und generell" Insgesamt schadet es nicht generell und unabhängig vom Thema auch mal zu fragen: "Warum und wie"? Es bildet, hält einen geistig wach und ist (oft) einfach nur interessant. Des Weiteren hinkt dein Vergleich ein wenig: Das Rezeptfreie Medikament Ibuprofen kaufe ich in der Apotheke (oder in NL und BE im Supermarkt zum Bruchteil des Preises in DL...) - immer und ohne besondere Ausnahme. Aber als Anwender von so mancher Open Source Software oder fast immer, wenn es um den Sourcecode für fertige Nachbau µC Projekte geht, erfolgt der "Download" via GitHub und ähnlichen Systemen und eben nicht über einen normalen Download (oder den für Windowsnutzer seltsamen Paketsystemen in der Linuxwelt). Da wird man als auch nur minimal an den Hintergründen interessierter halt neugierig und möchte ein wenig (aber halt auch nicht alle Details) mehr wissen - auch wenn man es für die reine Anwendung nicht braucht. Und dann sind Erklärungen wie sie Kolja L. genau das richtige - nicht zu viel und (fast) nichts voraussetzend. Solche Erklärungen im technischen Bereich und speziell auch der Mathematik (ist mir zumindest immer so aufgefallen) zu geben scheint für sehr viele Spezialisten aber "Pfui" zu sein...
Angehängte Dateien:
-

2023-10-28_11-09.png
140 KB
Dieterich schrieb: > Aber als Anwender von so mancher Open Source Software oder fast immer, > wenn es um den Sourcecode für fertige Nachbau µC Projekte geht, erfolgt > der "Download" via GitHub und ähnlichen Systemen und eben nicht über > einen normalen Download Was ist denn für dich ein "normaler" Download, wenn du mit einem ZIP File schon überfordert bist. > Da wird man als auch nur minimal an den Hintergründen interessierter > halt neugierig und möchte ein wenig (aber halt auch nicht alle Details) > mehr wissen Wo ist dann das Problem, wenn dir jemand sagt, du sollst Git installieren und "git clone https://whatever " eingeben und eine Anleitung zu Git zu lesen? Komplexe Projekte sind halt so. Werfe doch den Entwicklern nicht vor, dass sie ihr Projekt nicht für Laien gestaltet haben.
Hallo Ziemlich frecher persönlicher Angriff, den du da nochmal ablieferst (eventuell meine Beiträge mal genau durchlesen und verstehen...).
Dieterich schrieb: > Ziemlich frecher persönlicher Angriff Vielleicht haben wir unterschiedliche Projekte im Sinn. Nenne mal ein konkretes Beispiel für Dieterich schrieb: > Aber als Anwender von so mancher Open Source Software oder fast immer, > wenn es um den Sourcecode für fertige Nachbau µC Projekte geht, erfolgt > der "Download" via GitHub und ähnlichen Systemen und eben nicht über > einen normalen Download (oder den für Windowsnutzer seltsamen > Paketsystemen in der Linuxwelt).
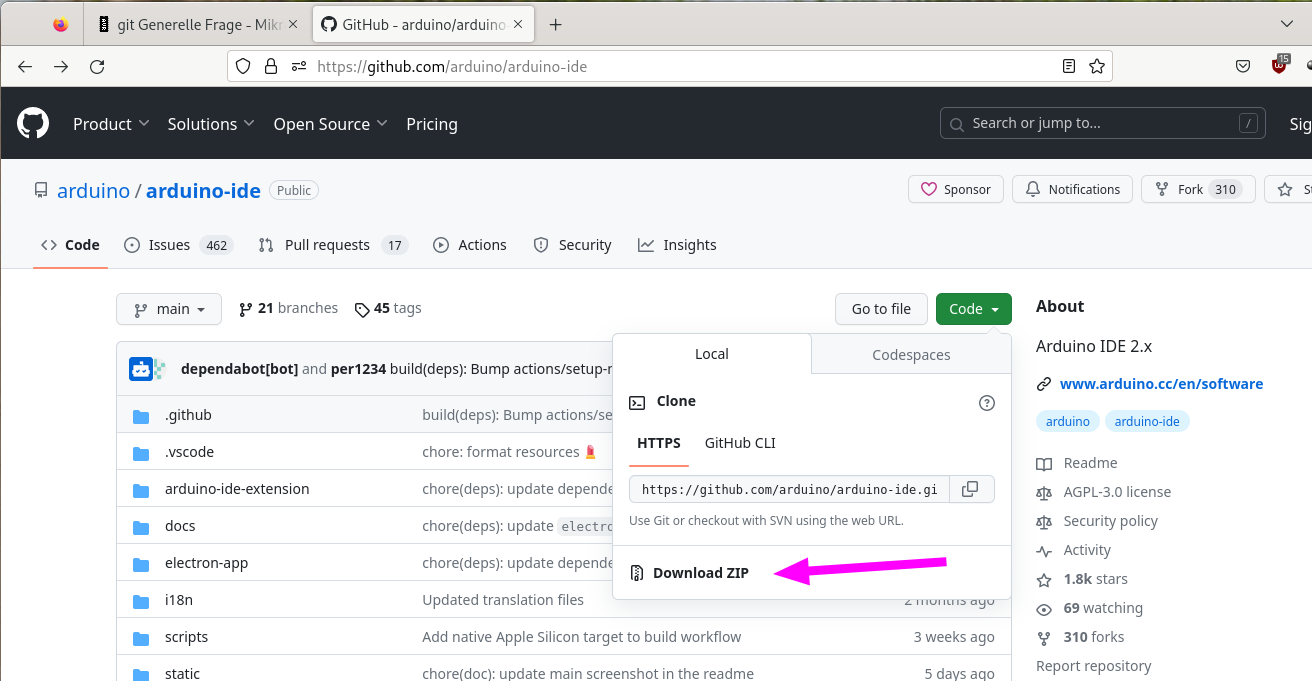
Dieterich schrieb: > Ziemlich frecher persönlicher Angriff, den du da nochmal ablieferst > (eventuell meine Beiträge mal genau durchlesen und verstehen...). Nun, tatsächlich bietet Github seine Repositories auch als Archive im weit verbreiteten ZIP-Dateiformat an. Schau bitte mal auf folgendes Repository: https://github.com/gofiber/fiber -- wenn Du diese Webseite aufrufst, gibts oben links ein Dropdown-Menü mit der Aufschrift "<> Code". Wenn Du dieses Dropdownmenü öffnest, findest Du auf der linken Registerkarte "Load" zwar zunächst die (für Entwickler wesentlich komfortableren) Möglichkeiten des Downloads über git(1), aber darunter auch ein Feld, das mit "Download ZIP" beschriftet ist und Dir genau das liefert: ein ZIP-Archiv. Mir persönlich fällt gerade beim besten Willen keine Möglichkeit ein, wie man das noch komfortabler gestalten kann: nach zwei Klicks startet der Download.
Ein T. schrieb: > Mir persönlich fällt gerade beim besten Willen > keine Möglichkeit ein, wie man das noch komfortabler gestalten kann: > nach zwei Klicks startet der Download. Es sind zwei Klicks. Zwei! Und man sieht nicht sofort einen großen, freundlichen Button mit der Beschriftung "Download". Welche Lebenszeit da verloren geht, zwei Klicks! Das nutzt ja die Maus ab wie nix, da ist ja so ein Captcha-Ding wo man Hydranten oder lächelnde Hunde anklicken soll, noch harmlos gegen ...
Harald K. schrieb: > Es sind zwei Klicks. Zwei! Und man sieht nicht sofort einen großen, > freundlichen Button mit der Beschriftung "Download". Unabhängig von der Ironie: Weil GitHub ein Dienst für Entwickler ist, nicht für Anwender. Webseiten für Anwender sind insgesamt anders gestaltet und da kann man problemlos einen Download Link platzieren, der direkt zum ZIP File führt, ohne dass der Anwender diese GitHub Seite überhaupt anschauen muss. Allerdings leuchtet mir immer noch nicht ein, was der gewöhnliche Anwender mit dem ZIP vom Quelltext anfangen soll.
Stefan F. schrieb: > Allerdings leuchtet mir immer noch nicht ein, was der gewöhnliche > Anwender mit dem ZIP vom Quelltext anfangen soll. Niemand hindert die Nutzer von github-repositories, dort auch Binaries unterzubringen. Schon gesehen, das gibts. Manche verlinken die dann einzeln (so daß man sie ohne Sourcen etc. herunterladen kann), manche machen das aber auch nicht. So what.
Harald K. schrieb: > Niemand hindert die Nutzer von github-repositories, dort auch Binaries > unterzubringen. Dem Dieterich, geht es aber um den Download der Quelltexte. Das ist ihm bei GitHub zu kompliziert gestaltet. Das ist der Punkt, um den gerade diskutiert wird.
Hallo Nein darum geht es mir nicht -interessant was du so zu wissen meinst. Auch wenn es für dich scheinbar unvorstellbar ist: Mich und wohl auch den TO interessieren "einfach so" die Hintergründe - ich bin in der Lage, das ZIP File und den für mich wichtigen Download zu erkennen und nutzen. Man (der TO, ich) sieht etwas im Zusammenhang mit einem Programm Download - das ich zwar für den reinen Nutzen nicht benötige, das aber trotzdem meine Neugier und Interesse (Wie, warum, was ist das,...) weckt. Da mal eine deutliche, wenn natürlich auch nur oberflächliche (aber vollkommen ausreichende) verständliche Erklärung zu erhalten ist doch was Schönes und nützliches. Ich bin halt, zumindest bei den im weitesten Sinne technischen Bereichen, nicht der, wer etwas einfach nutzt ohne sich über die Hintergründe wenigstens ganz grob aus echten Interesse und Neugier zu informieren. Für mich als mehr oder weniger ausgeprägten Nerd gehört das einfach dazu. Scheinbar ist das für so manchen tatsächlich unvorstellbar - kein Problem- nur hätte ich von Leuten die sich in diesen Forum herumtreiben, ähnliches Grundinteresse und eine generelle technische Neugier, einfach so und immer, erwartet...
Dieterich schrieb: > Nein darum geht es mir nicht -interessant was du so zu wissen meinst. Dann sei doch bitte so nett und beantworte meine Rückfrage. Stefan F. schrieb: > Vielleicht haben wir unterschiedliche Projekte im Sinn. Nenne mal ein > konkretes Beispiel für Dieterich schrieb: > Aber als Anwender von so mancher Open Source Software oder fast immer, > wenn es um den Sourcecode für fertige Nachbau µC Projekte geht, erfolgt > der "Download" via GitHub und ähnlichen Systemen und eben nicht über > einen normalen Download (oder den für Windowsnutzer seltsamen > Paketsystemen in der Linuxwelt). Du kannst das Missverständnis einfach korrigieren, wenn du daran Interesse hast.
wenn es um Sourcecode geht, dann ist der Zip Download einfach Mist und konträr zur Versionskontrolle. Aber das gibt es wahrscheinlich weil nicht jeder git nutzen möchte. Mit dem Zipfile lädt man nur den ausgewählten Branch herunter. Wenn man einen anderen möchte, dann muss man den etwas weiter links in der Zeile erstmal auswählen und dann den Zip Download starten. Mit 'git clone' holt man das gesamte Repo mit allen Branches/Versionen und kann die umschalten. Mit git clients auch bequem mit zwei Klicks. Und auch das Repo aktualisieren kostet nur einen Klick, kein erneutes Zip holen, auspacken, drüberkopieren.
Git ist eigentlich ganz einfach. Ein Commit ist einfach ein Arbeitszustand. Ein Commit kann Vorgänger Commits haben, also vorherige Zustände, das ist die Historie. Jeder Commit hat einen Hash, das ist dort eine eindeutige ID mit dem man sich auf einen bestimmten Commit beziehen kann. Und dann kann man sich mit Branches und Tags einzelne Commits markieren. Die Tags lässt man in der regel auf dem Commit, wo man sie ursprünglich gesetzt hat. Die Branches hat man dort, wo man gerade arbeitet oder später vielleicht noch weiter macht, ein wichtiger aktueller Arbeitszustand. In der regel hat man einen aktiven Branch "ausgecheckt", auf dem man gerade arbeitet *. Macht man einen neuen oder so Commit, schiebt git den aktiven Branch auf den neuen weiter. Das ganze gibt es in jedem Repo, lokal, und Remote (auf dem Server). Man kann sich in seinem repo mehrere Remotes eintragen, also andere Repos. Mit "git push" kann man seine neuen Commits von einem seiner eigenen Branches auf in ein anderes Repo pushen. "git pull" ist das umgekehrte, macht aber etwas mehr, nämlich fetch & merge. "git fetch" holt sich die Commits vom remote Repo, und die Infos, was für Branches es auf dem Remote gibt. Mit "git merge" kann man die neuen Commits von einem anderen Branch übernehmen. Falls die 2 Branches beide Commits haben, die nicht im anderen sind, hat man einen merge Konflikt. "git merge" unterstützt da mehrere Lösungen. ff-only (fast forward only) Ist zu empfehlen. Da wird einfach abgebrochen. Alternativ kommt beim Mergen man in einen Zustand, wo man 2 oder mehr Vorgänger commits hat, und der Merge aktiv ist. Man kann den Notfalls auch wieder abbrechen. Man kann von Dateien eine der Versionen auschecken, oder man kann schauen, welche Änderungen es in einer Datei gab (man sieht die dann beide in der Datei). Wenn man dann die Datei angepasst hat, das die richtigen Teile drin sind, kann man die wider mit "git add" hinzufügen, und den Merge beenden. Falls nur unterschiedliche Dateien bearbeitet wurden, kann git das Mergen auch voll automatisch machen. Nach dem Merge gibt es so oder so dann einen merge commit, mit allen vorherigen Commits als Vorgänger. Die merge commits sind unschön. Leute tendieren dazu, wild zwischen Branchs hin und her zu Mergen, und deren Historie ist dann nie gleich, weil die an unterschiedlichen Orten merge commits haben. Meistens besser ist "git rebase -i". Da nimmt man den anderen Branch, und schiebt seine neuen Commits hinten drauf. Man kann dann auch noch auswählen, welche Commits / Änderungen will ich überhaupt, welche fasse ich zusammen, usw. Am Ende hat man dann eine schön gerade, konsistente Historie. "git rebase" ist der Unterschied zwischen denen, die Git verwenden, und denen, die Git beherrschen. Dann gibt es noch "git reset". Das setzt den aktuell den Branch auf einen anderen Commit, was praktisch ist, wenn man scheisse gebaut hat, und wieder auf einen vorherigen Stand will. Und eine wichtige Sache hab muss du noch wissen. Wie man Commits überhaupt erstellt. Mit "git add" kopiert man eine Datei ins staging area. "git restore" macht es rückgängig. Und "git commit" nimmt den momentanen Commit, und die Dateien im staging area, und macht einen neuen Commit. Um nachzusehen, was im Repo gerade los ist, gibt es "git status", "git log", "git branch -a", und "git tag". Und zum Vergleichen von Dateien, auch zwischen Comits wenn man will "git diff". Und "git show" um einfach eine Datei oder einen Commit anzuzeigen. Und das ist alles, was man zu git wissen muss. * Hat man keinen aktiven Branch, sondern einfach nur irgend einen Commit aufgesteckt, nennt sich das ein "detache HEAD", der HEAD ist der momentan aktive Commit und/oder branch. Der, dessen Dateien im momentanen workdir ausgecheckt sind (von denen man auch mehrere haben kann).
J. S. schrieb: > wenn es um Sourcecode geht, dann ist der Zip Download einfach Mist und > konträr zur Versionskontrolle. Aber das gibt es wahrscheinlich weil > nicht jeder git nutzen möchte. Git braucht man nur, wenn man selbst an dem Projekt mitentwickeln oder es zumindest immer lokal aktuell halten will. Wenn man einfach nur eine bestimmte Version runterladen möchte, reicht es, sich das zip zu holen. Dann braucht man sich mit git gar nicht erst auseinanderzusetzen. > Mit dem Zipfile lädt man nur den ausgewählten Branch herunter. Man lädt keinen Branch, sondern nur einen ganz spezifischen Stand runter, in der Regel den neuesten des ausgewählten Branches. Daniel A. schrieb: > Git ist eigentlich ganz einfach. Gute Erklärung. Eine Anmerkung: > Ein Commit ist einfach ein Arbeitszustand. Ein Commit ist eine Änderung des Arbeitszustandes - quasi ein diff zwischen zwei Ständen. Leider gibt es bei git keine Kennung für einen ganz bestimmten Zustand, wie es das bei svn gibt.
Daniel A. schrieb: > Git ist eigentlich ganz einfach. > [...] > Und das ist alles, was man zu git wissen muss. Ich bin mir sicher, ein git-Anfänger hätte mit deiner "Anleitung" seine Freude ;-)
Le X. schrieb: > Ich bin mir sicher, ein git-Anfänger hätte mit deiner "Anleitung" seine > Freude ;-) Es reicht sicherlich nicht aus, damit der Anfänger zum Profi wird, aber es ist ein guter Überblick über alle wichtigen Funktionen von git. Für die Anwendung muss man es sich dann aber noch etwas detaillierter und mit Beispielen anschauen. Das würde aber den Rahmen eines µC.net-Beitrags sprengen.
Rolf M. schrieb: > , aber es ist ein guter Überblick über alle wichtigen Funktionen von git Für jemanden, der wissen will, was git eigentlich ist, geht es aber meilenweit an der Frage vorbei. Und ob es als Zusammenfassung "gut" ist, keine Ahnung. Klingt wie eine grobe Übersetzung von zB https://git-scm.com/docs/gittutorial
Klaus schrieb: > Rolf M. schrieb: >> , aber es ist ein guter Überblick über alle wichtigen Funktionen von git > > Für jemanden, der wissen will, was git eigentlich ist, geht es aber > meilenweit an der Frage vorbei. Die Frage war: Esmu P. schrieb: > Was ist das? Und wie benutzt man es? Die Antwort sagt, wie man es benutzt, passt also perfekt zur Frage.
Hallo Daniel A. schrieb: > Git ist eigentlich ganz einfach. Daniel A. schrieb: > Ein Commit ist einfach ein > Arbeitszustand. Ein Commit kann Vorgänger Commits haben, also vorherige > Zustände, das ist die Historie. Jeder Commit hat einen Hash, das ist > dort eine eindeutige ID mit dem man sich auf einen bestimmten Commit > beziehen kann. Und dann kann man sich mit Branches und Tags einzelne > Commits markieren. Alles Commit ähh klar ? Ist die Ironie beabsichtigt? Wenn ja, versuche es mal als Schriftsteller, über einen potenten Nachfolger von Terry Pratchett (RIP) würden sich sehr viele freuen - er, sein Humor, sein Sprachwitz und die Beobachtungsgabe des Verhaltens von uns allen fehlt immer noch schmerzlich
Rolf M. schrieb: >> Mit dem Zipfile lädt man nur den ausgewählten Branch herunter. > > Man lädt keinen Branch, sondern nur einen ganz spezifischen Stand > runter, in der Regel den neuesten des ausgewählten Branches. so ist es korrekter ausgedrückt, aber ich finde es trotzdem Mist. Die Zifpfiles haben unabhängig vom Stand immer den gleichen Namen. Ein zip vom main heißt immer repo-main.zip. Wenn ich es heute herunterlade hat es den aktuellen Stand. Nach einem Tag, Woche oder Jahr hat es den gleichen Namen, aber eventuell hat sich einiges geändert. Und da ist es schon interessant was sich geändert hat. Im Zip ist auch kein Verweis auf den Versionsstand. Ja, wenn der Autor Versionen hinzugefügt hat, dann kann man die gezielt auswählen und herunterladen (auch über den Link 'Tags'), dann hat das zip auch den entsprechenden Namen. Aber wer weiß das und macht das so? Natürlich kann man im Repo auch eine Versionsdatei einbauen. Arduino Libs haben so eine Beschreibungsdatei, aber das die immer aktuell ist, das ist Glücksache bzw. hängt von der Sorgfalt des Entwicklers ab. Und da gibt es genug Beispiele wo das nicht passt. Und das alles nur weil ein 'git clone' zu kompliziert sein soll?
J. S. schrieb: > Und das alles nur weil ein 'git clone' zu kompliziert sein soll? Du gehst von dir selbst aus als jemand, der git kennt und regelmäßig benutzt. Aber nicht jeder weiß was git ist und hat es schon von vorne herein installiert. Das heißt, viele müssen erst mal herausfinden, was sie mit diesem Link überhaupt tun müssen. Dann erkennen sie ggf, dass sie erst ein Tool namens git finden, runterladen und installieren müssen. Als nächstes muss dann rausgefunden werden, dass eben ein 'git clone' auf der Konsole (die schon oft eine Herausforderung für sich ist) ausgeführt werden muss. Und da ist eigentlich die Frage, warum man diesen ganzen Bohei braucht, nur um den Code runterzuladen, schon fast zu erwarten.
Rolf M. schrieb: > J. S. schrieb: >> Und das alles nur weil ein 'git clone' zu kompliziert sein soll? > > Du gehst von dir selbst aus als jemand, der git kennt und regelmäßig > benutzt. Aber nicht jeder weiß was git ist und hat es schon von vorne > herein installiert. Das heißt, viele müssen erst mal herausfinden, was > sie mit diesem Link überhaupt tun müssen. Dann erkennen sie ggf, dass > sie erst ein Tool namens git finden, runterladen und installieren > müssen. Als nächstes muss dann rausgefunden werden, dass eben ein 'git > clone' auf der Konsole (die schon oft eine Herausforderung für sich ist) > ausgeführt werden muss. Und da ist eigentlich die Frage, warum man > diesen ganzen Bohei braucht, nur um den Code runterzuladen, schon fast > zu erwarten. Hm, Rolf, ich weiß ja nicht... Wer will denn Code herunterladen? Doch wohl nur jene, die etwas damit anfangen können, mithin: Entwickler. Software-Quellcode richtet sich nicht an Endbenutzer, sie sind nicht die Zielgruppe. Und so eine Plattform wie Github, Sourceforge oder Gitlab richtet sich ebenfalls nicht an Endbenutzer, das sind Kollaborationsplattformen für? Genau, Entwickler. Und zwar nicht an jene Entwickler, die nicht zumindest einmal gehört hat, was git ist, die keine Kommandozeile bedienen und und sich die nötigen Fertigkeiten zum Download der Quelltexte nicht schnell aneignen kann. Insofern sollten wir bei dieser Debatte vielleicht auch einfach mal die Ziele und die Zielgruppe solcher Angebote betrachten. Für die Unbedarften gibt es trotzdem noch die Möglichkeit eines Zipfile, auch wenn diese Möglichkeit aus Entwicklersicht natürlich eher suboptimal ist. Daher können wir vielleicht kritisieren, daß das Userinterface (zwei Klicks!) für Endbenutzer eventuell nicht ideal gestaltet ist, aber dennoch: Endbenutzer sind schließlich nicht die Zielgruppe der ganzen Veranstaltung. Man kann und muß schließlich nicht jedem Recht machen. Es geht darum, die Zielgruppe zu erreichen, und für die gehören git und ähnliche Werkzeuge zum täglichen Brot.
Hallo Rolf M. schrieb: > Du gehst von dir selbst aus als jemand, der git kennt und regelmäßig > benutzt. Aber nicht jeder weiß was git ist und hat es schon von vorne > herein installiert. Das ist unabhängig von git das Kernproblem vieler "Spezialisten" und Insider - sie sind nicht in der Lage (ein böser Wille und gezieltes Heraushalten von Neulingen scheint nicht dahinterzustecken) sich in Anfänger hineinzuversetzen. Auch wenn sich viele "Könner" und Nerds darüber lustig machen: So wie Computerbild Programme, Anwendungen und zum Teil auch Hardware Schrittchen für Schrittchen -durchaus auch mit Screenshots und Videos erklärt, ist genau die richtige Art Leuten, die bei (nahezu) Null anfangen etwas zu erklären. Ja, wenn man dann etwas Ahnung (speziell, aber auch generell) hat, dann sind Teile solcher Anleitung nervig bis für einen selbst lächerlich - aber niemals vergessen, wie man selbst angefangen hat, bzw. dass eine eigene Begabung eben nicht bei allen vorhanden ist. Nerds und Speziallisten neigen leider zu einer verschulten "Erklärung" schon bei der Grundlagenvermittlung, wobei es bei so einigen Themen auch nahezu unmöglich ist eine gute Erklärung zu geben. (Mein Dauerbrenner: OOP in Bezug auf µC und "Arduinoprogrammierung" =>Nie eine wirklich eingängige Erklärung und Darstellung der Vorteile in der Praxis gefunden - dafür z.B. irgendwas mit farbigen Autos verschiedener Leistungsklassen und ähnlichen "Quatsch" häää was soll das? Erst nach Durchlesen vieler Artikel und es "einfach" nachvollziehen hat es irgendwann "Klick" gemacht und alles hat seinen Sinn bekommen. Was den Klick aber ausgelöst hat, kann ich nicht sagen und mein jetzt vorhandenes Wissen könnte ich auch nicht einsteigerfreundlich und ohne (scheinbar) abstruse Realität und anwendungsferne Beispiele erklären.
Rolf M. schrieb: > Du gehst von dir selbst aus als jemand, der git kennt und regelmäßig > benutzt. Ja, aber ich bin nicht mit diesem Wissen auf die Welt gekommen und oh Wunder, musste mich da erstmal einarbeiten und es lieben lernen. Ich bin studierter Informatiker, aber programmieren im Studium war am IBM Terminal Lochkarten mit PL/1 Code zu stanzen, Lochkarten abgeben, und Tage später den Ausdruck vom Batch Job abholen. Von Versionskontrolle hat nicht mal jemand geträumt. Dann kenne ich das Zip Chaos zur Genüge, und Freitags wusste ich meist nicht mehr was im Zip vom Montag drin war. Ich konnte mich auch nicht mit den Versionskontrollsystemen wie SourceSafe oder SVN anfreunden obwohl die bei uns schon lange genutzt wurden. Erst mit der Team Arbeit an einem größeren Projekt und der Hilfe von jemandem daraus hat es mir richtig Freude gemacht. Ich preise das git gerne etwas provokant an, aber nicht um anderen zu sagen wie dumm sie sind, sondern es soll etwas zum überlegen anregen und ich möchte eher zum Einstieg ermutigen. >Aber nicht jeder weiß was git ist und hat es schon von vorne > herein installiert. ja, aber wer kann nicht Software installieren? Wenn es daran scheitert sollte der Computer gar nicht erst eingeschaltet werden. Unter Windows gibt es git als 'normalen' Installer, oder es gibt auch lange schon eine Packetverwaltung Winget über die es in der Kommandozeile mit 'winget install git.git' installiert werden kann. Ja, die böse Kommandozeile: viele wollen ja mittlerweile auch in Linux einsteigen, zur Weiterbildung ist ein Grundkurs/Tutorial zur Kommandozeile auch empfehlenswert. Dann finde ich Erklärungen zu git nicht gut die einen in einem Absatz sofort mit den ganzen Fremdworten erschlagen. Da fällt sofort die Klappe, das ist für Profi Entwickler, das brauche ich nicht. Sehr falsch. Deshalb habe ich geschrieben klein anfangen, aus einem Arbeitsverzeichnis ein Repo machen mit git init und erst nur das Kapitel mit dem git commit (Arbeitsstand sichern) zu beschäftigen. Es gibt viele Tutorials auf YT oder das schon genannte git Buch sind gut. Die ersten Kapitel lesen und die Kommandos selber eintippen, da sind nicht die 500 Seiten nötig. Noch mal warum: Marlin für 3D Drucker kennen sicher viele, für Anpassungen an eigene Drucker musste man ein Configuration.h ändern und das kompilieren. War mit Arduino einfach, haben viele hinbekommen. Das Problem war eher das herumprobieren an den vielen Einstellungen und die Frage was habe ich jetzt alles geändert... Wenn man das Marlin jetzt über git clone geholt hat anstatt über das zip, dann konnte man über git das schon entschärfen. Für seine Spielwiese das Projekt kopieren, aber nicht mit copy, sondern durch eine Verwzweigung, englisch branch. Mit einer IDE wie VSC geht das einfach und mit einem Klick kann man jetzt zwischen den Versionen umschalten. Nach einer Änderung sichert man diese mit einem commit und einem Kommentar dazu. So kann man auch nach Monaten schnell wieder sehen was geändert wurde (über die git Historie die auch mit einem Klick schnell angezeigt werden kann). Ist nur ein einfaches Beispiel, aber dafür muss ich kein Vollzeit Entwickler sein um so ein Werkzeug zu nutzen.
Dieterich schrieb: > Das ist unabhängig von git das Kernproblem vieler "Spezialisten" und > Insider - sie sind nicht in der Lage (ein böser Wille und gezieltes > Heraushalten von Neulingen scheint nicht dahinterzustecken) sich in > Anfänger hineinzuversetzen. Das ist auch nicht ihre Aufgabe. > So wie Computerbild Programme, Anwendungen und zum Teil auch Hardware > Schrittchen für Schrittchen -durchaus auch mit Screenshots und Videos > erklärt, ist genau die richtige Art Leuten, die bei (nahezu) Null > anfangen etwas zu erklären. Genau deswegen gibt es die Computerbild und ähnliche Publikationen. GitHub und ähnliche gehören aber nicht dazu, sie haben eine andere Aufgabe und könnten sie bei Weitem nicht mehr so gut erfüllen, wenn die Nutzer bei jedem Schritt auf die Bedürfnisse von Anfängern und Einsteigern eingeben müßten.
Dieterich schrieb: > Nie eine wirklich eingängige Erklärung und Darstellung der > Vorteile (von OOP) in der Praxis gefunden Muss OOP denn Vorteile bieten? Muss ein Hammer Vorteile haben? Oder ein Küchenmesser? Manche Dinge kann man als Anfänger auch einfach mal als vorgegeben akzeptieren. Wenn man Erfahrung mit mehreren Alternativen gesammelt hat, kann man dann über Vor- und Nachteile diskutieren. Das ist kein gutes Thema für Anfänger.
Stefan F. schrieb: > Muss OOP denn Vorteile bieten? Muss ein Hammer Vorteile haben? Oder ein > Küchenmesser? Wenn ich es gewohnt bin, mit der Zange die Nägel aus dem Brett zu ziehen oder mit der Schere das Geschenkpapier zu schneiden, darf ich das Konzept Hammer und Küchenmesser für meine (!) Zwecke schon hinterfragen. Genau das ist gemeint, wenn es darum gehen soll, dem Fragenden auf seiner Ebene zu begegnen.
Jörg R. schrieb: > Esmu P. schrieb: >> Was ist das? Und wie benutzt man es? > > Nur im dunklen und ohne Zucker. > > Diese dahingerotzten Threads werden langsam zur Pest;-( > > Am besten über /dev null ins Delete verschieben. Kann man diesen Mist von Jörg R. nicht einfach in die Tonne schieben liebe Moderatoren?
Dieterich schrieb: > Aber auch als "nur" mit einem µC hantierender Bastler der ein Projekt > nachbaut und jemand der gerne quelloffene und kostenlose Software > ("Open-Source") nutzt, kommt man halt ganz schnell mit GitHub und > ähnliches in Verbindung - und sei es nur durch einen Link. > > Da fragt man sich als reiner Anwender schon: > > Warum so komisch, warum gibt es da ganze Ordner, was soll das? > Ich möchte doch nur den Download, den hex code, den fertigen Sketch...?! > Warum die "1001" anderen Dateien, die doch "keiner" braucht? Welcher "reiner Anwender" baut sich den µC-Schaltungen auf? > Warum macht der Autor (dass es oft ein Team ist und oft aus Profis mit > entsprechendem Background und Workflow aus dem Arbeitsleben besteht, ist > halt oft viel zu fern, von der "Welt" des einfachen Anwenders und > Freizeit µC Nutzers - ja nicht nur bei "Nerds" ist der Horizont nun mal > begrenzt und das meist ganz ohne bösen Willen) es sich scheinbar so > schwer und "komisch" ? Ganz einfach: Der Autor schreibt seinen Code primär für sich selbst, und er hat ja das Verständnis. Dann macht er den Code öffentlich verfügbar, damit andere, die vielleicht auch was damit anfangen können, in auch nutzen und ggf. auch sich an der Weiterentwicklung beteiligen können. Seine "Zielgruppe" hat also kein Problem damit, git zu verstehen. Welche Motivation hätte er denn jetzt, zusätzlichen Aufwand zu betreiben, nur damit "reine Anwender" das mit drei Klicks und ohne jegliches Wissen ans Laufen bekommen? Man kann natürlich hoffen, dass er so nett ist, aber sich beschweren, wenn nicht, ist dann doch unrealistisch. > Kolja L. schrieb: >> Ich habe sehr oft das Gefühl, das viele Antworten den Fragenden nicht >> weiterbringen, obwohl sie korrekt sind. > > Das Gefühl habe ich auch - je spezieller und technischer das Thema ist, > umso mehr fällt auch mir das immer wieder auf. Das liegt in der Natur der Sache. Speziellere und technischere Themen sind halt schwieriger einem, der dem Thema fern ist, zu vermitteln.
Rolf M. schrieb: > Welche Motivation hätte er denn jetzt, zusätzlichen Aufwand zu > betreiben, nur damit "reine Anwender" das mit drei Klicks und ohne > jegliches Wissen ans Laufen bekommen? hüstel Aus meiner persönlichen Erfahrung heraus muß ich leider sagen, daß das ohnehin so eine Sache ist. Endanwender anziehen heißt nämlich, daß mehr Dokumentations- und Supportaufwand anfällt, und die dafür aufgewendete Zeit fehlt dann bei der Weiterentwicklung des Projekts, meistens ohne daß dafür im Gegenzug sinnvolle Beiträge zum Projekt entstehen. Wenn man ganz großes Pech hat, infiziert man sein Projekt sogar mit Benutzern, die... wie sage ich das... eines hohen Pflegeaufwandes bedürfen oder die alles kritisiert und es nicht einsieht, ihre Kritik an einem Geschenk freundlich und konstruktiv vorzubringen. Die kosten dann neben der Zeit auch noch Nerven, was bisweilen sogar dazu führen kann, daß Mitwirkende frustriert hinschmeißen. Davon abgesehen, mal ehrlich: wie groß ist das Interesse eines Benutzers und und wie hoch ist die Wahrscheinlichkeit, daß er konstruktive Beiträge leisten möchte, wenn er nicht einmal bereit ist, Git zu lernen? OpenSource lebt nicht von Anwendern. OpenSource lebt von Mitmachern. Edit: Typo (Der Dativ ist dem Genitiv ihm sein Tod.)
Rolf M. schrieb: > J. S. schrieb: >> Ein Commit ist einfach ein Arbeitszustand. > > Ein Commit ist eine Änderung des Arbeitszustandes - quasi ein diff > zwischen zwei Ständen. Konzeptionell in Git ein Commit tatsächlich ein bestimmter (Arbeits-)Zustand des Dateibaums.[1] Meiner Erinnerung nach waren das in den frühen Stadien tatsächlich nur versionierte Dateibäume, was sich mithilfe von Hardlinks ja auch schon recht effizient implementieren lässt. Heute speichert das die darunter liegende Datenbank natürlich etwas cleverer (implementation detail). [1] https://git-scm.com/book/en/v2/Getting-Started-What-is-Git%3F
Marcus H. schrieb: > Rolf M. schrieb: >> J. S. schrieb: >>> Ein Commit ist einfach ein Arbeitszustand. >> >> Ein Commit ist eine Änderung des Arbeitszustandes - quasi ein diff >> zwischen zwei Ständen. > > Konzeptionell in Git ein Commit tatsächlich ein bestimmter > (Arbeits-)Zustand des Dateibaums.[1] Eigentlich nicht, denn man kann nachträglich vor dem Commit noch einen andren Commit einfügen oder einen älteren Commit ändern, und dann ändert sich der Stand im Nachhinein, ohne dass am Commit selbst was geändert wurde. Siehe z.B. https://printf2linux.wordpress.com/2012/04/09/insert-a-commit-in-the-past-git/ Der Commit benennt nur die Änderung, nicht den kompletten Stand, den das Repo nach ihr hat.
Rolf M. schrieb: > Marcus H. schrieb: >> Rolf M. schrieb: >>> J. S. schrieb: >>>> Ein Commit ist einfach ein Arbeitszustand. >>> >>> Ein Commit ist eine Änderung des Arbeitszustandes - quasi ein diff >>> zwischen zwei Ständen. >> >> Konzeptionell in Git ein Commit tatsächlich ein bestimmter >> (Arbeits-)Zustand des Dateibaums.[1] > > Eigentlich nicht, denn man kann nachträglich vor dem Commit noch einen > andren Commit einfügen oder einen älteren Commit ändern, und dann ändert > sich der Stand im Nachhinein, ohne dass am Commit selbst was geändert > wurde. Dabei ändert sich die commit ID der nachfolgenden commits, man könnte also sagen, das es dann nicht mehr die selben commits sind. Mit der alten commit ID kann man sogar weiterhin auf den alten stand / Commits zurück, solange die Objekte noch nicht weggeräumt wurden. Bezüglich dessen, ob jetzt Commits ein Zustand oder eine Änderung dessen sind, würde ich es einfach so betrachten, dass Commits konzeptionell beides sind. Es kommt halt darauf an, wie man es betrachten will. Wenn ich ein Rebase mache, oder commits cherry-picke, bin ich an den Änderungen interessiert. Wenn ich einen Commit auschecke, bin ich am Zustand interessiert, den ich dort hatte. Technisch gesehen sind Zustandsänderungen einfach der Unterschied zwischen Zuständen. Und ich denke in der Praxis ist es wenig Sinnvoll, sich über alle Änderungen die man je gemacht hat Gedanken zu machen. Ich denke, git ist in der Verwendung hier ziemlich intuitiv. Technisch gesehen sind es Zustände. Aber wenn man einen Zustand braucht, kann man ihn haben, und wenn man eine Zustandsänderung will, bekommt man die auch. Solange man nicht darüber nachdenkt, gibt es auch kein Problem.
J. S. schrieb: > Aber wer weiß das und macht das so? Hallo hier, ich. Vielleicht bin ich ja dumm, bitte urteile selbst. Wenn Du es Richtig (tm) machen willst, dann lern und benutz Git.
Rolf M. schrieb: > Als nächstes muss dann rausgefunden werden, dass eben ein 'git > clone' auf der Konsole (die schon oft eine Herausforderung für sich ist) > ausgeführt werden muss. Du bringst mich um, Rolf. Es gibt also Entwickler, für die eine Kommandozeile eine "Herausforderung" ist? Uiuiui. :-)
Die meisten Smartphone Nutzer wissen ja nicht einmal, was eine Datei ist... Und irgendwoher müssen die Entwickler ja kommen. Dass kann dann schon überwältigend sein, wen sie das alles erst alles lernen müssen.
Daniel A. schrieb: > Die meisten Smartphone Nutzer wissen ja nicht einmal, was eine Datei > ist... Die meisten Nicht-Smartphone-Nutzer wissen auch nicht, was eine Datei ist.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.