Hallo! Mein FPGA hat einen Systemtakt von 20MHz. Der SPI Bus läuft mit 10MHz. Mein Slave wird aktuell nur in der Simulation verwendet, aber ich hatte mir vorgenommen ihn so zu schreiben, dass er auch synthetisierbar ist. Wenn ich nun bei meinem SPI Slave das Signal sclk korrekt 2 fach eintakte ergibt sich dadurch auf MISO eine Latenz von mindestens 2 Systemtaktzyklen bzw. einem sclk-Zyklus. Dem realen Slave der bei mir auf dem Tisch liegt schicke ich aber z.B. den Befehl "Register lesen" & "Registeradresse" und der Slave antwortet darauf ohne Latenz und schickt mir die Registerinhalte zurück. Kann ich das auch irgendwie schaffen??? Mir fällt keine gute Lösung ein die sowohl in der Simulation als auch in der Synthese läuft. Wie mach Ihr das? Haltet Ihr einen SPI Slave für Synthese und Simulation vor? Gruß, Hendrik
Wenn du der SPI-Master bist, musst du gar nicht eintackten, da der SPI-Slave ja synchrom zum SPI-Master läuft
user schrieb: > Wenn du der SPI-Master bist Isser nuja nich... ;-) Heinrich H. schrieb: > Wenn ich nun bei meinem SPI Slave das Signal sclk korrekt 2 fach > eintakte ergibt sich dadurch auf MISO eine Latenz von mindestens 2 > Systemtaktzyklen bzw. einem sclk-Zyklus. Das brauchst du nicht. Du kannst da ruhig für das Weitertakten einen lokalen Takt verwenden. Das ist ja eh' nur ein Schieberegister mit 16 oder 32 Flipflops, die werden auch auf dem normalen Routingnetz ausreichend schnell verdrahtet. Aber du musst auf jeden Fall die Übergabe/Übernahme der Daten vom und zum 20MHz-Takt synchronisieren. Und das was da synchronisiert werden muss ist der SlaveSelect. Wenn der auf der Master-Seite ausreichend lang stabil ist, wurde kein neues Bit mehr eingetaktet und das komplette Wort kann übernommen werden. Das hatten wir öfter schon mal z.B. im Beitrag "SPI: Synchron oder abtasten" Und so mache ich das im CPLD: http://www.lothar-miller.de/s9y/categories/26-SPI-Slave
Angehängte Dateien:
-

spi.jpg
120 KB
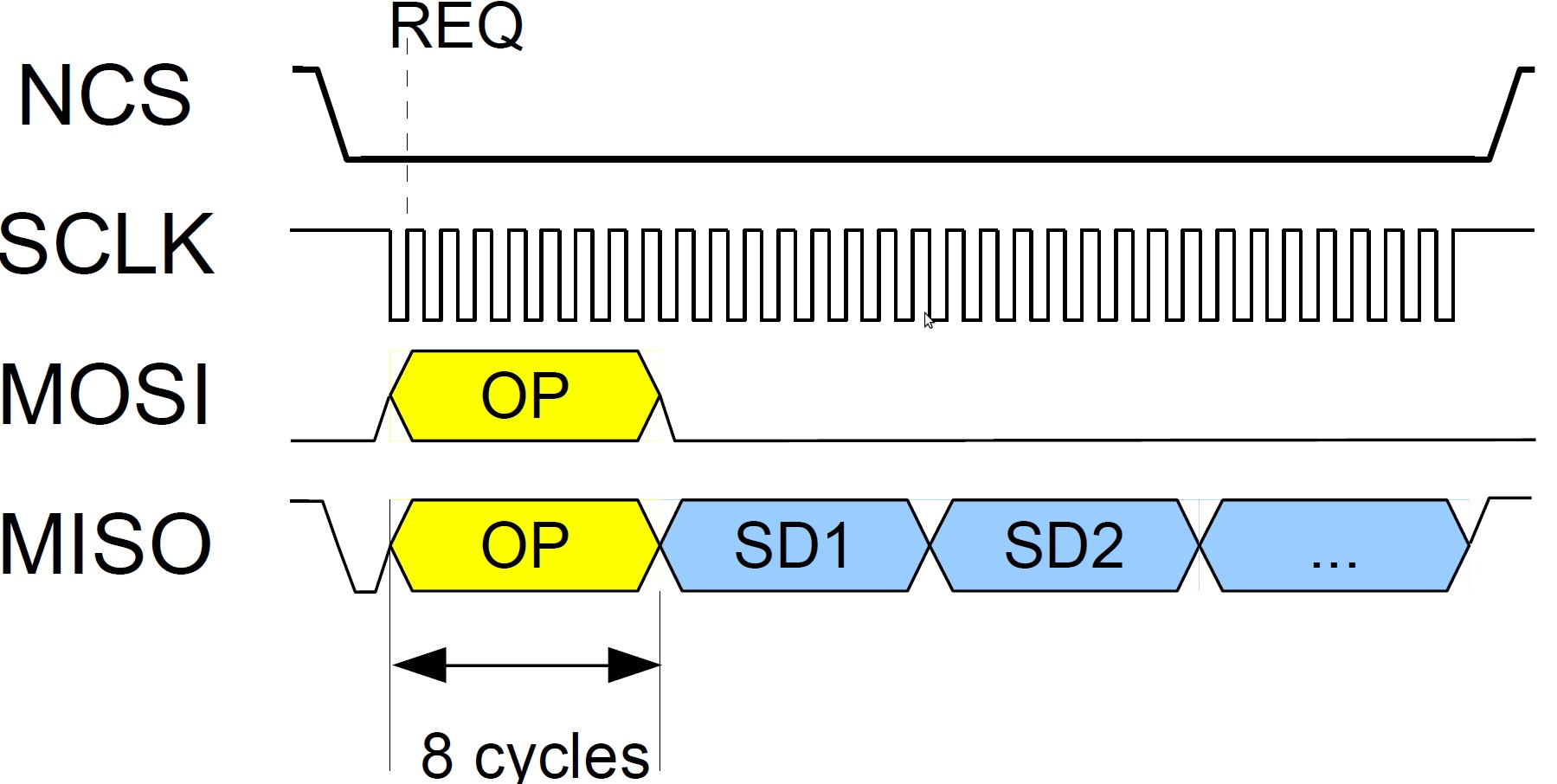
Hallo! Lothar Miller schrieb: > Das hatten wir öfter schon mal z.B. im > Beitrag "SPI: Synchron oder abtasten" Diese Aussage aus der obigen Diskussion fasst mein Problem gut zusammen: Lothar Miller schrieb: > berndl schrieb: >> Daher muss der FPGA unmittelbar auf die Daten liefern die zuvor >> durch die adressiert worden sind. Ich habe noch nen Ausschnitt aus dem Datenblatt des SPI Slave angehängt. (Es ist als "vertraulich" gekennzeichnet, sonst hätte ich es komplett angehängt). Im Ausschnitt kann man mein Problem gut erkennen. Direkt nachdem der Master den OP geschickt hat muss der Slave die Daten SD1, SD2... schicken und dabei geht NCS nicht auf High zurück. Der CPLD Slave von Lothar löst das Problem also leider auch nicht. Lothar, Du hast geantwortet: > Das ist im Grunde ein recht unschönes Konzept. Und das fasst es ganz gut zusammen. Mein Systemtakt ist einfach nicht schnell genug um auf OP angemessen schnell SD1, SD2... schicken zu können.
Heinrich H. schrieb: > nachdem der Master den OP geschickt hat muss der Slave die Daten SD1, > SD2... schicken und dabei geht NCS nicht auf High zurück. Das ist eine übliche und brauchbare Kommunikationsstruktur für einen I2C-Bus, wo ein langsamer Slave den Takt einfach anhalten darf/könnte, bis er Daten liefern kann. Sie ist aber absolut ungeeignet für einen SPI, wo dem Slave der Mastertakt aufgezwungen wird. > Mein Systemtakt ist einfach nicht schnell genug Für so einen vermurksten Ansatz hilft bestenfalls nur noch eine DLL/DCM/PLL oder sowas, die dir den Takt von 20MHz deutlich hochsetzt, so dass du wenigstens den Kommunikationsteil schnell abhandeln kannst. Wie und ob du allerdings nach dem "OP"-Kommando schnell genug an Antwortdaten (insbesondere SD1 muss ja "sofort" da sein) kommst, das steht auf einem anderen Blatt. Deshalb sollte bei SPI gelten: während das "nächste" Kommando geschickt wird, wird die "vorige" Antwort empfangen. Als Lesetipp das Datenblatt für den AD7490 (Seite 19): http://www.analog.com/static/imported-files/data_sheets/AD7490.pdf Bei diesem AD-Wandler schreibe ich jetzt den zu wandelnden Kanal und weitere Kommandobits, und bekomme gleichzeitig den bei der vorigen Übertragung ausgewählten AD-Kanal zurück.
Angehängte Dateien:
-

RDID.PNG
48 KB
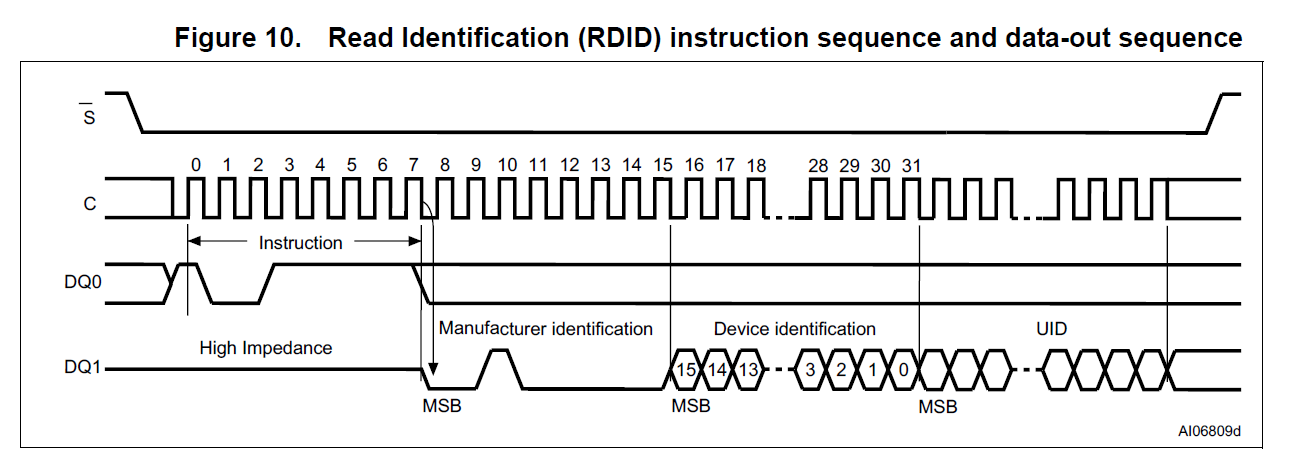
Lothar Miller schrieb: > Sie ist aber absolut ungeeignet für einen SPI, wo dem Slave der > Mastertakt aufgezwungen wird. Naja, aber das ist doch quasi Standard. Ein SPI Flash verhält sich genauso. Wenn ich dem das 0x9F ID Kommando vor den Latz knalle, kann er auch direkt im Anschluss ohne Pause seine ID auf MISO ausspucken (Aus dem DB des M25P64) ...ich denk allerdings auch, dass man in diesem Fall ohne internen schnelleren Takt nicht auskommen wird.
Angehängte Dateien:
-

m25p64_readfast.png
31 KB
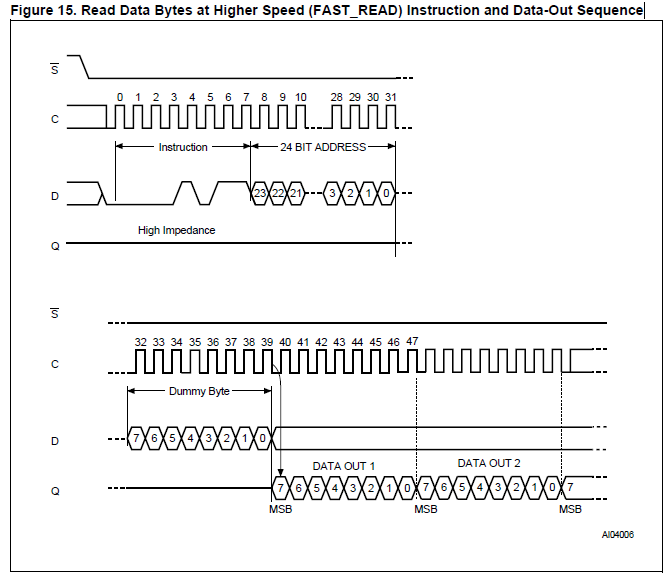
Christian R. schrieb: > kann er auch direkt im Anschluss ... seine ID auf MISO ausspucken Die ID ist ja auch recht statisch, und auch das Statusregister ist immer am selben Platz. Interessant wirds dann schon beim Lesen von Daten, und da kommt dann irgendwann das Bild 15 zum tragen: ein Dummybyte zum Datenholen...
Lothar Miller schrieb: > ein Dummybyte zum > Datenholen... Aber auch nur beim FastRead. Bei niedrigerem Takt schafft er auch mit 0x03 Read die Daten direkt im Anschluss. Aber lassen wir das Haarespalten :)
Lothar Miller schrieb: > Sie ist aber absolut ungeeignet für einen SPI, wo dem Slave der > Mastertakt aufgezwungen wird. > Für so einen vermurksten Ansatz Na ja, so pauschal würde ich das jetzt nicht sagen. Wenn ich weiss, wie schnell mein Slave sowas maximal kann, dann darf der Master halt nicht schneller Schieben und dann funktioniert sowas auch sehr gut. @ Heinrich Wenn du für deinen OP-Code nicht die vollen 8 Bit brauchst, sondern z.B. nur 5 Bit, dann kannst du bereits nach Empfang des 5. Bits deinen Sendespeicher entsprechend des OP-Codes laden und hast noch Zeit, bis die erste Flanke des zweiten Bytes aufschlägt. Die Schiebeoperationen können durchaus mit dem SCK direkt getaktet werden. Die Überagabe der Daten von und in den Systemtakt muss dann halt mit entsprechenden Steuersignalen durchdacht und korrekt constrained werden.
Schlumpf schrieb: > Wenn ich weiss, wie schnell mein Slave sowas maximal kann, dann darf der > Master halt nicht schneller Schieben und dann funktioniert sowas auch > sehr gut. Ja, aber nicht mit 10MHz Schiebetakt und 20MHz Sytemtakt. Das zeitliche Verweben der Lese- und Schreibzugriffe ist auch nicht sonderlich kompliziert oder softwaretechnisch wesentlich aufwendiger. Nur das Slave-Design, das wird auf diese Art unglaublich simpel... > Die Überagabe der Daten von und in den Systemtakt muss dann halt > mit entsprechenden Steuersignalen durchdacht ... werden. Genau da knackt es doch, denn da ist die Taktdomänengrenze mitten im Protokoll. Der OP kann "asynchron" empfangen werden, muss dann aber in weniger als 1 20MHz-Takt übernommen werden können. Das mit den 5 Bit OP statt 8 Bit ist dann nur noch die Spitze des Eisbergs...
Lothar Miller schrieb: > Für so einen vermurksten Ansatz hilft bestenfalls nur noch eine > DLL/DCM/PLL oder sowas Das hatte ich auch überlegt... aber ich finde das ist wie mit den Kanonen auf Spatzen.
Schlumpf schrieb: > @ Heinrich > Wenn du für deinen OP-Code nicht die vollen 8 Bit brauchst, sondern z.B. > nur 5 Bit, dann kannst du bereits nach Empfang des 5. Bits deinen > Sendespeicher entsprechend des OP-Codes laden und hast noch Zeit, bis > die erste Flanke des zweiten Bytes aufschlägt. Hatte ich auch schon gedacht, aber die OPCODES sind: 0xB0 0xA6 0xF5 0x97 0xD2 0xAD :(
Lothar Miller schrieb: > Genau da knackt es doch, denn da ist die Taktdomänengrenze mitten im > Protokoll. Der OP kann "asynchron" empfangen werden, muss dann aber in > weniger als 1 20MHz-Takt übernommen werden können. > Das mit den 5 Bit OP statt 8 Bit ist dann nur noch die Spitze des > Eisbergs... Genau da knackt es nicht, weil hier entspannt sich die Situation. Vorausgesetzt, er braucht nicht die vollen 8 Bit OP. Dann zählt ein Counter auf synchron zum SPI-Takt die Bits. Bei Bit 5 wird a) eine Kopie des aktuellen Stand des Empfangsregisters gezogen (synchron zum SPI-Takt), während im Hintergrund fleißig weitergeschoben wird. b) synchron zum SPI-Takt ein "Ready"-Impuls erzeugt. dieser Impuls wird mit 20 MHz gesampelt. Und dann hat man noch 3 10 MHz-Takte Zeit, auf der 20MHz-Domain den OP-Code aus dem KOPIERTEN Register auszulesen und darauf zu reagieren. Also ich sehe hier nach wie vor kein Problem. Aber vielleicht übersehe ich auch etwas. Aber nachdem die Opcodes das nicht ermöglichen, ist diese Methode auch nicht zielführend.
Heinrich H. schrieb: > Schlumpf schrieb: >> @ Heinrich >> Wenn du für deinen OP-Code nicht die vollen 8 Bit brauchst, sondern z.B. >> nur 5 Bit, dann kannst du bereits nach Empfang des 5. Bits deinen >> Sendespeicher entsprechend des OP-Codes laden und hast noch Zeit, bis >> die erste Flanke des zweiten Bytes aufschlägt. > > Hatte ich auch schon gedacht, aber die OPCODES sind: > 0xB0 > 0xA6 > 0xF5 > 0x97 > 0xD2 > 0xAD > :( Da das nur 6 OPs sind, kann man einfach die Daten für alle Opcodes schon beim Start des Protokols anfordern und dann nur die passenden zurückgeben. Ähnlich kann man im obigen angeführten Fall des SPI Flashes machen, 2 bit vor dem Ende des letzen Addressbytes 32 bits lesen, und dann mit den letzten 2 bits das richtige Byte auswählen. Heinrich H. schrieb: > Mein Slave wird aktuell nur in der Simulation verwendet, aber ich hatte > mir vorgenommen ihn so zu schreiben, dass er auch synthetisierbar ist. Aber wie man sieht sind solche Lösungen sehr angepasst an das vorliegende Protokol, weswegen ich das hier doch sinnlos ist, es sei denn man hat vor irgendwann genau den vorliegenden Slave selbst im FPGA zu implementieren. Ich halte es für sinnvoller ein genaues Verhaltensmodell des Slaves zu erstellen, das man bei Bedarf auch in einer P&R Timing Simulation verwenden kann. Wer weiss vielleicht bekommt ein solches Modell auch vom Hersteller des Bauteils. Micron hat z.B. solche Modelle für ihre DDR Rams und NAND Flashes.
Christian R. schrieb: > Naja, aber das ist doch quasi Standard. Ein SPI Flash verhält sich > genauso. Viele SPI haben das so, z.B. auch der Wiznet Ethernet Controller wenn man ihn denn ueber SPI ansteuert. Diese sofortige Antwort im gleichen Frame hat einen gewissen Charme, wenn die Master-SW im uC gegenueber mit einem Taskschema und DMA arbeitet. Dann sind in der naechsten Task die Daten da, nicht erst in der uebernaechsten. Macht die SW etwas einfacher... Und es gibt ja auch noch SPI Slaves, wo man mehrere Chips auf ein ChipSelect legen kann und ein paar MSBs des MOSI zur Adressierung dienen. Klingt krank, aber damit kann man z.B. Werte in vielen Slaves gleichzeitig 'freezen' und dann nacheinander auslesen. Hat auch was fuer sich. Aber solche Protokolle gehen am einfachsten mit oversampling durch eine schnelle FPGA-Clock (der einen FPGA-Clock idealerweise). Und fuer sowas verwende ich dann auch kein Schieberegister, sondern ich multiplexe die passenden Bits in einer Pipelinestruktur raus. Ist dann einfacher, als das schieben auch noch mitzuzaehlen und -zuberuecksichtigen.
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.