Hallo Leute,
ich stehe hier vor einem Problem, das ich kaum waage auszusprechen.
Mir ist mein STM32F4 mit 168MHz zu langsam um ein par Bits herum zu
schieben.
Da mach ich doch irgendetwas falsch, oder?!
mein Problem:
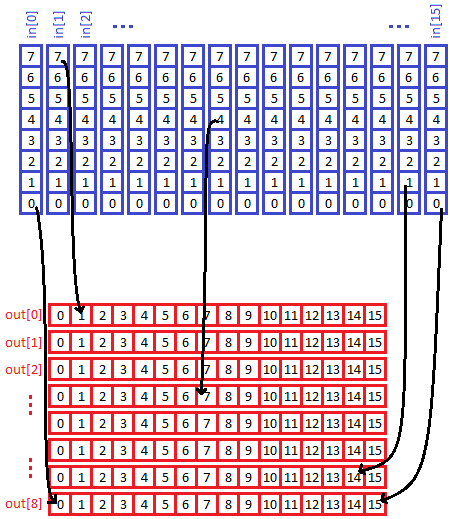
ich muss ein array aus 16 Bytes (uint8_t in[16]) in ein array aus 8
half-words (uint16_t out[8]) konvertieren, aber das so, wie ich im Bild
im Anhang hoffentlich verständlich verdeutlicht habe. Es soll je das
n-te Bit aus den 16 in-Bytes in ein out-halfword gespeichert werden.
Das "Problem" bei der Sache ist, dass der Prozessor das ganze in einem
Interrupt innerhalb von 600 Taktzyklen erledigt haben muss.
Mit dem Code unten und der Optimierung -o2 habe ich das schon fast
geschaft (0,25µs also 42 Takte fehlen noch). Nur leider ist mein
Compiler offenbar nicht immer gleich geschickt und wenn ich irgendwo
anders im Code Änderungen vornehme, dann kann es passieren, dass er auch
mal schlechter optimiert. Das klingt zwar wild, aber macht unglaublich
viel Laune auf mehr... (Schönen Gruß von der Ironie)
Der erwähnte Code:
1
externuint8_tin[16];
2
externuint16_tout[8];
3
4
uint16_tout_ptr=&out[0];
5
6
for(uint8_tin_bit=0x80;in_bit>0;in_bit>>=1)
7
{
8
uint16_ttmp_out=0xFFFF;
9
uint16_tout_bit=1;
10
for(inti=0;i<16;i++,out_bit<<=1)
11
{
12
if(in[i]&in_bit)
13
tmp_out&=~(out_bit);
14
}
15
16
*out_ptr++=tmp_out;
17
}
Ich habe auch schon im Decompilierten code (also im mit dem objdump -S
erzeugten .lss-File) gesucht und bin zu dem Schluss gekommen, dass der
Compiler nicht so recht Lust hat effizienten Code zu produzieren. Egal
was ich mache, der Compiler mags lieber Umständlich. Als Beispiel, die
äußere Schleife. Der Compiler erzeugt neben dem Bit-shift noch eine
weitere Zählervariable die bis 8 zählt und die Schleife dann beendet.
Das bedeutet ein weiteres Register wird verbraucht und zusätzliche
Rechenleistung für Initialisierung und Zählen werden verschwendet... grr
Und von den etwa 12 zu Verfügung stehenden Registern nutzt er auch nur
3-4... Das ist doch doof..
Nun nervt mich der gute Compiler ein wenig und ich stehe vor einem
kleinen Haufen Scherben. Daher frage ich, ob mir jemand einen Rat geben
kann, wie man dem Compiler in solchen Fällen ein wenig auf die Sprünge
helfen kann?
Ich bin mir nicht sicher ob ich da jetzt wirklich mit Assembler anfangen
will oder muss!? Kann doch nicht sein, dass dieser fette Mikrocontroller
mit so hohem Takt das nicht auf die Reihe bekommt?!
Kann mir vielleicht jemand behilflich sein?
Vielen Dank und
Viele liebe Grüße
Michaela
Schon mal überlegt, eine der Schleifen wegzulassen und den Kram 8- oder
16-mal hintereinander zu schreiben? Wenn du genug Flash hast evtl. auch
beide.
Jedenfalls bist du mit einer Umsortierung von 128 Bits in 600 Takten
schon ziemlich dicht an der Kante des Möglichen. Da könnte Assembler
sinnvoll sein. Dann lassen sich beide Arrays als Block aus Registern
realisieren. Rest siehe oben.
Michaela schrieb:> Mir ist mein STM32F4 mit 168MHz zu langsam um ein par Bits herum zu> schieben.
Tja für Bitschubsereien sind die ARM Cortex nicht so gemacht.
Michaela schrieb:> uint16_t out_ptr = &out[0];
Die Aus&Eingabe-Daten passen komplett in Register, aber durch deine
Pointerarithmetik erzwingst du quasi die Bearbeitung im Speicher.
Michaela schrieb:> for( uint8_t in_bit = 0x80; in_bit > 0; in_bit >>= 1 )
Bei solchen "komischen" "nicht-standard-format"-Schleifen kann der
Compiler nicht so gut erkennen was du vorhast.
Michaela schrieb:> if( in[ i ] & in_bit )> tmp_out &= ~(out_bit);
Das ist natürlich ganz schlecht, das braucht mehrere Zyklen zur
Übertragung eines einzelnen Bits.
Michaela schrieb:> dass der> Compiler nicht so recht Lust hat effizienten Code zu produzieren.
Das kann er auch kaum, da dein Code auf dem "virtuellen"
Speicher&Rechen-Modell von C aufsetzt und die Gegebenheiten der
Architektur quasi ignoriert. Da tut sich der Compiler schwer, das
effizient umzusetzen.
Michaela schrieb:> Daher frage ich, ob mir jemand einen Rat geben> kann, wie man dem Compiler in solchen Fällen ein wenig auf die Sprünge> helfen kann?
Indem du dir anschaust, was die Architektur kann, und das in C
umschreibst.
> Kann doch nicht sein, dass dieser fette Mikrocontroller> mit so hohem Takt das nicht auf die Reihe bekommt?!
Kann er auch, wenn richtig gemacht.
Ich hab mal ein bisschen was mit C++ & Inline-Assembler gebastelt, siehe
Anhang. Habs nicht getestet, aber die Disassembly sieht gut aus. Darfst
du dann ggf. debuggen... Die ARMv7M Architektur kann über die "BFI"
Instruktion die untersten n Bits eines Registers an Stelle m eines
Zielregisters kopieren, wenn die Registernummern und n,m alle konstant
sind. Das nutze ich im Code, um jedes Bit einzeln zu kopieren. Außerdem
füge ich je zwei der 16bit-Integer zu einem 32bit-Integer zusammen, die
ich dann "doppelt" per Bitshiften fülle. Dies lässt sich vom Compiler
leicht direkt auf die 32bit-Register abbilden und somit die Ausgabe
außerdem komplett in Registern halten.
Der ganze Code dürfte so in ca. ~300 Zyklen laufen (2 Zyklen pro Bit +
etwas Schleifenoverhead).
PS: Mit etwas wilder Bitshifterei ließe sich evtl. die BFI-Instruktion
komplett in "richtigem" C-Code abbilden ohne inline-assembly, s.d. der
Compiler aber dennoch ein "BFI" daraus macht. Dies sei dem Leser als
Übung überlassen... ;-)
Niklas Gürtler schrieb:> Tja für Bitschubsereien sind die ARM Cortex nicht so gemacht.
Das würde ich so nicht sagen. Letztlich läuft es komplett schleifenfrei
auf 2 Befehle pro Bit hinaus, einer davon bedingt, plus LDM davor und
STM danach. Zeig mir einen, der das viel kürzer macht. Auf nativen ARMs
sind das 2 Takte pro Bit, auf den CM3/4 möglicherweise 3 wegen der
bedingten Ausführung. Falls der STM32F4 nicht ausreichende
Flash-Bandbreite für den Code hat muss man damit evtl. ins RAM.
Wow, das ging schneller als ich es um diese Zeit erwartet habe und es
macht mir Hoffnung. Ich muss mich wirklich bei euch bedanken.
Ich sehe allerdings vor allem, dass ich noch viel zu lernen habe...
Naja, daran lässt sich ja arbeiten.
Aber könnte es sein, dass dir noch ein kleiner Fehler unterlaufen ist?
das BFI kopiert jeweils das LSB von in an die Stelle des MSB der
Ausgangsdaten. Die Schieboperationen ( out [x] <<= 1; ) schieben das Bit
dann aber aus den Ausgangsdaten raus... Dennoch Danke, ich hoffe ich
kann damit weiter Arbeiten.
Werde mich dann mal wieder ein wenig mit Google anfreunden und melde
mich definitiv wieder wenn ich nicht weiter kommen sollte.
Vielen lieben Dank!
Grüße
Michaela
A. K. schrieb:> Zeig mir einen, der das viel kürzer macht.
Es wäre ja vorstellbar, dass die lsb,width Parameter des "BFI" Befehls
auf einer anderen Architektur variabel (d.h. aus einem Register stammen)
können. Der AVR hat auch das T-Bit, mit dem kann man einzelne, aber
beliebige Bits aus einem Register in ein anderes transferieren. Der
ARMv7M kann nur das unterste, dafür aber mehrere...
A. K. schrieb:> plus LDM davor und STM danach.
Das braucht man hier nichtmals. Was willst du hier denn gleich
"multiple" loaden/storen? Das Charakteristik von "BFI" bedingt onehin
dass man byteweise vorgeht.
A. K. schrieb:> Mölicherweise 3 wegen der bedingten Ausführung.
Für BFI braucht man auch keine Bedingung
A. K. schrieb:> Falls der STM32F4 nicht ausreichende> Flash-Bandbreite für den Code hat muss man damit evtl. ins RAM.
Der hat dafür einen Instruction Cache
Michaela schrieb:> das BFI kopiert jeweils das LSB von in an die Stelle des MSB der> Ausgangsdaten. Die Schieboperationen ( out [x] <<= 1; ) schieben das Bit> dann aber aus den Ausgangsdaten raus...
Nö, die Bits werden immer an Position 15 bzw 31 im Ausgabe-Register
eingefügt, und dann nach links geshiftet. okay, im letzten
Schleifendurchlauf darf man dann nicht shiften, das war verkehrt. Man
könnte stattdessen auch einfach am Anfang der Schleife shiften...
Michaela schrieb:> Ich sehe allerdings vor allem, dass ich noch viel zu lernen habe...> Naja, daran lässt sich ja arbeiten.
Schau im ARMv7M Architecture Reference Manual, da steht alles dazu drin
was man braucht...
Michaela schrieb:> Vielen lieben Dank!
Büdde :)
Niklas Gürtler schrieb:> Das Charakteristik von "BFI" bedingt onehin> dass man byteweise vorgeht.
Weshalb?
Mit BFI sehe ich da exakt 2 Worte und 2 Takte pro Bit, mit 4 32-Bit
Registern fürs Input-Array, 4 32-Bit Registern fürs Output-Array, und
128 sequentiellen Befehlspaaren der Form
UBFX Rtemp,Rs,#S,#1
BFI Rd,Rtemp,#0,#D
Ergibt 1KB Code dafür und 256 Takte insgesamt, plus ein paar Takte Kopf
und Schwanz für die Register.
Um die 2 Takte einzuhalten muss der Fetcher ein Wort pro Takt
durchziehen können. Beim F4 bin ich da nicht im Satz, beim F1 würde der
I-Fetch den Code aus Flash etwas ausbremsen, bliebe aber noch locker im
Rahmen der 600 Takte. Wär besser es ist auch ohne Cache schnell genug,
denn ob der gross genug ist und immer brav gefüllt ist?
Niklas Gürtler schrieb:> Der AVR hat auch das T-Bit, mit dem kann man einzelne, aber> beliebige Bits aus einem Register in ein anderes transferieren. Der> ARMv7M kann nur das unterste
ARMv7M kann das exakt genauso wie AVR.
UBFX Rtemp,Rs,#S,#1 == BST Rs,S
BFI Rd,Rtemp,#D,#1 == BLD Rd,D
(gleichzeitig Fix für falschen Code oben)
Ein Déja-vu: Das Refman vom F4 gibt bei maximaler Taktfrequenz 6 Takte
pro Flashzyklus an, mit 4 Worten Breite. Also ist auch das Flash vom F4
nicht schnell genug, einen sequentiellen I-Stream aus 1-Takt 1-Wort
Befehlen durchzuziehen. Die 256+ Takte sehen folglich eher nach 400 aus,
es sei denn man legt den Code ins RAM.
A. K. schrieb:> Also ist auch das Flash vom F4> nicht schnell genug, einen sequentiellen I-Stream aus 1-Takt 1-Wort> Befehlen durchzuziehen.
Jetzt muss ich fragen, Google und das RefMan klären mich irgendwie nicht
ausreichend auf: der I-Stream ist der Datenstrom, der die
Prozessorbefehle aus dem Flash zur CPU liefert?
Darüber steht doch im RefMan, dass diese Befehle immer in 128bit-Blöcken
geladen werden, was 4 16-bit-Befehlen entspricht. Die werden im Prefetch
gepuffert und können dann mit voller Taktrate in die Pipeline des
Prozessors geschickt werden.
Was mich daran allerdings wundert, und das könnte dann vielleicht sogar
die bremse sein: Die Pipeline besteht ja aus Fetch, Decode, Execute.
Kann der Prozessor dann während dem Execute in einem Zyklus Daten aus
den Registern laden, verarbeiten und speichern, sodass im darauf
folgenden Taktzyklus bereits das Ergebnis wieder verwendet werden kann?
A. K. schrieb:> (gleichzeitig Fix für falschen Code oben)
Wie falsch? im groben ist der doch richtig oder nur das bisschen shiften
da. Wobei ich immernoch der Meinung bin, dass entweder in die andere
Richtung geshiftet werden müsste, oder bit 1 und 16 eingefügt werden
müssten. So wird Bit 31 immer eingefügt und direkt wider raus geschoben.
Oder liege ich da falsch?
A. K. schrieb:> 6 Takte pro Flashzyklus an, mit 4 Worten Breite
Achso ja, das heißt alle 6 Prozessortakte können 4 Instructions geladen
werden, richtig? was hilft dann der hohe Prozessortakt wenn er nicht
gefüttert werden kann? das leuchtet mir nicht ein.
A. K. schrieb:> ARMv7M kann das exakt genauso wie AVR.> UBFX Rtemp,Rs,#S,#1> BFI Rd,Rtemp,#0,#D
Oh tja, daran hab ich gar nicht gedacht. Braucht aber ein Hilfsregister
:P
A. K. schrieb:> Ergibt 1KB Code dafür und 256 Takte insgesamt, plus ein paar Takte Kopf> und Schwanz für die Register.
Wobei es nicht völlig verkehrt sein muss eine äußere Schleife zu
verwenden (wie ichs im Code gemacht hab), die das ganze um ein paar
Takte langsamer, aber viel kleiner macht (dann ~40 Byte oder so). Wäre
das nicht außerdem für den Cache günstig?
Michaela schrieb:> Wobei ich immernoch der Meinung bin, dass entweder in die andere> Richtung geshiftet werden müsste,
Hm du hast wohl recht. In deinem Bild würde man nach Links shiften, aber
in üblicher bzw. C-Notation entspricht das einem Rechts-Shift, das hatte
mich etwas verwirrt - war schon spät :)
Michaela schrieb:> der I-Stream ist der Datenstrom, der die> Prozessorbefehle aus dem Flash zur CPU liefert?
Ja.
> Darüber steht doch im RefMan, dass diese Befehle immer in 128bit-Blöcken> geladen werden, was 4 16-bit-Befehlen entspricht.
Stimmt. Aber wenn du 6 Takte brauchst (168MHz >= 2,7V), um 4 Worte aus
dem Flash zu ziehen, dann liegt die Laufzeit von sequentiellem aus
1-Wort Befehlen bestehenden Codes garantiert nicht unter 6 Takte pro 4
Worte.
> Kann der Prozessor dann während dem Execute in einem Zyklus Daten aus> den Registern laden, verarbeiten und speichern, sodass im darauf> folgenden Taktzyklus bereits das Ergebnis wieder verwendet werden kann?
Ja.
> Wie falsch?
Bloss die beiden Immediates. Da gibts eine kleine Schere zwischen
Codierung und Assembler-Angabe, die mich verwirrte.
> Oder liege ich da falsch?
Bei meinem Code wird nur im Rahmen der UBFX/BFI Befehle geshiftet,
nirgends sonst. Diese beiden Befehlen sind effektiv eine
Einzelbitkopieroperation der Art
output[d].bit[D] = input[s].bit[S]
Häng davon 128 ohne jede Schleife hintereinander, für jedes Bit eine,
dann ist deine Permutation durch.
Michaela schrieb:> Achso ja, das heißt alle 6 Prozessortakte können 4 Instructions geladen> werden, richtig? was hilft dann der hohe Prozessortakt wenn er nicht> gefüttert werden kann? das leuchtet mir nicht ein.
Die Thumb2 Befehle sind ein Mix auf 0,5-Wort und 1-Wort Befehlen und es
sind auch viele dabei, die mehr als einen Takt benötigen. Der I-Fetch
Durchsatz eines typischen Thumb2-Programms liegt also wesentlich unter 1
Wort pro Takt. Und dann reicht es. Ist etwas auf Kante dimensioniert,
aber billiger. Den Nebeneffekt siehst du hier: Es gibt Code, der durch
diese Sparsamkeit ausgebremst wird.
Niklas Gürtler schrieb:> Wobei es nicht völlig verkehrt sein muss eine äußere Schleife zu> verwenden (wie ichs im Code gemacht hab), die das ganze um ein paar> Takte langsamer, aber viel kleiner macht (dann ~40 Byte oder so). Wäre> das nicht außerdem für den Cache günstig?
Ja, das geht natürlich. Und dann hilft der Cache. Mein Ansatz war die
generische Permutation zwischen beliebigen Bits. Mit Berücksichtigung
der konkreten Aufgabe lässt sich das auch als Kompromiss weiter
optimieren.
Jungs, ihr seid Klasse. So macht das richtig Spaß, zumindest mir. Ich
hoffe euch machts auch ein wenig Spaß.
Aber zurück zum Thema:
Leider ist mein Oszi gerade in einem Karton verschollen (wir machen hier
gerade Grundrenovierung und ich musste meine Bude räumen), daher kann
ich gerade keine Laufzeiten messen. Die Theorie muss also gerade
überbrückend aushelfen. Sofern ich irgendwann einmal herausfinde welcher
Befehl wieviele Takte benötigt kann ich sogar mit Zahlen rechnen. Das
wär noch was...
Zum Code:
Eure Anregungen und Ideen habe ich mal im Code im Anhang ausgearbeitet.
Sieht schon ganz gut aus. Beim Compilieren kommt zwar jetzt die Meldung,
dass out[0..4] nicht initialisiert werden, aber dass darf/soll ja so
sein, wird ja Bit für Bit überschrieben.
Den Output vom objdump hab ich noch etwas leserlicher gekürzt und
ebenfalls angefügt. Was mir dabei auffällt:
UBFX und BFI sind beides Halfword-Instruktionen. D.h. sie benötigen
zusammen schon die 128bit und sie benötigen vom laden her schon einmal
mindestens 6 Prozessor-Takte. Ich werde also als nächstes also mal die
andere Option mit BFI und shiften ausprobieren. Die Shift-Operationen
sind offenbar single-Byte-Instruktionen und damit erhoffe ich mir
zumindest vom I-Stream her einen Gewinn von 25%.
Sobald mein Oszi wieder auftaucht (was sicher die Tage noch sein wird)
werde ich das direkt gegenüberstellen und ausprobieren...
Danke nochmals für eure Hilfe und vorallem für die vielen Anregungen was
man alles beachten kann und sollte. Ich finde nur so lernt man wirklich
den Prozessor kennen. Die vielen Datenblätter am stück studieren... ich
glaube da würde ich keine 10% behalten.
Viele liebe Grüße
Michaela
Michaela schrieb:> UBFX und BFI sind beides Halfword-Instruktionen. D.h. sie benötigen> zusammen schon die 128bit und sie benötigen vom laden her schon einmal> mindestens 6 Prozessor-Takte. Ich werde also als nächstes also mal die
Hallo? Wort = 32 Bits, Halbwort = 16 Bits.
UBFX/BFI = 32 Bits. Zusammen 64 Bits.
> andere Option mit BFI und shiften ausprobieren. Die Shift-Operationen> sind offenbar single-Byte-Instruktionen
Verrätst du mir, wieviele Bits deine Bytes und Worte haben? Jedenfalls
haben sie keinerlei Ähnlichkeit mit meinen.
Michaela schrieb:> Ich> hoffe euch machts auch ein wenig Spaß.
Na klar, bei der initialen Frage konnte ich ja nicht widerstehen... ;-)
Michaela schrieb:> Sofern ich irgendwann einmal herausfinde welcher> Befehl wieviele Takte benötigt kann ich sogar mit Zahlen rechnen. Das> wär noch was...
Die Info ist ein bisschen versteckt, im ARM® Cortex™-M4 Processor
Technical Reference Manual:
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0439d/index.html
Kaptel "3.3.1. Cortex-M4 instructions".
Die Längen der Instruktionen finden sich im ARMv7M Architecture
Reference Manual:
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0403c/index.html
Kapitel "Instruction Details / Alphabetical list of ARMv7-M Thumb
instructions" neben Unmengen weiterer Detailinformationen.
Michaela schrieb:> Beim Compilieren kommt zwar jetzt die Meldung,> dass out[0..4] nicht initialisiert werden, aber dass darf/soll ja so> sein, wird ja Bit für Bit überschrieben.
Kannst ja noch explizit auf 0 initialisieren, die 4 Zyklen... Der
Compiler blickt durch die Logik wohl nicht ganz durch ;)
Von dem Caching-Zeug hab ich aber auch keine Ahnung...
A. K. schrieb:> Hallo? Wort = 32 Bits, Halbwort = 16 Bits.> UBFX/BFI = 32 Bits. Zusammen 64 Bits.
Hmm, ja da hast du recht. Da hab ich nicht so ganz mitgedacht und
gestern wohl etwas blödsinnig gezählt. Wenn man die Anzahl der Bits in 4
Bytes aufsummiert darf man halt nicht 8 - 16 - 32 - 64 zählen...
Eindeutig falsch.
Mein Fehler.
Unabhängig vom falsch zählen ist aber lsl nur "halb so groß" wie die
anderen beiden und dürfte somit den I-Stream weniger belasten. Probieren
und Vergleichen...
Danke euch
Den ART muss man aber explizit einschalten !
Aus dem Referenz manual :
To release the processor full performance, the accelerator implements an
instruction
prefetch queue and branch cache which increases program execution speed
from the 128-
bit Flash memory. Based on CoreMark benchmark, the performance achieved
thanks to the
ART accelerator is equivalent to 0 wait state program execution from
Flash memory at a
CPU frequency up to 168 MHz.
@Michaela
Darf ich fragen, was man mit so einer Rumschieberei macht?
Längs rein, quer raus...
@All
Falls mal jemand nach einer Zusammenstellung der ARM-Befehle (Thumb-2)
sucht:
http://infocenter.arm.com/help/topic/com.arm.doc.qrc0001l/QRC0001_UAL.pdf
Ginge es eigentlich mit Bit-Banding noch schneller?
http://www.mikrocontroller.net/articles/ARM_Bitbanding
Da müsste man doch eigentlich direkt ein Bit im RAM in ein anderes Bit
im RAM kopieren können. Fragt sich aber, ob es schneller ist,
wenn die Daten dann nicht im Register sind,
sondern vom Speicher kommen und dort wieder hin kopiert werden
und dies vielleicht 8 bis 16 mal mehr, als wenn alles
übers Register läuft...
(Wobei man dies vielleicht dann via DMA machen könnte...?)
Ingo schrieb:> Ginge es eigentlich mit Bit-Banding noch schneller?
Wohl kaum.
> Da müsste man doch eigentlich direkt ein Bit im RAM in ein anderes Bit> im RAM kopieren können.
Obacht: Das Timing vom Store-Befehl mit Bitbanding dürfte nicht das
gleiche wie sonst sein. Immerhin ist das als read-modify-write
implementiert.
Nope, schneller als 2 Takte pro Bit wirds nicht. Kanns nicht, weils
keinen Bitcopy-Befehl gibt, bei dem Quelle und Ziel frei wählbar sind.
Folglich sind es immer mindestens 2 Befehle pro Bit.
Ingo schrieb:> (Wobei man dies vielleicht dann via DMA machen könnte...?)
Beim DMA gibts kein Bitbanding.
DMA ist ohnehin kein sinnvolles Werkzeug, um Daten im primären Speicher
herumzukopieren. Die CPU ist dabei stets schneller.
Oha, jetzt wirds abgefahren. Korrigiert mich wenn ich falsch liege, aber
der STM32 läuft offenbar mit dem CMSIS gar nicht mit voller Power. Wenn
man den Befehlen der SystemInit() mal folgt, kommt man an den Punkt, wo
das Flash Interface initialisiert wird (in einer Zeile):
system_stm32f4xx.c: Zeile 396
Allerdings wird dabei nicht der Instruction-Prefetch aktiviert, was
für mich bedeutet, dass entweder der Cache die Prefetch-queue
überflüssig macht, oder aber der Prozessor nur, wie im <DM000310020.pdf,
RM0090 Reference manual -> Seite 64 -> Figure 4> zu erkennen,
128-instructions-bits abarbeitet und dann für 4 Prozessorzyklen auf neue
Befehle wartet... was gute 50% der Rechenleistung durch Warten ersetzen
würde.
Ich kann mir allerdings eigentlich nicht vorstellen, dass die Entwickler
von dem ganzen CMSIS-Zeug vergessen haben dem Prozesser die volle
Leistung frei zu schalten (warum auch immer man das überhaupt abschalten
kann...). Insofern folgere ich eher, dass ich irgendetwas noch nicht
ganz korrekt verstanden habe. Ich werde mir wohl den Text noch ein paar
mal vorlesen, irgendwo muss da ein Haken sein!
Ohne jetzt wieder reinzusehen: Es gibt glaube ich Betriebsbedingungen,
in denen der Prefetcher nicht eingeschaltet werden darf. Muss man daher
wohl separat einschalten.
A. K. schrieb:> Es gibt glaube ich Betriebsbedingungen,> in denen der Prefetcher nicht eingeschaltet werden darf. Muss man daher> wohl separat einschalten.
Hast recht:
DM000310020.pdf, S.61 unten:
The prefetch buffer must be disabled when the supply voltage is below
2.1 V.
... und das könnte der Grund sein, warum der Prefetch Buffer im CMSIS
deaktiv ist.
Weiterhin hat der ART bei frühen Revisionen einen Bug, der lustige
Effekte verursacht. Steht mittlerweile auch in den Errata. Mit ists doch
deutlich schneller.
Jetzt muss ich fragen, ob ihr das auch so versteht wie ich:
STM32F40x and STM32F41x Errata sheet (DM00037591.pdf)
Seite 10, Punkt 2.1.1:
1
The ART Accelerator prefetch queue instruction is not supported on
2
revision A devices.
3
4
This limitation does not prevent the ART Accelerator from using the
5
cache enable/disable capability and the selection of the number of wait
6
states according to the system frequency.
prefetch queue instruction? warum instruction? ist das nicht eher ein
Modul oder so? Aber doch keine Instruction?!
Und aus dem 2. Absatz verstehe ich gerade, dass man in der betroffenen
Revision A alles Nutzen kann nur den Prefetch nicht, seht ihr das auch
so?
Vielen Dank
Liebe Grüße
Michaela
Michaela schrieb:> prefetch queue instruction? warum instruction? ist das nicht eher ein> Modul oder so? Aber doch keine Instruction?!
Ersetze das durch "instruction prefetch queue", dann wirds vielleicht
klarer.
Genau. Und mit "not supported" meinen die, dass aus unerfindlichen
Gründen Hard-Faults auftreten. Wenn man an ganz anderen Stellen Code
ändert, gehts mal wieder gut, dann wieder nicht. Fehlersuche dabei ist
zum kotzen ;-)
Hey Jungs (und Mädels?),
es gibt ein Update: Mein Oszi ist fürs Wochenende aus seinem Karton
gekrochen und hat mir direkt ein paar Kleinigkeiten gemessen:
Ich hab die zwei Code-Optionen mal verglichen und von der Tendenz stimmt
das mit den Erwartungen überein. Der BFI-LSL-Code ist der schnellste
(vorausgesetzt man verwendet LSLS da der Compiler sonst ein MOV mit LSL
als 2.Operanden draus macht und das ist dann wieder ein 32Bit-Befehl).
Allerdings hatte ich einen krasseren Unterschied erwartet.
Der ART ist komplett aktiv, also auch der Prefetcher und alle Caches.
Ergebnis:
UBFX-BFI-Code in einer Schleife schaft 3.32µs
BFI-LSRS-Code in einer Schleife schaft 3.22µs
Es ließe sich vielleicht durch loop-unrolling noch mehr raus holen, aber
so ist das absolut ok. Da muss erst einmal nichts mehr verbessert
werden.
Mein ursprüngliches Ziel ist damit sehr gut Erreicht. Dafür möchte ich
euch allen an dieser Stelle noch einmal von ganzem Herzen Danken!
VIELEN VIELEN DANK!
Aber weiter im Text:
Das mittlerweile fast schon interessanter gewordene Thema Prefetcher und
ART. Ich habe einen kleinen Benchmark mit dem BFI-LSLS-Code (auszug im
Anhang) gemacht und hab folgende Werte gemessen:
Laufzeit Aktive module
5.62µs -
5.62µs FLASH_ACR_DCEN
4.07µs FLASH_ACR_PRFTEN
4.07µs FLASH_ACR_PRFTEN | FLASH_ACR_DCEN
3.23µs FLASH_ACR_ICEN
3.23µs FLASH_ACR_ICEN | FLASH_ACR_PRFTEN
3.22µs FLASH_ACR_ICEN | FLASH_ACR_DCEN
3.22µs FLASH_ACR_ICEN | FLASH_ACR_PRFTEN | FLASH_ACR_DCEN
Zugegeben, die Messungen sind vielleicht nicht Perfekt, weil der Code
eventuell minimal unterschiedlich Optimiert wird und daher z.B. der
Portpin einen paar Takte früher oder später gesetzt wird. Aber ins
Gewicht fallen sollte das nicht großartig. Zudem wurde am Code ausser
dem Wert zur Initialisierung des FLASH->ACR Registers nichts geändert.
PS:
Das schnellste was ich mit dem Code so erreichen kann ist momentan
übrigens 2.46µs. Dabei rollt der Compiler (-O3) dann aber auch die
for-Schleife auf. Wenn man das Händisch machen würde, könnte man sogar
noch ein paar Shifts einsparen und somit die 21 aufgerollten
Instuktionen auf 17 reduzieren, vielleicht ginge sogar noch mehr... Das
entspricht dann knapp 20% gewinn, wenn ich mich richtig verrechnet habe
und würde dann theoretisch bedeuten, dass die Datenwandlung auch in rund
2µs abgearbeitet sein könnte, aber man kann auch alles Übertreiben.
Für mich ist dann jedenfalls dieses Thema erst einmal wieder
abgeschlossen.
Ich darf mich noch einmal herzlich für eure Hilfe, Tips und Anregungen
bedanken und hoffe es gibt auch den Einen oder Anderen der hier aus
diesem Thread Nützliches erfahren kann/konnte.
Das Theama ART-Accelerator soll allerdings hiermit auf keinen Fall
abgewürgt werden. Wem hierzu also noch etwas einfällt, das er oder auch
sie erwähnen möchte...
Viele liebe Grüße
Michaela
Update:
Es hat mir doch zu sehr unter den Nägeln gebrannt:
Ich hab mit Octave den Code mal manuell aufgerollt und eingefügt. Dabei
hab ich natürlich die Besagten shift-Operationen der output-register
durch die korrekten Bit-Angaben in den lsbCopyShift( *dest, src,
dstBit ) aufrufen ersetzt. Das sollte dann der schnellst mögliche Code
sein.
Fazit:
Jetzt zeigt sich endlich der Prefetcher. Ohne Prefetcher hat der Code
3.16µs Laufzeit, was mich zuerst gewundert hat. Da hatte ich ja mehr
errechnet. Dann hab ich aber an den Prefetcher gedacht und ihn aktiviert
und siehe da: 1.94µs
Das ist auch das was ich überschlagen hatte.
Ich denke ich werde trotzdem dem Code mit der Schleife nehmen. Ist zwar
ne gute ecke langsamer aber wesentlich übersichtlicher!
Gruß Michaela
Michaela schrieb:> und siehe da: 1.94µs
Das wären dann also ca. 2,5 Takte pro Bit rein für den Kern der internen
Operation. Das Limit vom Prefetch liegt bei 6 Bytes Code pro Bit bei ca.
2,3 Takten. Wenn man den Rest des Codes mitrechnet, also die Laden- und
Speicheroperationen, dann passt das doch ganz gut.
NB: Sowas geht auch ohne Oszi, wenn man irgendwie Daten aus dem
Controller raus bekommt. Immerhin hat das Ding einen SysTick.
Apropos: Wenn dich schon die Neugierde packt, dann wärs eigentlich ganz
interessant, zum Vergleich mal den Code ins RAM zu legen. Keine
Waitstates, kein Durchsatzlimit.
A. K. schrieb:> Apropos: Wenn dich schon die Neugierde packt, dann wärs eigentlich> ganz interessant, zum Vergleich mal den Code ins RAM zu legen. Keine> Waitstates, kein Durchsatzlimit.
How to? das ist doch bestimmt wieder nur irgend ein kleiner Parameter
für den Compiler oder?
Michaela schrieb:> How to? das ist doch bestimmt wieder nur irgend ein kleiner Parameter> für den Compiler oder?
Eher einer vom Entwicklungssystem. Oft gibt es darin Vorkehrungen, fürs
Debugging komplett im RAM laufen zu können. Bei "Handbetrieb" ist es
Sache von Startup-Code und Linker-Sript.
Zumindest beim GCC war es so, dass wenn man nur Codeteile im Ram haben
will, die Funktion mit der entsprechenden Sektion markieren muss und
imLinker Skript diese Sektion definieren muss.
Hat den Vorteil, dass nicht alles ins Ram muss.
>Schau im ARMv7M Architecture Reference Manual, da steht alles dazu drin>was man braucht...
aussen die benötigten Takte.
>> 6 Takte pro Flashzyklus an, mit 4 Worten Breite>Achso ja, das heißt alle 6 Prozessortakte können 4 Instructions geladen>werden, richtig? was hilft dann der hohe Prozessortakt wenn er nicht>gefüttert werden kann?
Oh je, zum X-ten Mal.
Der Flash von dem läuft nur mit ca 24 MHz und der Cache (oder wie man es
nennen mag, auch so bei F4) kann bestenfalls bei LINEAREM Code einen
konstanten I-Strom liefern.
Zudem muss man (weil das noch mehr kostet) CodeSchleifen nicht unbedingt
als sep. Schleife programmieren.
MCUA schrieb:> Der Flash von dem läuft nur mit ca 24 MHz und der Cache (oder wie man es> nennen mag, auch so bei F4) kann bestenfalls bei LINEAREM Code einen> konstanten I-Strom liefern.
Der Cache liefert bei Hits ungebremst. Sequentiell und nichtsequentiell.
Unabhängig davon beschleunigt der Prefetcher sequentiellen Code. Cache
und Prefetch sind zwei paar Stiefel. Bitte den F4 (mit Cache) nicht mit
dem F1 (ohne Cache) verwechseln.
Die vollständig entrollte Version ist linearer also sequentieller
Code, der aber für den Cache zu gross ist. Die Latenz spielt dabei keine
nennenswerte Rolle. Gebremst wird der Code, weil er aufgrund seines
hohen Anteils von Ganzwortbefehlen mit einem Takt Laufzeit einen etwas
höheren Durchsatz benötigt, als das Flash mit seinem Zyklus aus 6 Takten
liefern kann (168/6 sind übrigens 28).
> Zudem muss man (weil das noch mehr kostet) CodeSchleifen nicht unbedingt> als sep. Schleife programmieren.
Ich verstehe nicht, was du damit meinst.
>> Der Flash von dem läuft nur mit ca 24 MHz und der Cache (oder wie man es>> nennen mag, auch so bei F4) kann bestenfalls bei LINEAREM Code einen>> konstanten I-Strom liefern.>Der Cache liefert bei Hits ungebremst.
Nicht schon wieder.
Das Ding ist schon x-mal besprochen worden, und wird hier mit
Regelmässigkeit neu gefragt.
...sollte mal in den Artikel rein, damit nicht jedesmal Leute auf ST
(oder andere) reinfallen.
MCUA schrieb:> Das Ding ist schon x-mal besprochen worden, und wird hier mit> Regelmässigkeit neu gefragt.
Link?
Der F4 hat 64 Blöcke mit je 16 Bytes als Instruction Cache vor dem Flash
sitzen. Ein Zugriff, der davon abgedeckt wird, muss nicht warten. Das
ist der Sinn von Caches.
"To limit the time lost due to jumps, it is possible to retain 64 lines
of 128 bits in an instruction cache memory. This feature can be enabled
by setting the instruction cache enable (ICEN) bit in the FLASH_ACR
register. [...] If some data contained in the instruction cache memory
are requested by the CPU, they are provided without inserting any
delay." [F4 Ref 3.4.2]
Völlig unabhängig davon gibt es einen Prefetch-Buffer. Den gab es auch
schon beim F1, den Cache nicht. Aussagen zum F1 sind also auf den F4
nicht so ohne weiteres anwendbar.