Hallo liebe Forengemeinde, über längere Zeit lese ich jetzt schon passiv im Forum mit und habe auch schon die ein oder andere Idee aufgenommen oder Lösung für diverse Probleme gefunden. Dafür zunächst ein allgemeiner Dank. Im Moment stehe ich jedoch vor einem kleinen Problemchen, das sicher durch tagelanges googlen früher oder später auch erpuzzlet werden könnte, ich denke jedoch, ich verstoße hier nicht gegen die Forenregeln wenn ich mal aktiv um Rat frage. Mit Regel Nr.3 muss ich allerdings direkt brechen, da ich eben dies noch nicht genau weiß (welcher µC). Ich falle einfach mal mit der "Tür ins Haus": Es geht um eine Steuerung für eine kleine Werkzeugmaschine mit drei nicht linearen Achsen. Um den bekannten Problemen mit dem Parallelport aus dem Weg zu gehen, wollte ich die Bahnberechnungen einem µC anvertrauen, dieser soll die Fahrbefehle dann in konkrete Bewegungen umrechnen und an die 3 Schrittmotortreiber weiterreichen. So weit so gut. Eigentlich wollte ich dabei auf Fließkommazahlen verzichten, jedoch haben erste Überschlagsrechnungen gezeigt, dass die Verwendung von Ganzzahlen in manchen Thermen dann bis 38bit benötigen würde (Anstatt mit mm würde dann mit µm gerechnet).Also habe ich zunächst ein kleines Testprogramm aufgesetzt, dass die dann laufenden Berechnungen mit der normalen math.h in double Werten durchläuft (siehe Anhang). Nach jedem Rechendurchlauf wird dann ein Pin getoggelt um die Laufzeit mit dem Oszi zu prüfen. Ursprünglich wollte ich unbedingt einen µC im DIP/DIL-Gehäuse, ob dies nach den Ergebnissen noch umsetzbar ist, wage ich zu bezweifeln. Als Kandidaten hatte ich daher den ATMega328 und den PIC32 im Visier. Eine Experimentierplatine mit AVR32 lag gerade zusätzlich noch rum (der dann allerdings nachher nicht als DIL zu bekommen wäre). Die Atmegas und PIC32er´s sind noch auf dem Postwege, aber ich habe gut 2 Dutzend ATTiny45 hier, die ich auf Grund der asynchronen Timer gerne für schnelle Schaltwandler einsetze (UP/DOWN/SEPIC etc.) Da für mich als Laien die interen Struktur dem Atmega sehr ähnelte habe ich einen davon hergenommen und das Testprogramm aufgespielt. Ernüchternd erreicht der ATTiny45 dabei recht konstant magere 150Hz (Super Leistung, aber Lichtjahre von dem Weg was ich benötige) bei 8MHz Systemtakt, also hochgerechnet auf den ATMega bei später 20 MHz etwa 375 Berechnungen pro Sekunde ohne RS232-Kommunikation und Motorsignalaufbereitung. Das an den AVR32 angepasste Programm erreicht bei derzeit 12MHz Systemtakt gut 700 bis 900 Hz, hier scheint die Rechendauer von den Funktionswerten abzuhängen. Ursprünglich war geplant die Endstufen mit maximal 26000 Hz zu fahren, im Notfall würden es jetzt bei geringerer Genauigkeit und geringerer Geschwindigkeit auch 4000 Hz tun, aber auch davon bin ich noch sehr weit weg. Daher bin ich für jeden Vorschlag dankbar, im Moment gehen die Überlegungen von "angepassten" Rechenfunktionen über Auflösungsreduzierung im Eilgang (wenig sinnvoll, das HSC geplant) bis hin zu einem µC pro Achse, aber dann ensteht ja das nächste Problem einer ausreichend schnellen Verbindung unter den µC´s. Ich hoffe zwar noch auf den PIC32, aber so viel Unterschied zum AVR32 wird wohl nicht sein, wenn überhaupt. Wer weiß Rat oder einen geeigneten, bezahlbaren und beschaffbaren µC? Gruß Dominik
Dominik V. schrieb: > Ernüchternd erreicht der ATTiny45 dabei recht konstant magere 150Hz Wow. Das hätte ich bei
1 | do
|
2 | {
|
3 | x+=0.001; |
4 | y=sin(x); |
5 | z1=sqrt(ARMLENGTH2 - pow(x-x1, 2) - pow(y-y1, 2)) + z; |
6 | z2=sqrt(ARMLENGTH2 - pow(x-x2, 2) - pow(y-y2, 2)) + z; |
7 | z3=sqrt(ARMLENGTH2 - pow(x-x3, 2) - pow(y-y3, 2)) + z; |
nicht gedacht. Da muss ich wohl bei m.n. Abbitte leisten. Die Dinger
sind schneller als die Polizei erlaubt.
> Ursprünglich war geplant die Endstufen mit maximal 26000 Hz zu fahren,
Dann solltest du allerdings aufhören, deinen Computer mit
Beschäftigungstherapie vollzustopfen und dir mal ein wenig sinnvoll
Datentypen und Rechenvorgänge zurecht legen. Naiv mit double um sich zu
werfen kann man sich auf einem GHz Boliden wie einem PC erlauben. Bei
allem anderen sollte man ein wenig intelligent an die Sache rangehen und
zb Quadrate nicht mit pow berechnen, wenn es ein simples x*x auch tut.
Attinys haben keinen HW-Multiplizierer. Der Atmega wird aber bei deinem Code auch nicht viel schneller sein. Auch wirst du keine optimierte Funktionen für Wurzeln bei float finden. Festkommaarithmetik ist schon der richtige Weg. Und selbst 40bit sind kein großes Problem. Wenn 32bit nicht reichen (da gibt es massig Code dafür), muss man die Routinen selbst schreiben. Das Ergebnis ist kleiner, performanter Code. Die paar Zeilen von Karl-Heinz dürften bei 32bit ein paar tausend Zyklen dauern. Und dann kann man wahrscheinlich immernoch deinen Algorithmus optimieren. Da ist wahrscheinlich am meisten rauszuholen. Ich denke schon das der Atmega die 4KHz schaffen kann, aber nicht wenn man den Code einfach so hin schreibt. Da gehört dann etwas mehr Gehirnschmalz dazu.
z1=sqrt(ARMLENGTH2 - pow(x-x1, 2) - pow(y-y1, 2)) + z; z2=sqrt(ARMLENGTH2 - pow(x-x2, 2) - pow(y-y2, 2)) + z; z3=sqrt(ARMLENGTH2 - pow(x-x3, 2) - pow(y-y3, 2)) + z; if((z1>0.0)||(z2>0.0)||(z3>0.0)) die Abfrage ist etwas sinnfrei, entweder es ist eine von den drei Wurzeln >0 oder du ziehst die Wurzel aus einer negativen Zahl
Dominik V. schrieb: > Ernüchternd erreicht der ATTiny45 dabei recht konstant magere 150Hz > (Super Leistung, aber Lichtjahre von dem Weg was ich benötige) bei 8MHz > Systemtakt, also hochgerechnet auf den ATMega bei später 20 MHz etwa 375 > Berechnungen pro Sekunde Gerade bei solchem mathelastigen Kram kannst du die Tiny-Rechenleistung keinesfalls linear auf einen Mega hochrechnen. Ein Mega hat nämlich eine wichtige Sache, die ein Tiny nicht hat: einen Hardware-Multiplizierer. Und der läßt einen Mega gerade bei solchen Sachen ganz erheblich besser aussehen. Im Übrigen ist dein ganzer Ansatz überdenkenswert. Den Achsencontroller muß man natürlich nicht selbst die Wege berechnen lassen, der soll sie nur in Echtzeit abfahren. Die Berechnungen macht der Leitrechner, der kann das viel schneller erledigen, bloß eben nicht unbedingt gleichmäßig. Der Achsencontroller holt immer bloß einen Block fertige Koordinatentupels vom PC und fährt diese ab, während er nebenbei gleich wieder den nächsten Datenblock holt, so daß eine unterbrechungsfreie Fahrt gewähleistet ist, auch wenn der PC mal ein paar ms nichts liefert. Genau nach diesem Schema funktionieren die meisten Kleinsteuerungen auf PC-Basis.
Hi Dominik, schau dir mal die ARM Cortex-M4 an. Die haben eine Fließkommaeinheit mit drauf, dürften in SW aber schon eine deutliche Ecke fixer sein. Konkret kann ich dir die STM32F4 empfehlen. Auf bastlerfreundlichem Evalboard für 15€ erhältlich (STM32F4DISCOVERY). Liebe Grüße, Jan
Dann gibt's noch diese kleinen PC/104 Rechner. Standardisiert und eine halbe Eurokarte groß. Falls die angedachten uC's das nit schaffen, hast du für relativ kleines Geld einen Pentium. Häufig läßt sich auch gleich ein Monitor anschließen.
Hallo, super schnelle Rückmeldungen, hatte ich so gar nicht erwartet, Danke! Also, der Code ist im Moment natürlich so unperformant wie möglich um für die Leistungen ein Gefühl zu bekommen. Das Pow ist daher im Moment noch Absicht. Auch hatte ich dem Tiny einen HW-Multiplizierer angedichtet, da ich der Meinung war der MUL-Befehl in der Assembler-Referenz würde darauf abzielen. Also warte ich mal was der ATMega aus dem Testprogramm macht. Parallel werde ich mich mal mit der 38 bit-Lösung beschäftigen um einen Vergleich zu haben. Ok, die if-Abfrage hätte ich erwähnen sollen, das war Q and D um nicht jedem Compiler mitteilen zu müssen er möge bitte den restlichen Code nicht wegoptimieren. Die Lösung mit dem Leitrechner hatte ich auch ins Auge gefasst, aber dann müssten bei voller Fahrt Rohdaten von 1.536.000 bit/sec den Besitzer wechseln, und da ist dann meine RS232-Schnittstelle bei Faktor 14 geschlagen. Darüberhinaus fallen dann Standalone und Wechsel des Steuerrechners raus ;-( Das STM32Discovery werde ich sofort mal googlen. Die PC-Variante (04/Raspberry/etc) hatte ich eigentlich ausgeschlossen da ich kein ganzes Betriebssystem installieren wollte, das wäre dann nur der letzte Step, falls alles andere nicht klappt. Gruß Dominik
Ein Arduino Due mit dem SAM3X dürfte gegenüber den ATtiny45 auch ein "paar" mehr Reserven haben ;-)
Du kannst ja versuchen die Sache etwas zu optimieren ... Ich habe dein Programm eben durch den Simulator geschickt, gerade der sin(x)-Befehl schluckt ordentlich Takte. Eventuell mit einem Lookup-Table arbeiten. Hast ja nur ~3143 Werte. Eventuell findet sich darin etwas schneller der gesuchte Wert, müsste man ausprobieren.Eher ein Speicherproblem... Genauso deine 2*3 POW-Befehle. Der gute alte Binomi. (x-xi)^2 ist ja x^2 - 2x*xi +xi^2 . für i = 1..3 berechnest du diesen Ausdruck drei mal. Es würde aber reichen, einmal x^2 zu berechnen, xi^2 ist ja eh konstant, dann noch drei mal 2x*xi. Für y dito. Spart eventuell etwas Rechenzeit verglichen mit 3 mal POW2. Für y dito.
Mr. X schrieb: > Ein Arduino Due mit dem SAM3X dürfte gegenüber den ATtiny45 auch ein > "paar" mehr Reserven haben ;-) Dann wäre die Frage ob der SAM3X dem AVR32 um Längen voraus ist oder beide bei gleicher Taktrate etwa die gleiche Rechenleistung bringen?
Ich habe deinen "Benchmark" spaßeshalber mal auf einem ST32F103C8 ( 72 Mhz ) laufen lassen, mit allen doubles und math-Aufrufen. Innerhalb von 10 Sekunden wurden 73501 Berechnungen durchgeführt. Mit einigen Optimierungen ist da wohl noch einiges mehr drin.
Dominik V. schrieb: > dann müssten bei voller Fahrt Rohdaten von 1.536.000 bit/sec den > Besitzer wechseln Du solltest erst Mal sagen was Du genau vor hast, ich glaube nicht dass Du eine solche Datenmenge wirklich brauchst Die Kunst des Ingenieurs liegt vor allem darin nur so viel zu machen wie notwendig ist um die Aufgabe zu lösen
Dominik V. schrieb: > Das STM32Discovery werde ich sofort mal googlen. Es gibt auch einige lesenswerte Artikel: STM32 STM32 für Einsteiger Und noch weitere: http://www.mikrocontroller.net/articles/Kategorie:ARM
Boschler schrieb: > Du kannst ja versuchen die Sache etwas zu optimieren ... > Ich habe dein Programm eben durch den Simulator geschickt, > gerade der sin(x)-Befehl schluckt ordentlich Takte. > Eventuell mit einem Lookup-Table arbeiten. Hast ja nur ~3143 Werte. > Eventuell findet sich darin etwas schneller der gesuchte Wert, müsste > man ausprobieren.Eher ein Speicherproblem... > > Genauso deine 2*3 POW-Befehle. > > Der gute alte Binomi. > (x-xi)^2 ist ja x^2 - 2x*xi +xi^2 . > für i = 1..3 berechnest du diesen Ausdruck drei mal. > Es würde aber reichen, einmal x^2 zu berechnen, xi^2 ist ja eh > konstant, dann noch drei mal 2x*xi. Für y dito. > Spart eventuell etwas Rechenzeit verglichen mit 3 mal POW2. > Für y dito. Das leuchtet ein, binomische Formeln ausgerechnet und Konstanten nur einmal berechnet, Klammern weg, das Testergebnis: vorher 158 Hz nachher 127 Hz Da hat der Compiler den ursprünglichen Code dtl. besser optimiert ;-( Die 3143 Werte ändern sich natürlich noch, da es nicht immer der Einheitskreis sein wird und den sin hatte ich gewählt weil ich die Kreisinterpolation ohnehin für am zeitaufwendigsten gehalten habe.
@AVerr wenn ich mich jetzt nicht verrechnet habe, dann entspricht das der 1,75 fachen Leistung meines AVR32 @Walter, dem stimme ich zu, ertappt wurde ich oben mit dem Hinweis auf das Smothieboard, geplant ist eine Delta-Kinematik mit 3 linearen Z-Achsen. Achsensteigung 4mm bei 3200 Microschritten, die ganzen Tests und Rechenspiele dienen der Ermittelung der maximalen Verfahrgeschwindigkeit (zunächst der Achsen). Bislang hat der normale PC nur berechnet wie weit SOLL und erreichbares IST der Werkzeugspitze auseinander liegen können, damit wurden Steigungen und Auflösung berechnet. Die oben erwähnte Datenmenge würde z.B. nur bei 800 Microschritten ausreichen, damit entferne ich mich aber wieder um Faktor 4 von meinen Zielwerten... Gruß Dominik
Ich habe mal das Benchmark-Programm angehängt, falls jemand weiteres Lust zum testen hat. ( Jede Sekunde wird in das Array readings die Anzahl der Berechnungen gepusht, avg stellt wie der Name schon sagt den Mittelwert dar ). Hier auch meine Ausgabe im gdb:
1 | (gdb) print readings |
2 | $3 = {7389, 7399, 7447, 7378, 7445, 7413, 7365, 7480, 7388, 7356, 7485, 7388,
|
3 | 7374, 7468, 7358, 7482} |
4 | (gdb) print avg |
5 | $4 = 7413 |
Man sieht also, dass er ziemlich konstant ca. 7400 Berechnungen pro Sekunde packt. Wenn interesse besteht, könnte ich das morgen auch mal auf einem STM32F4 Discovery laufen lassen.
Walter schrieb: > Die Kunst des Ingenieurs liegt vor allem darin nur so viel zu machen wie > notwendig ist um die Aufgabe zu lösen Nach einigem Nachdenken ist der Ansatz doch wesentlich besser, Gehen wir von 4mm Steigung, 3200 Mikroschritten und einer maximalen Verfahrgeschwindigkeit von 40mm / sec aus, damit haben wir 2,8m /min bei einer theoretischen Auflösung von unter 1,25/1000 mm (Das Delta-Design erhöht die Genauigkeit durch die Interpolation der 3 Achsen sogar noch etwas / die Spindeldrehzahl ist erträglich) 40/4*3200 = 32000 steps/sec Damit bleiben bei 40Mhz (PIC32) genau 1250 Takte für alle Befehle inkl. Kommunikation und Motorsteuerung. Der Atmega328 (20MHz/625 Takte) könnte im RAM aber "nur" knapp ~340 Schritte puffern, der PIC32MX150F128B schon ~5300 (Ohne sonstige Steuerbefehle). Beides nur Sekundenbruchteile, wie kann man dies am besten lösen, gibt es empfehlenswerte Speichermodule? Allerdings bleibt auch bei intelligenter Kodierung die Datenrate bei 115200 BAUD zu schmal für 3 Achsen, wie viel Rechenleistung benötigt die serielle Kommunikation bei PIC32 und ATMega? Zur Not könnte man ja beide U(S)ART´s nutzen? Den STM32 muss ich mir auf jeden Fall noch genauer ansehen. Gruß Dominik
Dominik V. schrieb: > Boschler schrieb: >> Der gute alte Binomi. >> (x-xi)^2 ist ja x^2 - 2x*xi +xi^2 . >> für i = 1..3 berechnest du diesen Ausdruck drei mal. >> Es würde aber reichen, einmal x^2 zu berechnen, xi^2 ist ja eh >> konstant, dann noch drei mal 2x*xi. Für y dito. >> Spart eventuell etwas Rechenzeit verglichen mit 3 mal POW2. LOL > Das leuchtet ein, binomische Formeln ausgerechnet > und Konstanten nur einmal berechnet, Klammern weg, das Testergebnis: > vorher 158 Hz > nachher 127 Hz > Da hat der Compiler den ursprünglichen Code dtl. besser optimiert ;-( Das möglicherweise auch. Vor allem ist es hochgradiger Blödsinn hier den binomischen Satz zur Vereinfachung verwenden zu wollen. Aus
1 | (x-xi)*(x-xi) |
macht der Compiler eine Subtraktion und eine Multiplikation. Für
1 | x*x - 2*x*xi + const |
werden aber zwei Additionen und zwei Multiplikationen gebraucht (und da gehe ich schon davon aus, daß der Compiler einen effizienten Weg für die Multiplikation mit 2 kennt, was bei double nicht unbedingt sein muß). XL
Mach doch den RS232 port weg und schreib die Fahrdaten auf eine SD card. PIC32 mit 80MHz verwenden. SD card kann auch mit DMA eingelesen werden. Gibts auch mit 512K FLASH und 128K RAM. Allerdings nicht mehr als DIP IC. Am besten gleich ein kleines TFT display dranhaengen, Playstation XY Encoder macht sich auch ganz gut. Mit A/D einlesen.
Kann es sein, dass ich irgendwo falsch abgebogen bin? Wir schreiben doch 2014 - nicht wahr? Ich war eigentlich davon ausgegangen, dass man heute soviel Rechenleistung kaufen kann (in vernünftigem Rahmen), wie man haben will. Das der 86 Cent Prozessor nicht mit einer Hardwaremultiplikation, oder gar mit einer Hardwarefließkommaarithmetikeinheit aufwarten kann sollte sich auch bereits herum gesprochen haben. Die alte Weisheit dass die Reihenfolge schon stimmen sollte, gilt auch noch. Also erst überschlagen wieviel Grübelpower man benötigt, dann schauen welche Hardware dazu passt... Also wo ist das Problem? Das der kleine ATTiny mit endloser Fließkommaarithmetik überfordert ist?
Das Problem ist, dass mit der steigenden Rechenleistung auch viele Unwissende Leute angezogen werden, die dann auf tolle Ideen kommen, was man mit der vielen neuen Rechenleistung machen könnte. Leider übersieht man oft Details, wie beispielsweise, dass die Rechenleistung rapidigst in den Keller rauscht, wenn auf (zugegebenermaßen völlig unnötige) Gleitkommarechnung umgesattelt wird. Was hier also gemacht wird ist einfach das Mehr an Rechenleistung gegen Faulheit bzw. Unwissen des Programmierers eingetauscht wird. Und dadurch wirkt die viele Rechenleistung auf einmal doch wieder wie ein Z80. Ich bin mittlerweile auch schon relativ lange im Business und andere Argumente als "Einfachheit für Programmierer" habe ich bisher nicht PRO Gleitkomma gefunden. Auf der anderen Seite ist es oft viel langsamer in der Berechnung und der Programmierer macht sich oft auch gar keine Gedanken über so Sachen wie signifikante Stellen und Genauigkeit/Dynamik der Gleitkommazahl. Wenn hingegen Fixkomma verwendet wird, MUSS der Programmierer sich hierüber zwangsläufig Gedanken machen, da er ja den Wertebereich selber festlegt. Hier wird er aber dann auch durch eine wesentlich höhere Rechenleistung belohnt, wie sie bei Regel und Steueranwendungen, vor allem im industriellen Umfeld oft gebraucht wird. Und Ja: Einen Frequenzumrichter kann man auch mit einem schnöden 8 Bitter umsetzen, wie der Artikel dazu hier auf der Website zeigt.
Simon K. schrieb: > Ich bin mittlerweile auch schon sehr lange im Business und andere > Argumente als "Einfachheit für Programmierer" habe ich bisher nicht PRO > Gleitkomma gefunden. Du hast noch nie einen numerischen Algorithmus wie zB CG für FEM gesehen.
Oder ein adaptives filter, dessen Wertebereich du nicht einschätzen kannst...
Dominik V. schrieb: > Der Atmega328 (20MHz/625 Takte) könnte > im RAM aber "nur" knapp ~340 Schritte puffern Ein Mega1284P hat 16kByte SRAM, also die achtfache Menge eines 328. Das sollte reichen, im alles zu überbrücken, was bei einem vernünftig konfigurierten PC als "Ausfallzeit" so auftritt. > Allerdings bleibt auch bei intelligenter Kodierung die Datenrate bei > 115200 BAUD zu schmal für 3 Achsen Die USART kann auch wesentlich schneller. Du mußt bloß den PC mit einer entsprechend leistungsfähigen Gegenstelle ausrüsten. Es gibt PC-UARTs, die mit knapp ein 1MBit/s zu laufen vermögen. Außerdem gibt es auch noch andere Kommunikationskanäle, z.B. USB. Ein entsprechender Wandler kostet auch nicht die Welt.
Jan Berg schrieb: > schau dir mal die ARM Cortex-M4 an. Die haben eine Fließkommaeinheit mit > drauf, dürften in SW aber schon eine deutliche Ecke fixer sein. Dem schließe ich mich an. Obwohl ich privat lieber NXP Cortex-M3 nehme, dürfte ST hier eine größere Auswahl an M4 haben. Wenn Du letztendlich auf Fließkomma verzichten kannst, tut es auch ein M3. Selbst auf M3 mache ich im 20µs Raster * und / mit floats, ohne dass es da zu Problemen kommt. Die M3 haben auch einen HW-Multiplizierer. IIRC dauert eine Multiplikation 1 Takt und eine Division max. 7 Takte. Für STM32 findest Du hier auch eine größere Anwendergruppe als AVR32.
Ist bei der Aufgabe der Weg das Ziel oder die Steuerung der Maschine? Falls letzteres, das gibt's schon fertig fuer wenig Geld. Wenn auch nicht ohne Betriebssystem. Beaglebone + Machinekit als Stichwort LCNC beherrscht auch schon weit kompliziertere Kinematiken als delta.
Keine Ahnung ob es hilft, aber auf Hackaday gab es vor kurzen einen Artikel über diverse CNC Ansteuerungen: http://hackaday.com/2014/03/17/mrrf-arm-based-cnc-controllers/
Dr. Sommer schrieb: > Simon K. schrieb: >> Ich bin mittlerweile auch schon sehr lange im Business und andere >> Argumente als "Einfachheit für Programmierer" habe ich bisher nicht PRO >> Gleitkomma gefunden. > Du hast noch nie einen numerischen Algorithmus wie zB CG für FEM > gesehen. Am Thema vorbei. Oder rechnest du FEM Modelle auf dem µC? Jan K. schrieb: > Oder ein adaptives filter, dessen Wertebereich du nicht > einschätzen kannst... Sowas gibts nicht. Wenn die Aufgabenstellung derart unkonkret ist, faßt ein Ingenier das gar nicht erst an. XL
AVerr schrieb: > Ich habe mal das Benchmark-Programm angehängt, falls jemand weiteres > Lust zum testen hat. Lust habe ich keine, aber ich bin chronisch neugierig :-) Um keine Probleme mit verstümmeltem double zu bekommen, habe ich einen IAR-Compiler genommen und einmal float und einmal double rechnen lassen. Da er gerade auf dem Tisch liegt, habe ich einen ATmega328 auf einem Arduino-Board mit 16MHz rechnen lassen. Zur Messung der Zeiten lasse ich PORTD.2 togglen. Die verwendeten Dateien sind im Anhang, damit sich jeder selbst ein Bild machen kann. float_test.hex (eff. 2642 Byte Codegröße) braucht pro Schleifendurchlauf ca. 950µs @ 16MHz, was umgerechnet auf die maximal möglichen 20MHz eine Durchlaufrate von 1300/s ergibt. double_test.hex (eff. 4192 Byte Codegröße) braucht pro Schleifendurchlauf ca. 4,6ms - 5,7ms @ 16MHz. Bequemerweise rechne ich mit durchschnittlich 5ms. Umgerechnet auf die maximal möglichen 20MHz ergibt sich eine Durchlaufrate von rund 250/s. Wer mag, kann die Programme selber laufen lassen oder durch einen Disassembler schicken und staunen, wie da gewirbelt wird. Axel Schwenke schrieb: > und da > gehe ich schon davon aus, daß der Compiler einen effizienten Weg für die > Multiplikation mit 2 kennt, was bei double nicht unbedingt sein muß). Wenn man es eilig hat und die Rahmenbedingungen beachtet, erhöht man einfach den Exponent + 1 :-) Noch etwas an die Fix_Komma_Nix-Fraktion: hier habt Ihr eine schöne Programmvorlage, um die Überlegenheit Eures Programmierstils zu belegen. Allerdings gehe ich davon aus, dass da 'Nix' zurückkommt, die großen Sprüche aber weiterhin in die Welt getutet werden.
Axel Schwenke schrieb: > Dr. Sommer schrieb im Beitrag > Jan K. schrieb: >> Oder ein adaptives filter, dessen Wertebereich du nicht >> einschätzen kannst... > > Sowas gibts nicht. Wenn die Aufgabenstellung derart unkonkret ist, faßt > ein Ingenier das gar nicht erst an. > > > XL Du rechnet kalman und vergleichbare Filter in fixed point? Das Problem ist ja nicht nur die Genauigkeit sondern auch der Wertebereich... Wäre wirklich an einer Implementierung interessiert :)
Hab das ganze mal mit dem STM32-M4 @168MHz rechnen lassen, nur um zu sehen wie dieser sich schlägt. Aber bin eher entäuscht. Er schafft mit FP Unit schlappe 13kHz bis 16kHz. Schwankt anscheinend je nach Werten. Glaube da wirst du um das Optimieren nicht drum herum kommen. Gruß
Jürgen H. schrieb: > Hab das ganze mal mit dem STM32-M4 @168MHz rechnen lassen, nur um zu > sehen wie dieser sich schlägt. > > Aber bin eher entäuscht. > > Er schafft mit FP Unit schlappe 13kHz bis 16kHz. Schwankt anscheinend je > nach Werten. Relativiere Deine Ansprüche, das ist ein ausgesprochen guter Wert! Das Ergebnis läßt mich vermuten, dass Du double gerechnet hast; da nützt die FPU garnichts. Ein Vergleich mit meinem double_test ergibt eine Beschleunigung etwa um den Faktor 50, wobei die Taktfrequenz 'nur' rund Faktor 8 größer ist.
Ja wurde mit double gerechnet. Meine Ansprüche passen schon ;-) Habe noch nichts gefunden für das dieser Kontroller zu langsam wäre. Aber wenn der TO schneller werden will, muss er seinen Code optimieren. Das wollte ich damit sagen. Das er hier "nur" mit schnellerem Core zum Ergebnis kommt, ist somit relativ unwahrscheinlich.
Jürgen H. schrieb: > Ja wurde mit double gerechnet. Kannst Du vielleicht kurz noch mit float rechnen? Mich würde interessieren, ob man damit auf 100k Durchläufe/s kommt :-)
Hallo, ja, einen Kalman-Filter kann man sehr wohl in Fixpoint umsetzen; eine allgemeine Implementierung dürfte allerdings schwierig sein, da man tatsächlich den Wertebereich entsprechend der Applikation bestimmen und berücksichtigen muss. In meinem Fall diente der Filter dazu, eine Fahrzeuggeschwindigkeit zu glätten und Rückkopplungen zu minimieren. Eingangs- und Ausgangsgrößen als SFix16, Zwischenergebnisse mit SFix32 funktionierten hier sehr gut. Implementierung kann ich allerdings nicht liefern, gehört meinem Arbeitgeber... Schöne Grüße, Martin
Um nochmal auf den AVR zurückzukommen: rechnet der überhaupt mit Double? Das wurde doch automatisch durch Float ersetzt?
Mike schrieb: > Um nochmal auf den AVR zurückzukommen: rechnet der überhaupt mit Double? Noe. Auf einem AVR sind float, double und long double alle 4 Byte breit.
m.n. schrieb: > > Kannst Du vielleicht kurz noch mit float rechnen? > Mich würde interessieren, ob man damit auf 100k Durchläufe/s kommt :-) Mit float kommt man auf ca. 30kHz.
Jürgen H. schrieb: > Mit float kommt man auf ca. 30kHz. Danke für den Test; hier hätte ich mehr erwartet. Aber dennoch ist das Teil affenschnell :-) Kaj schrieb: > Mike schrieb: >> Um nochmal auf den AVR zurückzukommen: rechnet der überhaupt mit Double? > Noe. Auf einem AVR sind float, double und long double alle 4 Byte breit. Das stimmt doch überhaupt nicht! Da habe ich oben extra eine ignorantensichere .hex-Datei angehängt. Aber Ignoranten machen eben das, was sie am besten können: sie ignorieren es :-( Ist es denn so schwer, mal ein bißchen zu lesen und zu verstehen?
Kaj schrieb: > Mike schrieb: >> Um nochmal auf den AVR zurückzukommen: rechnet der überhaupt mit Double? > Noe. Auf einem AVR sind float, double und long double alle 4 Byte breit. Der AVR macht da gar nix. Das macht wenn dann der Compiler. Und so wie du schreibst stimmt das auch nicht. Lies dir mal die Doku vom avr-gcc durch. Was stimmt: Es wird kein Unterschied zwischen float und double gemacht. Zumindest war das mal so.
Amateur schrieb: > Also wo ist das Problem? Das der kleine ATTiny mit endloser > Fließkommaarithmetik überfordert ist? Nein, der ATTiny war nur dafür da ein Gefühl für die Rechengeschwindigkeit zu bekommen. c-hater schrieb: > Die USART kann auch wesentlich schneller. Du mußt bloß den PC mit einer > entsprechend leistungsfähigen Gegenstelle ausrüsten. Es gibt PC-UARTs, > die mit knapp ein 1MBit/s zu laufen vermögen. Mein LAN->SERIELL Wandler bietet auch RS422 und RS485 an, jedoch möchte ich gerne bei der einfachen und fast an jedem PC vorhandenen RS232-Schnittstelle bleiben. Zudem ist die Ansteuerung in allen Programmiersprachen sehr einfach. Klar wäre mit höherem Aufwand auch eine Umsetzung mit usb oder besser noch direkt mit LAN-Port möglich, allerdings sprengt dies sicher den zeitlichen Rahmen -> In diesem Falle meinen persöhnlichen. Juergen G. schrieb: > Ist bei der Aufgabe der Weg das Ziel oder die Steuerung der Maschine? Juergen G. schrieb: > LCNC beherrscht auch schon weit kompliziertere Kinematiken als delta. Sowohl als auch, seinerzeit habe ich mich bei der Drehmaschine für Mach3 und gegen LCNC entschieden, jedoch gibt es hier nur rechwinkelige und rotatorische serielle Kinematiken. Falls mir der Aufwand zu groß erscheint ist ein Lösung auf so einer Basis natürlich auch noch möglich. Allerdings ist der gestalterische Freiraum bei eigenen Steuerungen halt wesentlich größer, mathematische Funktionen z.B. habe ich immer von einem Java-Programm in interpolierten G-Code schreiben lassen und damit Mach3 gefüttert (z.B. Prototypen-Reflektoren o.ä.), ist aber halt auch nicht das gelbe vom Ei. m.n. schrieb: > float_test.hex (eff. 2642 Byte Codegröße) > braucht pro Schleifendurchlauf ca. 950µs @ 16MHz, was umgerechnet auf > die maximal möglichen 20MHz eine Durchlaufrate von 1300/s ergibt. Das sind auf jeden Fall schon einmal einige Hz mehr als gedacht. Jürgen H. schrieb: > Er schafft mit FP Unit schlappe 13kHz bis 16kHz. Schwankt anscheinend je > nach Werten. > > Glaube da wirst du um das Optimieren nicht drum herum kommen. Das ist natürlich schon solide, aber würde trotzdem nicht reichen, abgesehen davon, dass Interrupthandling und Kommunikation ja auch noch fehlen. Mein alter Core2 Duo schafft die Berechnung bei 1596000 /s während ich hier parallel tippe, ist leider in der akt. Config nicht echtzeitfähig :-) Vielleicht muss ich mich von der Standalone-Lösung wirklich verabschieden, oder halt noch einen kleinen PC als Bahnrechner einplanen. Oder aber ich muss meine Ansprüche doch deutlich reduzieren. Wenn tatsächlich nur die Bewegungsdaten übergeben werden könnte man: 1) theoretisch ja effektiv 11520 Byte/s über die RS232-Schnittstelle schieben, 2) damit hätte der besagte PIC32 (32768 byte Ram) Platz für fast 3 Sekunden Fahrtdaten, 3) in jedem byte die fahrdaten kodieren als Bit0 und Bit1 Befehlsart, Bit 2 bis 7 Achse Schritt ja/nein Drehrichtung (ggf. würde eine Reduzierung der Datebits auf 7 noch was helfen, dann wäre bit0=0->Fahrdaten bit0=1 anderer Befehl folgt.. legt sich dann nur etwas schlecht zu je 7 bit blöcken im Speicher ab - oder? Oder man verschenkt halt je ein bit. Aus Definition 3 würde sich dann ergeben dass auch max. 11520 Fahrbefehle pro Sekunde möglich wären, damit ergibt sich bei 3200 Schritten eine Verfahrgeschwindigkeit von 14,4mm / sec, bei Reduzierung auf 800 Schritte wären schon 57,6 mm/sec möglich, allerdings nur noch bei einer Auflösung von 5/1000 (Ich denke die ganzen 3D-Printer-Boards haben keine Geschwindigkeitsprobleme, da solche Auflösungen dort ohnehin Nonsens wären). Damit würde sich die Firmware auf RS232-Kommunikation, Pufferung und PIN-Toggeln bei Timer-Interrupt reduzieren, alles anderen kommt dann vom Leitrechner, sogar die Rampen wären dann im Datenstrom eingebaut. Für die Aufgabe wäre der PIC32 schon fast zu schade. Da würde ein Atmega dicke reichen. Es bleibt die Frage wie ich den Puffer mit möglichst wenig Leiterbahen erweitern kann? Gibt es hier eine hinreichend schnelle Speicherschnittstelle und einfach zu händelnde (SD)RAM-Module? (um den letzen Gedanken mal weiterzuführen) Gruß Dominik
Ein i.MX6 mit einem aktiven Kern schafft ohne weitere Optimierungen schon mal gut 80kHz. Und Dominik V. schrieb: >>> Ursprünglich war geplant die Endstufen mit maximal 26000 Hz zu fahren Ziel erreicht... ;-)
Dominik V. schrieb: > Mein alter Core2 Duo schafft die Berechnung bei 1596000 /s Mach Dir damit doch mal einen Steckbrettaufbau :-) Bei einem Blick über den hiesigen Tellerrand, würden sich auch Renesas SH2-Prozessoren anbieten. Als erste verfügbare 'Hausnummer' würde mir der SH7214/7216 einfallen, der eine FPU mit single+double-Genauigkeit bietet, mit 200MHz rennt und bis zu zwei Befehle gleichzeitig abarbeiten kann. Bei STM32F4-Fans dürfte er allerdings ziemlich unbekannt sein/bleiben. Das Wetter ist heute aber zu schön, um die Geschwindigkeit im Simulator zu ermitteln :-)
Lothar Miller schrieb: > Ein i.MX6 mit einem aktiven Kern schafft ohne weitere Optimierungen > schon mal gut 80kHz. > Und Dominik V. schrieb: >>>> Ursprünglich war geplant die Endstufen mit maximal 26000 Hz zu fahren > Ziel erreicht... ;-) Hm, mit so einem Boliden würde es auch gehen. Oder einen aktuellen Micro / Nano-ITX raussuchen der noch einen Parallelport hat, dann könnte man das ganze auch mit DOS und Turbo C erreichen :-) m.n. schrieb: > Dominik V. schrieb: >> Mein alter Core2 Duo schafft die Berechnung bei 1596000 /s > > Mach Dir damit doch mal einen Steckbrettaufbau :-) Ich vermute den bekomme ich auch nicht als DIL/DIP... Wenn jemand einen Adapter von Sockel 775 da hat, könnte man es ja mal probieren :-)
Pentium gibts ja mit der Weile fürs Steckboard "Galileo"
Blubblub schrieb: > Pentium gibts ja mit der Weile fürs Steckboard "Galileo" Was es nicht alles gibt, also einen Prozessor zu finden der das in Echtzeit macht wird also nicht ganz so schwer. Trotzdem werde ich das Projekt jetzt erstmal etwas "verbiegen" und es in einen Atmega328P stopfen, damit kann ich dann die Mechanik zumindest schon mal fertigstellen und testen. Zudem kann ich meine etwas angestaubten Programmierfähigkeiten wieder auffrischen. Da ich am Wochenende das zweifelhafte Vergnügen hatte ein optisches Mikrometer für den Einsatz in unserer QS auf Herz und Nieren zu testen ist das Thema mit der Übertragung der kompletten Bewegungs-Tupel per RS232 vom Tisch, das neue Gerät hat mich ganz schön Nerven gekostet und an meinen Programmierkünsten zweifeln lassen. Irgendwann habe ich dann das durchprobieren der Einstellungen sein lassen und einen ATMega ein paar Dummy-Messwerte generieren (gemäß Anleitung des Mikrometers) und an das Testprogramm auf dem PC schicken lassen, und siehe da, das ging. Koffer auf, Messgerät rein, Koffer zu Bericht schreiben(das Oszi-Bild vom Atmega war wie gemahlt, das andere hatte mehr was von nem Rockkonzert). Was allerdings davon übrig ist, die Erkenntnis, dass das geplante Übertragen der Schrittdaten viel zu nah an der maximalen Übertragungsrate liegt, dann noch ein zwei Frequenzumrichter in der Nähe, etc. pp., das wird nix (komisch das man manche Erkenntnis im Leben öfter gewinnt). Also zurück zum Ausgang: Wenn ich vorerst mit 1/100 Genauigkeit leben Kann, komme ich bei der angestrebten Verfahrgeschwindigkeit auf eine viel niedrigere Frequenz als ursprünglich, es müssten dann zwischen 4 und 5 kHz ausreichen um akzeptabel schnell zu verfahren. Der Atmega328P in meinem Steckbrett läuft mit 18,432 MHz, damit bleiben für alle Operationen etwa 3680 bis 4600 Ticks, das ist schon mal etwas Spielraum. Die schöne Assembler Version der 32 bit Wurzel hier auf der Seite soll ja "nur" 310 Ticks max. dauern, bei meiner aktuellen Maschinendimensionierung würden 32bit gerade so eben reichen wenn ganzzahlig auf 1/100 mm gerechnet würde, ist allerdings dann fast kein Spielraum. Meine Assemblerkenntinsse sind im Moment nahe NUll, weiss jemand welche Anderungen an der Funktion nötig sind um auf mehr bits zu kommen und wie sich dann die Laufzeit ändert? Da zudem bei jedem Schritt die vorherigen Werte ja bekannt sind bietet sich vielleicht sogar eine Näherungsfunktion mit "gut gewähltem" Startwert für die Wurzel an. Hierzu jemand Ideen oder Erfahrungen? Und noch eine wahrscheinlich blöde Frage zum Schluss: wie viel Programmieraufwand steckt hinter eigenen Datentypen a la uint40_t und uint20_t, oder so ähnlich (Definition/Arithmetik)? Gruß Dominik
Angehängte Dateien:
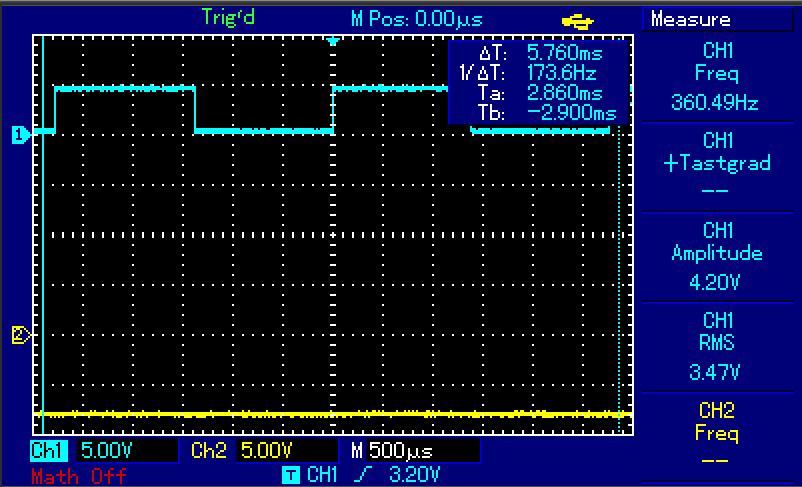
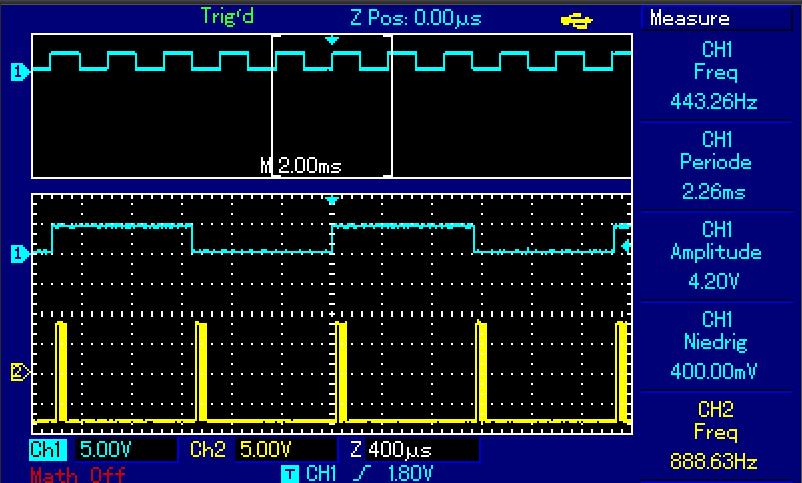
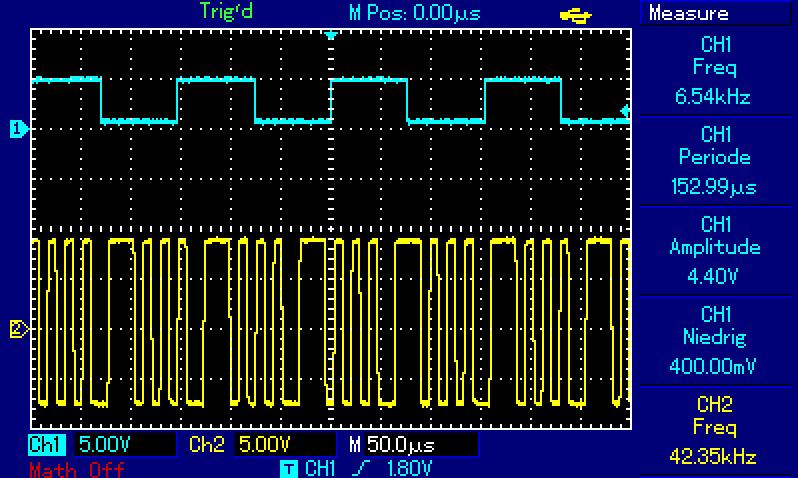
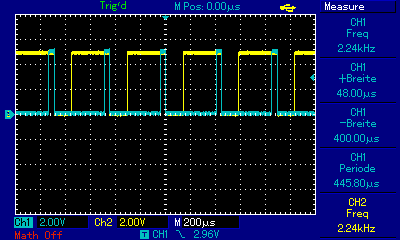
Hallo, so sieht das Ergebnis auf einem ATMega328P bei 18,432 Mhz aus. 1) Das Original-Benchmark (DOUBLE) gibt 360Hz Ausgabefrequenz. 2) Das Benchmark (DOUBLE) ohne Sinusfunktion gibt 443 Hz Ausgabefrequenz. 3) Die Nutzung der SQRT32_ROUND mit uint32_t ohne Sinus ergbit 6,5 kHz Verbesserung von Fließkomma zu Ganzzahl damit fast Faktor 15, auf Kanal 2 zwei läuft schon das RS232-Signal bei 115200 BAUD mit. Damit scheinen die oben angestrebten Ausgabefrequenzen durchaus erreichbar, mal sehen welche Taktraten nach Bahninterpolation, EEPROM lesen und Abfrage der Eingänge übrig bleiben, Auflösung jetzt allerdings "nur" noch 1/100 mm. Spannende Frage: wie schnell schafft das der PIC32? Gruß Dominik
Angehängte Dateien:
-

Atmega328p_Delta_001.JPG
72 KB
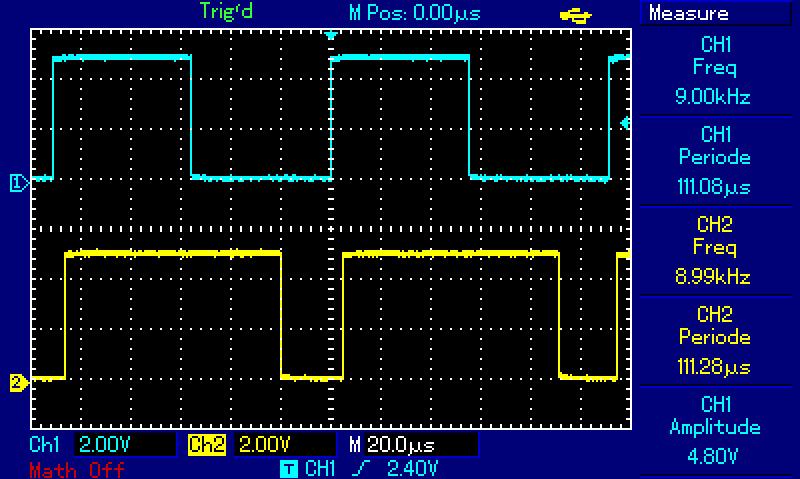
Hallo zusammen, als Dank für die ganzen Feedbacks und Anregungen, im folgenden der Stand der Dinge. Ich war leider 30% der letzen Woche im Ausland, also geht es etwas schleppend voran. Allerdings gibt es wieder einen Erfolg zu vermelden, der Atmega328p wird die Standalone-Lösung im 1/100 Bereich schaffen. Das aktuelle OSZI-Bild im Anhang ist der Beweis. Das Programm arbeitet derzeit (nur) im Linear-Modus, sprich direkt Fahrt von P1 nach P2 und zurück. Zu jedem Punkt werden die drei Z- Achsenpositionen berechnet, Änderungen werden als Schrittinformation für alle drei Achsen + 4. Drehachse in ein Byte codiert (Bits 1 bis 8 für je Richtung und Takt). (Leider hat der Atmega keine 8 nutzbaren Portpins in Folge um die spätere 4. Achse anzuschließen, daher wird das Byte ab Bit 6 geteilt). Das Byte wird in einen 1024 Byte langen FIFO gespeichert (Füllzustand des FIFO´s geht u.A. in die Rampenberechnung ein, daher so groß). Das erste BIT wird derzeit immer zu 1 verfälscht um ein 50/50 Signal auf PB0 zu erzeugen, dieses ist im Anhang das obere Signal. Die Ausgabefrequenz konnte bis auf 9kHz gesteigert werden, was eine theoretische Verfahrgeschwindigkeit von 90mm/sec ermöglichen würde, weit mehr als ich benötige (bei dieser Auflösung). Das untere Signal zeigt die Verteilung der Prozessoraktivität bei dieser hohen Taktrate: die HIGH-Bereiche sind die Berechnungen mit den Wurzelfunktionen für die z-Achsen, die LOW-Bereiche werden für die Linearinterpolation (Versatz der steigenden Flanken unten und oben) und die Kommunikation via RS232 (Sende-Polling) benutzt. (Mit dem TX&Datenregister- Interrupts war der Overhead viel zu groß). Der Controller gibt so parallel immer noch etwa 20 Positionsinformationen/s zu allen Achsen und der Werkzeugposition im Klartext aus. Bei niedrigeren Taktraten entsprechend wesentlich mehr. Es bleibt zwar noch viel zu tun, aber der 2,50€ Prozessor reicht tatsächlich aus, damit ist die Eröffnungsfrage mit Jein zu beantworten. Gruß Dominik
wenn die Pins gehlen vielleicht einen Latch dazu nehmen 74HC(T)573 im Prinzip ein Fire and forget Baustein. Daten übergeben und mit deinem Port kannst du dich wieder um andere Sachen kümmern.
Angehängte Dateien:
-

MAP001.png
2,4 KB
Hallo zusammen, ich bin jetzt etwas weiter in der Entwicklung, als auch in der Erkenntnis ;-) Der nachfolgende Code läuft auf einem ATMega1284P (18,432MHz), diesen µC werde ich auch einsetzen wollen, der Quelltext ist noch nicht komplett, jedoch sind die zeitraubenden Berechnungen schon implementiert, leider braucht der ATMega für die Beispiel-Berechnung fast 20 Sekunden, dies ist nicht wirklich akzeptabel, wenn der Code fertig ist, wird es noch länger dauern. Obwohl die Berechnungen auf SD-Karte (Danke für den Tipp) zwischengespeichert werden, wäre die DOWN-Time der Anlage viel zu hoch. Da die Zahlenwerte auf Grund der Maschinengeometrie nicht von einem Steuerrechner im Vorfeld berechnet und anschließend verschoben werden können, muss mit jedem neu gesetzten Nullpunkt das komplette Programm neu berechnet werden. Im Moment erwäge ich dies entweder über: a) den Steuerrechner via RS232 machen zu lassen, was mir aber auf Grund der begrenzten Datenraten nicht gefällt und ich zudem das Programm vorzugsweise via Tablet und WLAN über XPORT aufspielen wollte (dann Shoot and Forget). b) weitere Prozessoren einzusetzen: b1) eine Hand voll Atmegas oder Tinys, die parallel einzelne Programmabschnitte berechen, ggf. via SPI angebunden. b2) einen anderen im DIL-Format verfügbaren µC einzusetzen, vorzugsweise den PIC32 (28er Dip 40MHz) und diesen die Daten direkt auf die SD-Karte schreiben lassen, die der Atmega dann anschließend von da wieder abholt. Zu b2 würde ich mir gerne hier nochmal Hilfe einholen, da ich für den PIC weder Entwicklungsumgebung installiert noch Grundkenntnisse habe und mich zum jetzigen Zeitpunkt ungern erst einarbeiten würde um dann festzustellen, es lohnt nicht... Kann jemand den nachfolgenden Quelltext (wesentliche Teile zusammenkopiert) mal auf einem PIC auf Ausführungsdauer prüfen? (Anmerkung zum Anhang: Die gelbe steigende Flanke zeigt das Ende der Multiplikation- & Division, die blaue das Ende der Wurzelberechnungen.)
1 | #define rColumn1 +60000LL
|
2 | #define rColumn1sqr (rColumn1*rColumn1)
|
3 | #define xColumn1 -30000LL
|
4 | #define yColumn1 +00000LL
|
5 | |
6 | #define rColumn2 +60000LL
|
7 | #define rColumn2sqr (rColumn2*rColumn2)
|
8 | #define xColumn2 +15000LL
|
9 | #define yColumn2 +25981LL
|
10 | |
11 | #define rColumn3 +60000LL
|
12 | #define rColumn3sqr (rColumn3*rColumn3)
|
13 | #define xColumn3 +15000LL
|
14 | #define yColumn3 -25981LL
|
15 | |
16 | int main(void) |
17 | {
|
18 | DDRB |= (1<<PB0); |
19 | DDRB |= (1<<PB1); |
20 | |
21 | do //Hauptprogramm - Endlose Schleife |
22 | {
|
23 | linearMoveTo(0, 0, 0, 0, 27501, 27500, 3000, 500); |
24 | }
|
25 | while(1); |
26 | }
|
27 | |
28 | void linearMoveTo(int32_t x1, int32_t y1, int32_t z1, int32_t a1, int32_t x2, int32_t y2, int32_t z2, int32_t a2) |
29 | {
|
30 | register int32_t x1x2=x2-x1; |
31 | register int32_t y1y2=y2-y1; |
32 | register int32_t z1z2=z2-z1; |
33 | register int32_t a1a2=a2-a1; |
34 | |
35 | register int32_t x=0; |
36 | register int32_t y=0; |
37 | register int32_t z=0; |
38 | register int32_t a=0; |
39 | |
40 | register int32_t zColumn1=0; |
41 | register int32_t zColumn2=0; |
42 | register int32_t zColumn3=0; |
43 | |
44 | int32_t length=sqrtXX_floorC((x1x2*x1x2)+(y1y2*y1y2)+(z1z2*z1z2)+(a1a2*a1a2)); |
45 | for(int32_t i=0; i<=length; i++) |
46 | {
|
47 | PORTB&=~((1<<PB0)|(1<<PB1)); |
48 | //PORTB&=~(1<<PB1);
|
49 | |
50 | x=x1+(i*x1x2)/length; |
51 | y=y1+(i*y1y2)/length; |
52 | z=z1+(i*z1z2)/length; |
53 | a=a1+(i*a1a2)/length; |
54 | |
55 | PORTB|=(1<<PB0); |
56 | |
57 | zColumn1=sqrtXX_floorC(rColumn1sqr-((x-xColumn1)*(x-xColumn1))-((y-yColumn1)*(y-yColumn1)))+z; |
58 | zColumn2=sqrtXX_floorC(rColumn2sqr-((x-xColumn2)*(x-xColumn2))-((y-yColumn2)*(y-yColumn2)))+z; |
59 | zColumn3=sqrtXX_floorC(rColumn3sqr-((x-xColumn3)*(x-xColumn3))-((y-yColumn3)*(y-yColumn3)))+z; |
60 | |
61 | PORTB|=(1<<PB1); |
62 | }
|
63 | }
|
64 | |
65 | uint8_t sqrt16_floorC(uint16_t square16) |
66 | {
|
67 | register uint16_t root=0; |
68 | register uint16_t remainder=square16; |
69 | register uint16_t place=0x4000; |
70 | |
71 | while(place > remainder) |
72 | place = place>>2; |
73 | |
74 | while(place) |
75 | {
|
76 | if(remainder>= root+place) |
77 | {
|
78 | remainder = remainder - root - place; |
79 | root = root +(place<<1); |
80 | }
|
81 | root = root>>1; |
82 | place = place>>2; |
83 | }
|
84 | return root; |
85 | }
|
86 | |
87 | uint16_t sqrt32_floorC(uint32_t square32) |
88 | {
|
89 | register uint32_t root=0; |
90 | register uint32_t remainder=square32; |
91 | register uint32_t place=0x40000000UL; |
92 | |
93 | while(place > remainder) |
94 | place = place>>2; |
95 | |
96 | while(place) |
97 | {
|
98 | if(remainder>= root+place) |
99 | {
|
100 | remainder = remainder - root - place; |
101 | root = root +(place<<1); |
102 | }
|
103 | root = root>>1; |
104 | place = place>>2; |
105 | }
|
106 | return root; |
107 | }
|
108 | |
109 | uint32_t sqrt64_floorC(uint64_t square64) |
110 | {
|
111 | register uint64_t root=0; |
112 | register uint64_t remainder=square64; |
113 | register uint64_t place=0x4000000000000000ULL; |
114 | |
115 | while(place > remainder) |
116 | place = place>>2; |
117 | |
118 | while(place) |
119 | {
|
120 | if(remainder>= root+place) |
121 | {
|
122 | remainder = remainder - root - place; |
123 | root = root +(place<<1); |
124 | }
|
125 | root = root>>1; |
126 | place = place>>2; |
127 | }
|
128 | return root; |
129 | }
|
130 | |
131 | uint32_t sqrtXX_floorC (uint64_t square64) |
132 | {
|
133 | if(square64<65536ULL) |
134 | {
|
135 | return sqrt16_floorC(square64); |
136 | }
|
137 | else if(square64<4294967296ULL) |
138 | {
|
139 | return sqrt32_floorC(square64); |
140 | }
|
141 | else
|
142 | {
|
143 | return sqrt64_floorC(square64); |
144 | }
|
145 | }
|
Eine Umsetzung der Wurzelfunktionen in Assembler wäre natürlich auch was, aber der Unterschied zwischen der Ruud v Gessel Variante und der oben gelisteten 32bit Wurzel ist auf dem OSZI kaum erkennbar wenn mit -O2 compiliert wird... Gruß Dominik
Mal rein aus Interesse: Hast du das mal mit Floating Point versucht, bzw. wieviel langsamer ist das damit? Für Wurzelziehen gibt es da ja die Fast Inverse Square Root...
Dominik V. schrieb: > Da die Zahlenwerte auf Grund der Maschinengeometrie nicht von einem > Steuerrechner im Vorfeld berechnet und anschließend verschoben werden > können Naja, einfach verschieben geht natürlich nur bei translatorischen Achsen mit gemeinsamem Bezugssystem. Aber wen man die Sache etwas cleverer angeht, kann man durchaus auch Programme "verschieben", bei denen die Zielmechanik eine Hierarchie beliebiger rotatorischer und linearer Achsen ist. Matrixtransformationen müssen nicht erst erfunden werden und und die einzigen anspruchsvolleren Operationen dabei sind sin und cos, welche sich durch eine entsprechende Lookup-Tabelle extrem schnell "berechnen" lassen. Allerdings muß das Datenformat natürlich entsprechend erweitert werden, es muß auch die Achsenhierarchie abbilden. Vielleicht ziehst du dir mal Robotersteuerungen rein, bevor du anfängst, völlig von Null irgendwas eigenes zu frickeln? Du brauchst die ja nicht 1:1 nachzubauen, aber die guten Ideen von Leuten, die sich mit sowas auskennen, kann man schon übernehmen...
Auf dem erwähnten SAM3X @84Mhz messe ich 6120 Durchläufe/s vom orginalen Code ohne besondere ARM-spezifische Optimierungen.
Hallo, also Floating Point wurde zu Anfang getestet, war aber um einige groessenordnungen langsamer. Daher der Wechsel auf festkomma, resp. Ganzzahlen aber leider jetzt zum Teil 64 bit. c-hater schrieb: > Dominik V. schrieb: > > Da die Zahlenwerte auf Grund der Maschinengeometrie nicht von einem > Steuerrechner im Vorfeld berechnet und anschließend verschoben werden > können > > Naja, einfach verschieben geht natürlich nur bei translatorischen Achsen > mit gemeinsamem Bezugssystem. > > Aber wen man die Sache etwas cleverer angeht, kann man durchaus auch > Programme "verschieben", bei denen die Zielmechanik eine Hierarchie > beliebiger rotatorischer und linearer Achsen ist. Matrixtransformationen > müssen nicht erst erfunden werden und und die einzigen anspruchsvolleren > Operationen dabei sind sin und cos, welche sich durch eine entsprechende > Lookup-Tabelle extrem schnell "berechnen" lassen. > > Allerdings muß das Datenformat natürlich entsprechend erweitert werden, > es muß auch die Achsenhierarchie abbilden. > > Vielleicht ziehst du dir mal Robotersteuerungen rein, bevor du anfängst, > völlig von Null irgendwas eigenes zu frickeln? Du brauchst die ja nicht > 1:1 nachzubauen, aber die guten Ideen von Leuten, die sich mit sowas > auskennen, kann man schon übernehmen... mmh, also berechnet werden die schrittbefehle pro vier Achsen als Takt-Richtung jeweils in ein Byte kodiert, dieser bytestrom wird zwischengespeichert und dann zweifach maskiert und getimt auf dem Port ausgegeben. Wichtig bei der eigenen Umsetzung ist mir u.a. die genaue Kenntnis des Programmablaufes, aber spieken erlaube ich mir natürlich auch ab und an. Bei meiner angestrebten Maschine liegen die 3 z-Achsen nahezu parallel, in sofern kann man schrittfolgen in z-Richtung verschieben, jedoch sehe ich keine moeglichkeit in x und y? egal wie, der rechenaufwand wir doch dann eher groesser? Sofern ich das ganze nur noch etwas beschleunigen kann, wäre das ja vielleicht schon ausreichend. Matthias schrieb: > Matthias schrieb: > 6120 Durchläufe/s > > Es es zu früh. Falsche Zeitbasis. Es sind ca 20500/s 20500 komplette durchläufe aber nicht, oder? 20500 Hz auf den Ausgabepins oder? wäre ja auch schon fast Faktor 10... was ist denn eigentlich von den dspics zu halten? sind die bei dem vorliegen Programm wohl schneller oder langsamer als ein pic32 bei 40 MHz? viele Grüße Dominik
Dominik V. schrieb: > mmh, also berechnet werden die schrittbefehle pro vier Achsen als > Takt-Richtung jeweils in ein Byte kodiert, dieser bytestrom wird > zwischengespeichert und dann zweifach maskiert und getimt auf dem Port > ausgegeben. Was du zur Programmlaufzeit machst ist eine Sache. Was du zur "Entwurfszeit" machst (hier also das "Verschieben" des Programmes) eine ganz andere. Das Verhältnis ist in etwa so wie zwischen dem Quelltext eines Programmes, welches zum großen Teil in vorkompilierten Modulen vorliegt und welches in automatisierten Build-Läufen in verschiedenen Varianten immer wieder neu mit nur gering abweichendem glue code gebaut wird und den entstehenden Binaries. Die komplizierte Sache (das Kompilieren) braucht nur für das bissel glue code immer wieder neu erfolgen, der fette Rest muß nur neu untereinander und mit den neuen Modulen gelinkt werden. Dein Job ist es also eigentlich, dir eine "Sprache" auszudenken, die die Achsenhierarchien (also letztlich die Bewegungen der verschiedenen Bezugssysteme zueinander) und die Bewegungsdetails innerhalb der Bezugssysteme voneinander entkoppelt darstellen kann. Das Binärformat des Endproduktes hast du dir ja schon ausgedacht und die komplette Berechnung des Endproduktes auf dem PC auch. Dir fehlt bloß noch der Plan, wie man die PC-Berechnungen in zwei Gruppen zerlegt (von denen dann eine später auch auf dem µC abgearbeitet werden kann). Und ein Datenformat, in dem der Zustand zwischen der Berechnungen dieser zwei Gruppen sozusagen eingefroren werden kann. Das entspricht dann in etwa den *.obj-Files eines C-Compilers, um bei meinem Vergleich zu bleiben. > Bei meiner angestrebten Maschine liegen die 3 z-Achsen > nahezu parallel, in sofern kann man schrittfolgen in z-Richtung > verschieben, jedoch sehe ich keine moeglichkeit > in x und y? egal wie, der rechenaufwand wir doch dann > eher groesser? Mal Butter bei die Fische: Was sind das alles für Achsen? Die Benennung X, Y, Z spricht eigentlich für translatorische Achsen in einem festen Raumwinkel zueinander. Dafür braucht man überhaupt keine hierarchische Kinematik und das Verschieben des Programms beschränkt sich maximal auf das einmalige Berechnen eines Vektors (das entfällt, wenn die Achsen die Kanten eines Würfels bilden) und dann viele Additionen. Oder fehlen da eventuell noch ein paar Achsen, die du schlicht nicht als solche erkennst? Dafür spricht wiederum die Formulierung "fast parallel" für die drei Inkarnationen der Z-Achse. Also ich fürchte, wenn du dir nichtmal über das mathematische Modell der Mechanik im Klaren bist, kann auf der Softwareseite auch nur Scheiße entstehen...
Dominik V. schrieb: > was ist denn eigentlich von den dspics zu halten? > sind die bei dem vorliegen Programm wohl schneller oder langsamer als > ein pic32 bei 40 MHz? dsPICs sind 16 Bit Controller, d.h. 32 Bit Operationen erfordern mehrere Befehle. Dazu gibt es eine DSP-Einheit mit zwei 56 Bit Akkus, und zusätzlichen Befehlen, die speziell für Algorithmen aus der Signalverarbeitung optimiert sind. Für die Nutzung der DSP-Einheit gibt es spezielle Intrinsics, die Du dann benutzen musst, normaler C-Code benutzt die DSP-Einheit nicht. Die dsPIC33EP laufen mit 70 MHz im Vergleich zu den 50 MHz der PIC32MX1xx/2xx. Zusammenfassend: Wenn Dein Code die DSP-Einheit gut nutzen kann, ist dsPIC33EP schneller, ansonsten hat PIC32MX die höhere Rechenleistung Es hängt stark von Code ab. fchk
Hallo, c-hater schrieb: > Dominik V. schrieb: > >> mmh, also berechnet werden die schrittbefehle pro vier Achsen als >> Takt-Richtung jeweils in ein Byte kodiert, dieser bytestrom wird >> zwischengespeichert und dann zweifach maskiert und getimt auf dem Port >> ausgegeben. > > Was du zur Programmlaufzeit machst ist eine Sache. Was du zur > "Entwurfszeit" machst (hier also das "Verschieben" des Programmes) eine > ganz andere. > > Das Verhältnis ist in etwa so wie zwischen dem Quelltext eines > Programmes, welches zum großen Teil in vorkompilierten Modulen vorliegt > und welches in automatisierten Build-Läufen in verschiedenen Varianten > immer wieder neu mit nur gering abweichendem glue code gebaut wird und > den entstehenden Binaries. > > Die komplizierte Sache (das Kompilieren) braucht nur für das bissel glue > code immer wieder neu erfolgen, der fette Rest muß nur neu untereinander > und mit den neuen Modulen gelinkt werden. > > Dein Job ist es also eigentlich, dir eine "Sprache" auszudenken, die die > Achsenhierarchien (also letztlich die Bewegungen der verschiedenen > Bezugssysteme zueinander) und die Bewegungsdetails innerhalb der > Bezugssysteme voneinander entkoppelt darstellen kann. Das Binärformat > des Endproduktes hast du dir ja schon ausgedacht und die komplette > Berechnung des Endproduktes auf dem PC auch. > > Dir fehlt bloß noch der Plan, wie man die PC-Berechnungen in zwei > Gruppen zerlegt (von denen dann eine später auch auf dem µC abgearbeitet > werden kann). > Und ein Datenformat, in dem der Zustand zwischen der Berechnungen dieser > zwei Gruppen sozusagen eingefroren werden kann. Das entspricht dann in > etwa den *.obj-Files eines C-Compilers, um bei meinem Vergleich zu > bleiben. > >> Bei meiner angestrebten Maschine liegen die 3 z-Achsen >> nahezu parallel, in sofern kann man schrittfolgen in z-Richtung >> verschieben, jedoch sehe ich keine moeglichkeit >> in x und y? egal wie, der rechenaufwand wir doch dann >> eher groesser? > > Mal Butter bei die Fische: Was sind das alles für Achsen? Die Benennung > X, Y, Z spricht eigentlich für translatorische Achsen in einem festen > Raumwinkel zueinander. Dafür braucht man überhaupt keine hierarchische > Kinematik und das Verschieben des Programms beschränkt sich maximal auf > das einmalige Berechnen eines Vektors (das entfällt, wenn die Achsen die > Kanten eines Würfels bilden) und dann viele Additionen. > > Oder fehlen da eventuell noch ein paar Achsen, die du schlicht nicht als > solche erkennst? Dafür spricht wiederum die Formulierung "fast parallel" > für die drei Inkarnationen der Z-Achse. > > Also ich fürchte, wenn du dir nichtmal über das mathematische Modell der > Mechanik im Klaren bist, kann auf der Softwareseite auch nur Scheiße > entstehen... Da der Thread schon was laenger ist: es geht um eine Parallelkinematik im Delta-Stil. Die Achsen sind wie folgt: X, Y und Z sind die gedachten Achsen eines kartesischen Koordinatensystemes und die Eingabewerte im G-Code. Dazu kommt eine reelle Drehachse A, frei montierbar. Die 3 Zn-Achsen sind die reellen, senkrecht zur Ebene XY-Ebene stehenden Achsen, die in etwa angepeilten Koordinaten sind oben im Quelltext in 1/100mm zu erkennen. Das Schrittmuster enthaelt daher bereits die umgerechneten Koordinaten für x,y,z lediglich a wird nur skaliert. Für die umgekehrte Berechnung aus z1, z2 und z3 muss der Anzeige-Pc ein lineares Gleichungssystem lösen. Da das Werkstück nicht immer 100% wiederholgenau gespannt werden kann, muss nach dem Einspannen das Programmkoordinatensystem genullt werden, es entsteht also jeweils ein neuer Offset zum Maschinenkoordinatensystem. Die Berechnung muss meines Erachtens nach dann jeweils neu durchgeführt werden um ein gültiges Schrittmuster zu erhalten wenn nicht nur in Z-Richtung verstellt wurde. Die besonderen Eigenheiten der Achsen gehen natuerlich noch in den Quelltext ein, eine reine Z-Bewegung braucht keine Berechnung von 4D-Vektoren zur Bahninterpolation u.s.w. Allerdings gibt es halt groesstenteils diese Linearbewegungen. Für den Eilgang werde ich wahrscheinlich Funktionen einbinden, die einen Sicherheitsabstand anfahren und dann entsprechend den reellen Achsen bogenförmig verfahren. Der Hinweis "nahezu parallel" bezieht sich auf das Unvermoegen der Menschheit - insbesondere meines - drei Achsen im Raum tatsächlich parallel anzuordnen ;-) Über die Umsetzung eines "Delta-Codes" habe ich nachgedacht, aber aus o.g. Gründen dann verworfen. Sollte es theoretisch machbar gewesen sein, hätte ich jedoch starke Zweifel was die "Lesbarkeit" des Programms betrifft. Wie man es dreht und wendet, die Vektorrechnung wird sich nicht vermeiden lassen, da ich zudem eine kleine Bedien- und Anzeigeeinheit anbringen werde, wäre es nicht schlecht wenn man nach Anfahren des Werkstucknullpunktes, auch ohne Steuerrechner, einfach das Programm Starten könnte. Frank K. schrieb: > Dominik V. schrieb: > > was ist denn eigentlich von den dspics zu halten? > sind die bei dem vorliegen Programm wohl schneller oder langsamer als > ein pic32 bei 40 MHz? > > dsPICs sind 16 Bit Controller, d.h. 32 Bit Operationen erfordern mehrere > Befehle. Dazu gibt es eine DSP-Einheit mit zwei 56 Bit Akkus, und > zusätzlichen Befehlen, die speziell für Algorithmen aus der > Signalverarbeitung optimiert sind. Für die Nutzung der DSP-Einheit gibt > es spezielle Intrinsics, die Du dann benutzen musst, normaler C-Code > benutzt die DSP-Einheit nicht. > > Die dsPIC33EP laufen mit 70 MHz im Vergleich zu den 50 MHz der > PIC32MX1xx/2xx. > > Zusammenfassend: Wenn Dein Code die DSP-Einheit gut nutzen kann, ist > dsPIC33EP schneller, ansonsten hat PIC32MX die höhere Rechenleistung Es > hängt stark von Code ab. > > fchk Ok, in dem Falle wage ich einfach mal einen Test mit dem PIC32, wie ich im Datenblatt gesehen unterstützt der ja Hardware-seitig 32 bit Mul/Div, die Wurzel konnte ich ja auf Shift/Add und Sub reduzieren. Soweit ich das gesehen habe ist der freie C-Compiler nicht so besonders, sprich der Quelltext muss in Assembler geschrieben werden? Gruss Domink
Angehängte Dateien:
-

ATTiny45_64bit.png
2,4 KB -

ATMega1284_64bit.png
2,4 KB -

ATMega1284_float_1.png
2,3 KB -

ATMega1284_float_2.png
2,3 KB -

ATMega1284_float_3.png
2,3 KB
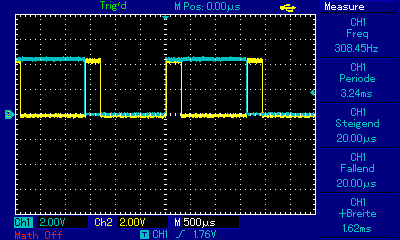
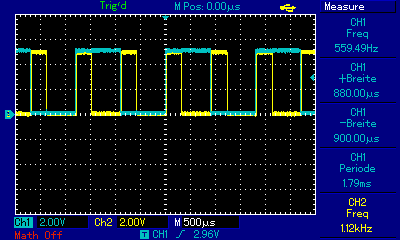
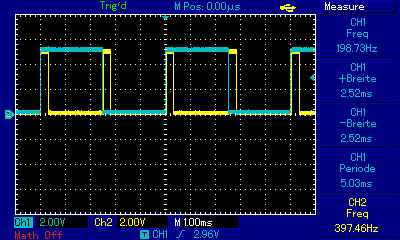
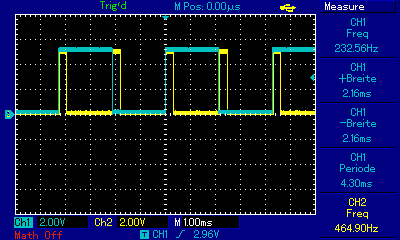
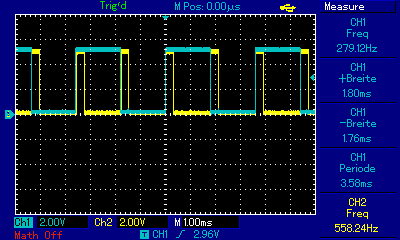
Ergänzend noch ein kleines Benchmark, habe den Quelltext nochmal umgestellt, funktioniert jetzt copy und paste, die Registervaraiblen sind auch testweise global, damit da nicht´s wegoptimiert wird. Da das PB1 Siganl (CH1) jetzt nach jedem Rechendurchlauf invertiert, sind die durchgeführten Rechenläufe pro sec = 2/ Hz. Zum besseren Vergleich laufen beide µC´s bei 8MHz. Der Hardware-Multiplier im ATMega ist also doch deutlich zu spüren. Getestet auf ATTiny45 mit 64 bit Ganzzahlen -> ~600 Berechnungen / sec Getestet auf ATMega1284P mit 64 bit Ganzzahlen -> ~1100 Berechnungen / sec Um die Frage nach der Fließkomma-Performance zu klären habe ich´s nochmal mit der sqrt aus Math.h compiliert, ist dann aber für den Tiny viel zu groß, daher nur die Werte des Atmega, diese variieren wohl je nach Quadratzahl. Er schaft bei ?32bit? Fliesskomma etwa 400 bis 560 Berechnungen. Den Test mit dem PIC32 musste ich abbrechen, mein Pickit 3 läuft nicht ;-( Würde mich freuen wenn jemand den Quelltext mal noch auf auf anderen µC´s laufen lassen könnte. Gruß Dominik
1 | #include <avr/io.h> |
2 | #include <inttypes.h> |
3 | #include <Math.h> |
4 | |
5 | #define rColumn1 +60000LL
|
6 | #define rColumn1sqr (rColumn1*rColumn1)
|
7 | #define xColumn1 -30000LL
|
8 | #define yColumn1 +00000LL
|
9 | |
10 | #define rColumn2 +60000LL
|
11 | #define rColumn2sqr (rColumn2*rColumn2)
|
12 | #define xColumn2 +15000LL
|
13 | #define yColumn2 +25981LL
|
14 | |
15 | #define rColumn3 +60000LL
|
16 | #define rColumn3sqr (rColumn3*rColumn3)
|
17 | #define xColumn3 +15000LL
|
18 | #define yColumn3 -25981LL
|
19 | |
20 | uint8_t sqrt16_floorC(uint16_t square16) |
21 | {
|
22 | register uint16_t root=0; |
23 | register uint16_t remainder=square16; |
24 | register uint16_t place=0x4000; |
25 | |
26 | while(place > remainder) |
27 | place = place>>2; |
28 | |
29 | while(place) |
30 | {
|
31 | if(remainder>= root+place) |
32 | {
|
33 | remainder = remainder - root - place; |
34 | root = root +(place<<1); |
35 | }
|
36 | root = root>>1; |
37 | place = place>>2; |
38 | }
|
39 | return root; |
40 | }
|
41 | |
42 | uint16_t sqrt32_floorC(uint32_t square32) |
43 | {
|
44 | register uint32_t root=0; |
45 | register uint32_t remainder=square32; |
46 | register uint32_t place=0x40000000UL; |
47 | |
48 | while(place > remainder) |
49 | place = place>>2; |
50 | |
51 | while(place) |
52 | {
|
53 | if(remainder>= root+place) |
54 | {
|
55 | remainder = remainder - root - place; |
56 | root = root +(place<<1); |
57 | }
|
58 | root = root>>1; |
59 | place = place>>2; |
60 | }
|
61 | return root; |
62 | }
|
63 | |
64 | uint32_t sqrt64_floorC(uint64_t square64) |
65 | {
|
66 | register uint64_t root=0; |
67 | register uint64_t remainder=square64; |
68 | register uint64_t place=0x4000000000000000ULL; |
69 | |
70 | while(place > remainder) |
71 | place = place>>2; |
72 | |
73 | while(place) |
74 | {
|
75 | if(remainder>= root+place) |
76 | {
|
77 | remainder = remainder - root - place; |
78 | root = root +(place<<1); |
79 | }
|
80 | root = root>>1; |
81 | place = place>>2; |
82 | }
|
83 | return root; |
84 | }
|
85 | |
86 | uint32_t sqrtXX_floorC (uint64_t square64) |
87 | {
|
88 | if(square64<65536ULL) |
89 | {
|
90 | return sqrt16_floorC(square64); |
91 | }
|
92 | else if(square64<4294967296ULL) |
93 | {
|
94 | return sqrt32_floorC(square64); |
95 | }
|
96 | else
|
97 | {
|
98 | return sqrt64_floorC(square64); |
99 | }
|
100 | }
|
101 | |
102 | int32_t x=0; |
103 | int32_t y=0; |
104 | int32_t z=0; |
105 | int32_t a=0; |
106 | |
107 | int32_t zColumn1=0; |
108 | int32_t zColumn2=0; |
109 | int32_t zColumn3=0; |
110 | |
111 | void linearMoveTo(int32_t x1, int32_t y1, int32_t z1, int32_t a1, int32_t x2, int32_t y2, int32_t z2, int32_t a2) |
112 | {
|
113 | register int32_t x1x2=x2-x1; |
114 | register int32_t y1y2=y2-y1; |
115 | register int32_t z1z2=z2-z1; |
116 | register int32_t a1a2=a2-a1; |
117 | |
118 | int32_t length=sqrtXX_floorC((x1x2*x1x2)+(y1y2*y1y2)+(z1z2*z1z2)+(a1a2*a1a2)); |
119 | for(int32_t i=0; i<=length; i++) |
120 | {
|
121 | PORTB|=(1<<PB0); |
122 | |
123 | x=x1+(i*x1x2)/length; |
124 | y=y1+(i*y1y2)/length; |
125 | z=z1+(i*z1z2)/length; |
126 | a=a1+(i*a1a2)/length; |
127 | |
128 | PORTB&=~(1<<PB0); |
129 | |
130 | zColumn1=sqrtXX_floorC(rColumn1sqr-((x-xColumn1)*(x-xColumn1))-((y-yColumn1)*(y-yColumn1)))+z; |
131 | zColumn2=sqrtXX_floorC(rColumn2sqr-((x-xColumn2)*(x-xColumn2))-((y-yColumn2)*(y-yColumn2)))+z; |
132 | zColumn3=sqrtXX_floorC(rColumn3sqr-((x-xColumn3)*(x-xColumn3))-((y-yColumn3)*(y-yColumn3)))+z; |
133 | |
134 | PORTB^=(1<<PB1); |
135 | }
|
136 | }
|
137 | |
138 | int main(void) |
139 | {
|
140 | DDRB |= (1<<PB0); |
141 | DDRB |= (1<<PB1); |
142 | |
143 | do //Hauptprogramm - Endlose Schleife |
144 | {
|
145 | linearMoveTo(0, 0, 0, 0, 27501, 27500, 3000, 500); |
146 | }
|
147 | while(1); |
148 | }
|
Dominik V. schrieb: > Ok, in dem Falle wage ich einfach mal einen Test mit dem PIC32, wie ich > im Datenblatt gesehen unterstützt der ja Hardware-seitig 32 bit Mul/Div, > die Wurzel konnte ich ja auf Shift/Add und Sub reduzieren. > Soweit ich das gesehen habe ist der freie C-Compiler nicht so besonders, > sprich der Quelltext muss in Assembler geschrieben werden? Der C32 bzw XC32 (PIC32MX) und der C30 bzw XC16 (PIC24,dsPIC) sind angepasste gccs, der MIPS16e bzw PIC24 Code generieren, also im Prinzip das gleiche, was sonst auch auf anderen Architekturen zu finden ist. Die kostenlose Versionen haben die höchsten Optimierungsstufen nicht, aber das sind vielleicht 10-15%, die Du verlierst. Beim XC8 (der kein gcc ist) ist der Unterschied größer. fchk
Hi, leider hab ich kein Oszi oder Vergleichbares hier. Aber ausgemessen mit dem Core-Timer und optimize level 1 auf einem PIC32MX250F128D komm ich auf folgende Werte: linearMoveTo(0, 0, 0, 0, 27501, 27500, 3000, 500); -> 0.443s bei 40MHz
1 | x=x1+(i*x1x2)/length; |
2 | y=y1+(i*y1y2)/length; |
3 | z=z1+(i*z1z2)/length; |
4 | a=a1+(i*a1a2)/length; |
braucht 72 Takte und der ganze restliche Abschnitt braucht 734 Takte. +-10Takte weil ja noch das Pin-Gewackel mit drin is ;) Soviel zur puren Kraft der 32bit :D
Habs gerade mal laufen lassen auf einem STM32F4 @168 MHz O0: 4,7 Mikrosekunden pro Durchlauf (PB0), Division braucht 940 Nanosekunden (PB0) O2: 4,6 Mikrosekunden pro Durchlauf (PB0), Division braucht 420 Nanosekunden (PB0) 32 Bit sind nicht alles wie man sieht ;) Bei der Berechnung der Gesamtdurchlaufzeit habe ich jetzt schon durch zwei geteilt, da ja getogglet wird. LG Jan
Hallo Frank, Hallo Michael, Hallo Jan, danke für die Infos, resp. das Testen. Ich glaube egal wie ich es auch drehe und wende, ein oder mehrere µC´s werden nicht die Rechenleistung aufbringen, die mir vorschwebt, erst Recht nicht mehr wenn ich zusätzlich Polynome als Verfahrweg berechnen lasse. Ich werde mich daher mehr auf die Speicher-Lösung (sd-karte / sdram etc) und eine schnelle Schnittstelle (LAN) konzentrieren. Die Berechnungen überlasse ich dann doch einer modernen 64bit CPU im GHz-Bereich mit 4 Kernen. Die Stand-Alone Lösung greift dann erst ab der erfolgten Einrichtung und Schritterzeugung wenn das Programm läuft. So habe ich Rechenleistung und Echtzeit da wo ich Sie dringend brauche (Best of both Worlds). Danke auch an die anderen User für die zahlreichen und informativen Beiträge. Gruß Dominik
Hi Dominik, ehm, bist du dir sicher, dass du meine Zeitangaben korrekt gelesen hast? Du schaffst 200.000 Durchläufe pro Sekunde. Das reicht nicht? In jedem Falle aber: Viel Erfolg :) LG Jan
Jan Berg schrieb: > Hi Dominik, > > ehm, bist du dir sicher, dass du meine Zeitangaben korrekt gelesen hast? > Du schaffst 200.000 Durchläufe pro Sekunde. Das reicht nicht? > In jedem Falle aber: Viel Erfolg :) > > LG Jan Hallo Jan, in der Tat, da habe ich wohl nicht richtig mitgerechnet ;-) Hatte aber zwischenzeitlich etwas Erfolg bei der Erprobung des Wiz820io- Moduls, daher ist der neue Ansatz jetzt wie folgt: der ATmega kommuniziert via Lan, RS232 x2 und speichert auf microSD das Programm abhängig vom Nullpunkt. Gerechnet wird auf allen verbundenen (max 8) Clients (Last-Verteilung). Im Moment schreibe ich die Steuerung und Schrittberechnung für Android, damit kann ich als Steuereinheit für die Maschinensteuerung ein normales Smartphone/Billig-Tablet nehmen, habe zwar eigentlich ein win 8.1 tablet im visier, aber selbst das billige Netto-Tablet von voriger Woche schafft 45000 Sinus Berechnungen inkl. Achs-Interpolation pro Sekunde im 64bit floating-point-betrieb :-) Dual-Core Arm9 glaube ich. Da die Teile nix mehr kosten und bereits mit W-Lan, etc. kommen... Unabhängig davon ist nur die GUI für Win/Linux/etc. anzupassen. Weiterer Gimmick ist natürlich, dass die Maschine auch via "Handy" überwacht werden kann. Gruß Dominik
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.