Hallo, nachdem ich die ersten, kleinen Projekte wie SD-Interface, VGA-Framebuffer und anderes dieser Art abgeschlossen habe, möchte ich eine kleine CPU entwerfen. In meiner Architektur gibt es einen Daten- und einen Adressbus, mit dem CPU und RAM verbunden sind. Es soll kein Pipelining geben. Nun frage ich mich, wie ich es hinbekommen kann, dass die Fetch-Phase in einem einzelnen Takt abläuft. Durch Sprunganweisungen kann der Programmzähler einen beliebigen Wert haben, sodass ich an folgende Implementierung für Fetch dachte: * Inhalt des Programmzählers auf den Adressbus legen und Leseanforderung setzen * einen Takt warten - in diesem kann ich leider nichts sinnvolles tun, da keine Informationen über die folgende Anweisung bekannt sind * jetzt übernimmt das RAM die Leseanforerung und lädt den Inhalt * einen weiteren Takt warten * erst jetzt liegt die Anweisung auf dem Datenbus Bei meinen bisherigen Projekten habe ich Daten nur sequentiell gelesen, sodass ich einfach Takt vor der Auswertung mit dem Lesen anfangen konnte und dadurch alles synchron war. Hier sehe ich jetzt aber das Problem, dass der Programmzähler sich beliebig ändern kann und ich dann einen Takt länger warten muss. Ich glaube, dass andere Prozessoren das anders lösen. Im Beispielprozessor des Buches "VHDL-Synthese" wird beispielsweise sowohl mit steigenden als auch mit fallenden Flanken gearbeitet. Ist das die übliche Lösung oder gibt es etwas "besseres"? Oder habe ich allgemein einen Denkfehler? Viele Grüße Peter
@Peter (Gast) >mich, wie ich es hinbekommen kann, dass die Fetch-Phase in einem >einzelnen Takt abläuft. Langsam genug takten. >Bei meinen bisherigen Projekten habe ich Daten nur sequentiell gelesen, >sodass ich einfach Takt vor der Auswertung mit dem Lesen anfangen konnte >und dadurch alles synchron war. Hier sehe ich jetzt aber das Problem, >dass der Programmzähler sich beliebig ändern kann und ich dann einen >Takt länger warten muss. Ist halt so. Ein Programm besteht ja nicht nur aus Sprungbefehlen. >Ich glaube, dass andere Prozessoren das anders lösen. So wie der 8051 mit seinen 12 Takten/Maschinenzyklus? SCNR > Im >Beispielprozessor des Buches "VHDL-Synthese" wird beispielsweise sowohl >mit steigenden als auch mit fallenden Flanken gearbeitet. Ist das die >übliche Lösung Nein. >oder gibt es etwas "besseres"? Pipelining.
Peter schrieb: > In meiner Architektur gibt es einen Daten- und einen Adressbus, mit dem > CPU und RAM verbunden sind. Es soll kein Pipelining geben. Nun frage ich > mich, wie ich es hinbekommen kann, dass die Fetch-Phase in einem > einzelnen Takt abläuft. Durch Sprunganweisungen kann der Programmzähler > einen beliebigen Wert haben, sodass ich an folgende Implementierung für > Fetch dachte: Ich hab mal vor Jahren eine Eintakt-maschine geschrieben, siehe dort: PiBla MfG,
Moin, Peter schrieb: > Ich glaube, dass andere Prozessoren das anders lösen. Im > Beispielprozessor des Buches "VHDL-Synthese" wird beispielsweise sowohl > mit steigenden als auch mit fallenden Flanken gearbeitet. Ist das die > übliche Lösung oder gibt es etwas "besseres"? Oder habe ich allgemein > einen Denkfehler? Das "Nein" von Herrn Brunner unterschreibe ich prinzipiell, aber man kann noch was dazu sagen: Man kann es schon so machen, aber man schiesst sich timingtechnisch u.U. ins Knie, sobald man etwas höhere Taktfrequenzen fährt. In so einigen Büchern sind merkwürdige Designkonstrukte beschrieben, die auf einem FPGA zumindest nicht immer optimal laufen. Das ganze wird mühsam zu debuggen, und bringt gegenüber Pipelining eher Unglück. Andere (non-pipelined) Prozessoren warten einfach. Guck dir sonst mal die ZPU 'small' architektur, z.B. Zealot an, die braucht für einen Verarbeitungsschritt min. 4 Zyklen. Allerdings gibt es auch pipelined Varianten (ZPUng, ZPU extreme). Beispiele einer relativ optimal gepipeline'ten Architektur sind MIPS und ähnliche Designs. Grüsse, - Strubi
Wenn du nicht den Ausgang des Counters sondern den internen Wert der Inkrement-logik an den Adressbus legt sparst du dir den Warte-Takt. Alle Beispile skizzenhaft, ohne berücksichtigung typen Beispiel 1 simples Standard Adress increment:
1 | signal count_q := (others => '0'); |
2 | |
3 | process(clk) begin |
4 | if rising_edge(clk) then |
5 | if count_q = "1111" then |
6 | count_q <= (others => '0'); |
7 | else
|
8 | count_q <= count_q + 1; |
9 | end if; |
10 | end if; |
11 | end process; |
12 | |
13 | prog_mem: BRAM port map ( |
14 | addr => count_q, |
15 | clk => clk, |
16 | --..
|
17 | );
|
Beispiel 2: Wie (1) nur aufgetrennt in Kombinatorik und Speicher
1 | signal count_q := (others => '0'); |
2 | signal next_count; |
3 | |
4 | process(clk) begin |
5 | if rising_edge(clk) then |
6 | count_q <= next_count; |
7 | end if; |
8 | end process; |
9 | |
10 | next_count <= (others => '0') when count_q = "1111" else |
11 | count_q + 1; |
12 | |
13 | prog_mem: BRAM port map ( |
14 | addr => count_q, |
15 | clk => clk, |
16 | --..
|
17 | );
|
Beispiel 3: Jetzt wird wie oben genannt der "interne" Zählerwert als adresse verwendet. Damit die addresse immer noch bei 0 beginnt muss der initwert eins vorgezogen werden
1 | signal count_q := (others => '1'); --init eins vor |
2 | signal next_count; |
3 | |
4 | process(clk) begin |
5 | if rising_edge(clk) then |
6 | count_q <= next_count; |
7 | end if; |
8 | end process; |
9 | |
10 | next_count <= (others => '0') when count_q = "1111" else |
11 | count_q + 1; |
12 | |
13 | prog_mem: BRAM port map ( |
14 | addr => next_count, --Da ist der Trick |
15 | clk => clk, |
16 | --..
|
17 | );
|
Beispiel 4: Jetzt wird das increment um das laden bei Sprungbefehlen erweitert:
1 | signal count_q := (others => '1'); |
2 | signal next_count; |
3 | signal cmd_word; |
4 | |
5 | process(clk) begin |
6 | if rising_edge(clk) then |
7 | count_q <= next_count; |
8 | end if; |
9 | end process; |
10 | |
11 | next_count <= cmd_word(3 downto 0) when cmd_word(7 downto 4) = C_JMP else |
12 | (others => '0') when count_q = "1111" else |
13 | count_q + 1; |
14 | |
15 | prog_mem: BRAM port map ( |
16 | addr => next_count, |
17 | dat_o => cmd_word, --obere 4 bits Befehl, unter argument (bspw Sprung_addr) |
18 | clk => clk, |
19 | --..
|
20 | );
|
Für den oben erwähnten Pibla kommt als Load_Values für den Programm counter nach hinzu: IRQ-ServiceRoutinestartadresse und returnstack für Subroutinen. Ist dort etwas audführlicher beschrieben: https://www.mikrocontroller.net/articles/PiBla#Programm_counter_PC MfG,
Danke für eure Tipps und Beispiele! Der PiBla benutzt distributed RAM, da tritt der Verzögerungstakt, der mich störte, ohnehin nicht auf. Dass der 8051 bis zu 12 Takte benötigt, beruhigt mich. Dann mach ich es auch erstmal so. Es wird ein CISC-Prozessor in Von-Neumann-Architektur, also ähnlich x86. Durch die variablen Befehlsbreiten und die Belegung des Adressbusses auch während der Ausführungsphase wäre Pipelining sehr schwierig zu implementieren, deshalb lasse ich das weg.
@ Peter (Gast)
>Danke für eure Tipps und Beispiele! Der PiBla benutzt distributed RAM,
Wirklich? Das wäre ja nicht sonderlich intelligent. Der ist doch viel zu
klein. Und wenn man mehrere zusammenbaut wird er noch langsamer.
Falk B. schrieb: > @ Peter (Gast) > >>Danke für eure Tipps und Beispiele! Der PiBla benutzt distributed RAM, > > Wirklich? Das wäre ja nicht sonderlich intelligent. Der ist doch viel zu > klein. Und wenn man mehrere zusammenbaut wird er noch langsamer. Ich hab nochmal nachgeschaut - im Core wird distributed RAM verwendet, aber das scheint eher ein Feature zu sein, um vom Programm auf schnell verfügbares RAM zuzugreifen. Der Programmcode ist anscheinend doch BlockRAM (als Xilinx-Komponente statt VHDL, deshalb beim ersten Anschauen übersehen). Dann schau ich's mir doch nochmal in Ruhe an.
Angehängte Dateien:
-

Single_clock_PCw.jpg
28 KB
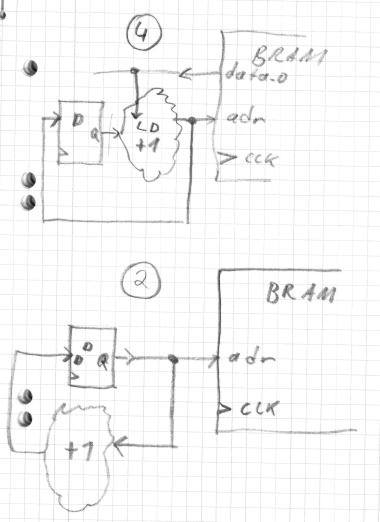
Der Programmspeicher ist Block-Ram, wie man aus dem xco-file lesen kann: https://www.mikrocontroller.net/svnbrowser/pibla/00_hw/src/core_mem.xco?view=markup Distributed RAM wird für das Registerfile, scratchpad ram und return stack verwendet.Ich lad bei Gelgenheit den synthesereport hoch. Der BRAM funktioniert wie oben beschreiben, erst mit Takt mit der datenausgang entsprechend dem adress-eingang aktualisiert. Peter schrieb: > * Inhalt des Programmzählers auf den Adressbus legen und Leseanforderung > setzen Das ist der Unterschied zu hier vorgeschlagenen Lösung, der adressbus wird nicht vom programm counter ausgangsbuffer getrieben sondern von der +1 Kombinatorik des counters, also mit der addresse des nächsten zu holenden Befehls. Ich hab mal Beispiel 2 und 4 als Logic-wolke skiziert, siehe Anhang. MfG,
Ahh, jetzt ist der Groschen gefallen.. Bei einem Sprungbefehl wird im gleichen Takt, der den Opcode decodiert, bereits der Teil mit dem neuen Programmzähler auf den Adressbus gelegt. Danke :-)
Peter schrieb: > Ahh, jetzt ist der Groschen gefallen.. Bei einem Sprungbefehl wird im > gleichen Takt, der den Opcode decodiert, bereits der Teil mit dem neuen > Programmzähler auf den Adressbus gelegt. Danke :-) Gern geschehen :-) ! Anbei der gekürzte Synthesereport. Der Programmspeicher -core_mem- ist nicht als BRAM aufgeführt da er nach der Synthese als Netzliste aus dem Core-generator zugeschlagen wird. Das macht IMHO das design portierbarer bspw nach Altera. MfG,
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.