Hallo zusammen, ich habe mehrere A/V-Geräte im Wohnzimmer. Ich möchte nichts "umschalten", die Stereo-Audio-Signale sollen nur gemischt werden. Analog mache ich das seit 15 Jahren genau so, mit Sat-Emfänger, DVD-Player, PC usw. an einem "Behringer MINIMON MON800". Das Prinzip gefällt der gesamten Familie, weil es einfach zu benutzen ist. Es muss nichts "umgeschaltet" werden. Nun möchte ich die S/P-DIF-Ausgänge der o.g. Geräte statt der Cynch-Ausgänge verwenden, da einige Geräte den Stellplatz geändert haben und ich die Audio-Signale über 10..15m gern digital übertragen möchte. Ich habe ewig gesucht. Es gibt nur "Mischpulte" für ein paar tausend Euro. Ich brauche kein "Pult", sondern nur einen Mixer, dessen Signal einmal am Verstärker nach Analog gewandelt wird. Gern irgendwo hinten im Regal, wo man den Mixer nicht sieht. Ich brauche nur einmal die Lautstärke am Verstärker einstellen. Sowas gibt es nicht für wenige 100€ zu kaufen, richtig? VG Torsten
:
Bearbeitet durch User
@Torsten C. (torsten_c) Benutzerseite >Ich brauche kein "Pult", sondern nur einen Mixer, dessen Signal einmal >am Verstärker nach Analog gewandelt wird. Gern irgendwo hinten im Regal, >wo man den Mixer nicht sieht. Das sollte machbar sein. N Kanäle mit TOSLIING Empfäanger und S/P DIF Dekoder/DAC. Die kann man dann einfach analog addieren, ist deutlich einfacher als digital. >Sowas gibt es nicht für wenige 100€ zu kaufen, richtig? Keine Ahung, ich denke aber schon, daß es da was gibt. Schon mal gegoogelt? https://www.google.de/search?q=s/Pdif+mixer&ie=utf-8&oe=utf-8&gws_rd=cr&ei=fgmQVvLFIMO2PN3ktuAK
Torsten C. schrieb: > Sowas gibt es nicht für wenige 100€ zu kaufen, richtig? Korrekt. S/PDIF ist ein digitales Protokoll und am besten mit digitalem Signalprozessor zu mischen und anderweitig zu verarbeiten. Dabei wird der 'Zahlenwert' eines Audiowortes skaliert, dann mit dem eines anderen addiert, skaliert und wieder ausgegeben. Saowas wird im Heimbereich so gut wie nie benutzt, nur die Audioprofis brauchen das ab und zu. Dann allerdings wird meistens nicht S/PDIF benutzt, sondern AES/EBU oder manchmal sogar noch ADAT. Soweit ich das übersehe, wirst du dir so etwas vermutlich selber herstellen müssen. Einfacher ist da der Weg über kleine S/PDIF auf Analog Wandler, die führst du aufs Mischpult. Z.B. sowas hier: http://www.pollin.de/shop/dt/MjUwOTMzOTk-/HiFi_Car_HiFi_Video_TV/HiFi/Zubehoer/Digital_Analog_Audio_Konverter_DYNAVOX.html Klingt m.E. recht brauchbar. Durchgemessen habe ich ihn nicht.
Falk B. schrieb: > Die kann man dann einfach analog addieren, ist deutlich > einfacher als digital. Hmmm, genau das wollte ich eigentlich nicht. "digital" ist doch nur "ein bisschen" VHDL oder Verilog (oder DSP-SW). Matthias S. schrieb: > Klingt m.E. recht brauchbar. Das finde ich auch. Einer davon hängt bereits am "MINIMON"^^. Also: Ihr meint, man sollte weiterhin anlalog mischen? :-(
:
Bearbeitet durch User
Torsten C. schrieb: > Also: Ihr meint, man sollte weiterhin anlalog mischen? :-( Du kannst natürlich auch anfangen, nach einem DSP zu suchen, der genügend I2S Eingänge hat, dazu Eingangsbausteine, die S/PDIF auf I2S wandeln. Nach ein bisschen DSP oder VHDL programmieren das Ganze dann zusammenlöten und hoffen, das es klappt. Schafft man doch locker am Wochenende zwischen Kaffee und Kuchen - nee, mal im Ernst, du könntest ja die o.a. Wandler ins Mischpult einbauen, was du schon hast und damit am schnellsten ans Ziel kommen. Also ja, das Mischpult bleibt analog und du rüstest eben S/PDIF Eingänge nach. Dann hast du auch noch die Option, deine analogen Quellen auch darüber zu ziehen. Die würden bei einem volldigitalen Mischer noch zusätzliche A/D Wandler benötigen.
Das Thema hatten wir doch vor ein paar Tagen schon: Man kann digitale
Quellen nicht einfach mischen, sondern muss sie synchron addieren. Dies
erfordert eine gemeinsame Zeitbasis. Da aber nur immer eine Quelle als
Taktgeber herangezogen werden kann und die anderen meistens machen, was
sie wollen, müssen die synchronisiert werden, also entweder von Außen im
Takt gesteuert werden, oder man muss das Signa resampeln. Und DAS ist
das Aufwändige und Teure.
> Re: S/P-DIF Mixer - lohnt sich selbst bauen?
Nein, nicht wirklich. Das Billigste, was ich mir vorstellen kann, und
was noch einigermaßen gut geht, ist ein fertig aufgebauter Wandler mit
Cirrus-Chip, der das S/PDIF decodiert und ein Analogsignal abgibt. Das
Ganze auf eine Summe geben und wieder wandeln.
Ansonsten: Harte Kanalumschaltung und Nutzung von nur einem
Geräteeingang gleichzeitig. Dazu gibt es digitale Patchbays.
Torsten C. schrieb: > Sowas gibt es nicht für wenige 100€ zu kaufen, richtig? Genau. Dein Probem ist: Du verwendest Consumer-Geräte, kein Profi-Equipment. Consumer-Geräte haben einen Quarzoszillator (oder zwei, für 32/48 und 44.1 kHz) eingebaut, und daraus werden Bittakt und Frametakt für die AD-Wandler und SPDIF-Transceiver gebildet. Soweit, so gut. Du hast MEHRERE Consumer-Geräte. Jedes hat seinen eigenen Taktgenerator, der ein klein wenig von dem des nächsten Gerätes abweicht. Alle Geräte sind also asynchron zueinander, und genau das ist das Problem. Du kannst nicht einfach digital addieren, Du musst erstmal die digitalen Signale aufeinander synchronisieren. Und das ist aufwändig, und teuer. Der Profi mit seinem AES/EBU über XLR-Kabel zieht einfach noch weitere Kabel. Er hat EIN ZENTRALES Gerät, was Bittakt und Worttakt erzeugt, und der wird dann an alle anderen Geräte verteilt. Damit ist alles absolut synchron, und die komplett digitale, verlustlose Weiterverarbeitung ist somit kein Problem mehr. Diese Möglichkeit hast Du nicht. Punkt. Du wirst analog mischen und damit Verluste in Kauf nehmen müssen. Behalte Deinen Mischer und kaufe Dir einen Stapel TOSLINK-zu-Stereo DA-Wandler und hänge die an Deinen Mischer. Das wird das billigste sein. Siehe ebay #381493664097 zum Beispiel. fchk
Frank K. schrieb: > Du musst erstmal die digitalen Signale > aufeinander synchronisieren. Und das ist aufwändig, und teuer. Nicht unbedingt, auch die hochwertigen nehmen da einfach den letzten Abtastwert her der übertragen wurde. So lange die Abtastfrequenzen nahe beieinander sind ist das sogar die hochwertigste Methode.
Frank K. schrieb: > Diese Möglichkeit hast Du nicht. Punkt. Danke für die nett gemeinten Standpunkte. Aber man hat "Momentanwerte" und kann sie z.B. mit 8-Fach Oversampling mitteln und addieren. Punkt. Matthias S. schrieb: > … anfangen, nach einem DSP zu suchen, der genügend I2S Eingänge hat Ich dachte eher an ein FPGA. Der hat genug Eingänge und skaliert besser. Wird "etwas VHDL" denn schlechter klingen als "analog"?
:
Bearbeitet durch User
Selbst wenn man das Syncproblem gelöst hat, bleibt immer noch die Skalierung (Multiplikation) und die Addition der Signale. Und den Master möchte man ja auch noch mal regeln (lies: multiplizieren). Das ist nicht ganz so einfach und benötigt m.E. einen anständigen DSP. Wenn dann noch Klangregelung dazukommt, ist das ein recht aufwändiges Projekt. Torsten C. schrieb: > Der hat genug Eingänge und skaliert besser. Woraus schliesst du das? Ich habe hier mit einem der kleinen TI DSP zu tun gehabt (TAS3208) und der hat immerhin 56 Bit Datenpfad.
:
Bearbeitet durch User
Matthias S. schrieb: > bleibt immer noch die Skalierung (Multiplikation) Darum meinte ich "kein Mischpult". Das "Behringer MINIMON MON800" kann auch nicht Kanal-individuell multipizieren. Vielleicht will man irgendwann auch Multiplikation, das mag sein. Der S/P-DIF-Ausgang vom TV ist nicht mit der Lautstärke-Regelung der Fernbedienung verbunden. Der analoge Cynch-Ausgang ist damit verbunden. > Ich brauche nur einmal die Lautstärke am Verstärker einstellen. Vllt. reichen 6dB-Schritte (Shift-Right). Matthias S. schrieb: > Woraus schliesst du das? Ich denke: Der VHDL-Source bleibt fast identisch, selbst wenn man z.B. 12 statt 4 Eingänge will. Es wird nur mehr Logik gebraucht, also zur Not der nächst größere FPGA. Weil diese Logik aber im FPGA immer parallel läuft, wird es bei einer Skalierung nie zeitkritisch. Aber in 20 Jahren ist viel passiert. Ich würde mir beides mal anschauen. Matthias S. schrieb: > Ich habe hier mit einem der kleinen TI DSP zu tun gehabt (TAS3208) und > der hat immerhin 56 Bit Datenpfad. Ich habe vor ca. 20 Jahren meine Diplomarbeit mit sowas ähnlichem auf einem Motorola-DSP gemacht. Eine Kanal-spezifische Klangregelung hat meine Familie ich in den letzten 15 Jahren^^ nie vermisst.
:
Bearbeitet durch User
Torsten C. schrieb: > Frank K. schrieb: >> Diese Möglichkeit hast Du nicht. Punkt. > > Danke für die nett gemeinten Standpunkte. Aber man hat "Momentanwerte" > und kann sie z.B. mit 8-Fach Oversampling mitteln und addieren. Punkt. Sicher. Aber wenn die Taktfrequenzen der digitalen Signale nicht identisch sind, dann wirst Du irgendwann irgendwo ein Sample verdoppeln oder verwerfen müssen. Und das hörst Du gnadenlos, und es wird Dich gnadenlos nerven. Nehmen wir an, Du hast eine Quelle mit 48kHz Sampletakt, und eine Quelle mit 48kHz+0.001%. Dann hast Du alle zwei Sekunden ein Sample, was weggeworfen werden muss, also alle zwei Sekunden ein leichter Knacks. Ätzend. fchk PS: Natürlich kannst Du Sample Rate Conversion machen. Aber einfach ist das nicht.
:
Bearbeitet durch User
Hierfür gibt es asynchrone Samplerateconverter wie z.B. AD1896, ist vermutlich die einfachste Möglichkeit, alle digitalen Quellen auf einen gemeinsamen Takt artefaktfrei zu resamplen.
Frank K. schrieb: > Dann hast Du alle zwei Sekunden ein Sample, was > weggeworfen werden muss "8-Fach Oversampling" heißt, dass im FPGA die Sample-Schritte linear in 8 Teilschritte zerlegt werden. Mit … > wird "etwas VHDL" denn schlechter klingen als "analog"? … war die Frage gemeint: Hat jemand Erfahrungen? Reicht dem "Otto-Normalferbraucher" 8-Fach-Oversampling, oder wieviel muss es sein? Mr. Claudius schrieb: > asynchrone Samplerateconverter Schaue ich mir mal an, danke.
:
Bearbeitet durch User
Torsten C. schrieb: > Vielleicht will man irgendwann auch Multiplikation, das mag sein. Du wirst auf jeden Fall einmal nach rechts schieben müssen, denn du kannst ja 2 16-bit Signale nicht einfach addieren und darauf hoffen, das der Wertebereich innerhalb der 16bit bleibt. Wenn du drei Quellen addierst, wird das nochmal etwas komplizierter usw.
Matthias S. schrieb: > Du wirst auf jeden Fall einmal nach rechts schieben müssen Gut. Das verbraucht in VHDL ja keine Ressourcen. ;-) Frank K. schrieb: > Dann hast Du alle zwei Sekunden ein Sample, was weggeworfen werden muss PS: Weggeworfen wird bei "8-Fach Oversampling": Alle ¼ Sekunde ⅛ Sample! Matthias S. schrieb: > Wenn du drei Quellen addierst … 3db sind gar nix. Die werden analog über den Lautstärkeregler eingestellt. Es wird ja nicht ständig geschaltet. Das ist ja gerade der Vorteil, den die Familie^^ mag. Nur um Missverständnisse zu vermeiden: Es geht um einen Ersatz für einen "MINIMON MON800"^^. Bisher glaubt hier niemand, dass man ein AES/EBU-Mischpult neu entwickeln sollte.
:
Bearbeitet durch User
Also so einfach und so kompliziert ist es irgendwie nicht... Das Problem sind nicht die Quarz-Oszis in Profi-Equipment, sondern dass im Profi-System EINE Zeitbasis das ganze Studio taktet. Dazu nutzt man nicht selten sogar Rubidium Normale oder GPS getrimmte OCXOs. Zu Hause hat der DVD-Player aber schnell mal ein Signal mit 96kHz Samplerate, der CD-Player liefert 44.1kHz S/R und das Radio hat garkeinen digitalen Ausgang, während das Internetradio 32kHz auf dem einen Stream und der Mediaserver 192kHz S/R liefert... Wenn man das alles zusammen mischen will, hat man einen enormen Aufwand, gerade wenn man nicht mit Verlusten leben will. Dazu kommt, dass man bei Audio mit Bild auch noch recht wenig Zeit hat, sonst werden Bild und Ton asynchron. Man könnte alles auf einen DAC schicken, der die größte vorhandene S/R unterstützt und alle geringeren Quellen up-sampeln... Ich habe keine aktuelle Übersicht, aber ich denke es sollte einige DSPs geben, die zumindest mehrere IIS Eingänge haben. Mit einem S/P-DIF Decoder Chip ist man schnell bei IIS. Sicherlich gibt es aber auch VHDL IPs für sowas, da könnte man dann eine Vorselektion für einen DSP mit weniger Eingängen realisieren. Es stellt sich aber die Frage, ob man nicht einen einfachen Controller nutzen kann, um das ganze preiswert und simpel auf die eigenen Bedürfnisse anzupassen... Man möchte in der Regel ja nicht alle Quellen gleichzeitig hören, sondern eher die, die man zuletzt eingeschaltet hat. Damit müsste man nur erkennen, welches Gerät sich zuletzt aufgeschaltet hat und auf dieses umschalten. Damit kann man einen einfachen STM32F1 oder L4 einsetzen, die IIS Ein- und Ausgänge haben. Die S/P-DIF Decoder haben einen Ausgang, der "Lock" anzeigt, also wenn der Decoder auf das Signal synchronisiert hat. Die Software kann dann das letzte Sample fertig raus senden, eventuell noch eine Stille oder ein Fade-Over einfügen... Einige Decoder brauchen leider manchmal eine minimale Lücke um zu erkennen, dass die Samplrate sich verändert hat, oder um ein Ploppen zu verhindern. Programmiert man sowas selber, kann man ja eigene Prioritäten integrieren, also "Immer das letzte Gerät" oder "Immer das letzte, nur TV gewinnt immer" oder man programmiert noch eine Türklingel mit rein, die zwischendrin alles überschreiben kann. Ist das zuerst vorhandene Gerät noch an, wenn das zuletzt aktive Gerät ausgeschaltet wird, dann schaltet man zurück auf das davor. Es gibt auch Geräte, die im Standby leider sehr aktiv bleiben, da muss man dann entscheiden, dass nach x Sekunden empfangener Stille das Gerät als "Standby" anzusehen ist... Schwieriger wird es dann aber zu erkennen, wann wider Signal da ist... Früher hatten Decoder einen Mute Ausgang, der bei Stille signalisierte, aber diese Chips sind selten geworden... Aber Du sprachst von VHDL, spätestens am IIS Signal kann man Stille leicht erkennen :)
@uprinz: Danke! Sehr ausführlich! :-) Ulrich P. schrieb: > während das Internetradio 32kHz auf dem > einen Stream und der Mediaserver 192kHz S/R liefert... Ich habe gedacht, das Problem für Otto^^ durch den "Oversampling-Faktor" in den Griff zu bekommen. Z.B. 44,1KHz mit "8-Fach" = 352,8KHz. Alles Andere sind dann lineare gemittelte Werte der Source-Sample-Rate mit 2-, 4-, oder 8-Fach-Oversampling. Gibt es gegenteilige Erfahrungen? Ulrich P. schrieb: > gerade wenn man nicht mit Verlusten leben will Verluste sind immer! Ich habe mir den AD1896 noch nicht angeschaut, aber bei 352,8KHz und linearer Interpolation hört meine Familie bestimmt keinen Nachteil gegenüber "analog", oder? Ulrich P. schrieb: > sonst werden Bild und Ton asynchron. Aktuell (Analog-Welt) hinken bei uns alle Bilder hinterher. Ein verstellbarer Analog-FiFo wäre ein angenehmes Abfallprodukt. Ulrich P. schrieb: > es sollte einige DSPs geben, die zumindest mehrere IIS Eingänge haben Ich bin auf dem FPGA-Trip. Welchen Vorteil soll ein DSP bringen? Ulrich P. schrieb: > Man möchte in der Regel ja nicht alle Quellen gleichzeitig hören Hmmm. Doch. Nein. Wie soll ich das sagen? Die Familie schaltet Geräte "ein" und "aus". Aber sie will keine Eingänge "umschalten". Ulrich P. schrieb: > oder man programmiert noch eine Türklingel mit rein Gute Idee. :-) Ulrich P. schrieb: > Es gibt auch Geräte, die im Standby leider sehr aktiv bleiben, da muss > man dann entscheiden, dass nach x Sekunden empfangener Stille das Gerät > als "Standby" anzusehen ist Auch ein Gedanke. Aber bisher konnte ich in der Analog-Welt nach Stefan-Raab-Manier mal per "Nippelboard" auf dem PC einen Einwurf machen, ohne dass irgendwas synchronisiert oder umgeschaltet werden musste.
:
Bearbeitet durch User
@Torsten C. (torsten_c) Benutzerseite >> Die kann man dann einfach analog addieren, ist deutlich >> einfacher als digital. >Hmmm, genau das wollte ich eigentlich nicht. Jaja, heute ist alles volldigital, aber ich glaub REAL bringt das hier wenig, wenn du so oder so auf einen Analogeingang gehst. >"digital" ist doch nur "ein bisschen" VHDL oder Verilog (oder DSP-SW). "bisschen" >Also: Ihr meint, man sollte weiterhin anlalog mischen? :-( Du MUSST das nicht! Es ist nur der einfachere Weg. Ob du einen Unterschied zwischen volldigitalem Mischer und der halbanalogen Version hörst, ist zu bezweifeln, wenn es halbwegs gescheit aufgebaut ist.
@ Christian Berger (casandro) >> Du musst erstmal die digitalen Signale >> aufeinander synchronisieren. Und das ist aufwändig, und teuer. >Nicht unbedingt, auch die hochwertigen nehmen da einfach den letzten >Abtastwert her der übertragen wurde. So lange die Abtastfrequenzen nahe >beieinander sind ist das sogar die hochwertigste Methode. Hmm, und was ist mit Schwebungen etc.? Die Methode klingt verlockend einfach, hat aber sicher einen Haken!
Die SPDIF auf I2S Konverter wurden ja schon erwähnt. Von Analog Devives gibts da ein paar nette DSPs. Haben viele I2S In/Out und auch Samplerate Konverter. Weiterhin auch klickibunti programmierbar. -> http://www.analog.com/en/products/audio-video/audio-signal-processors/sigmadsp-audio-processors/adau1451.html
Martin W. schrieb: > Von Analog Devives gibts da ein paar nette DSPs. > Haben viele I2S In/Out und auch Samplerate Konverter. Gibt es dafür DEV-Boards für unter 30€? FPGA-Boards zu dem Preis gibt es viele. Mr. Claudius schrieb: > Hierfür gibt es asynchrone Samplerateconverter wie z.B. AD1896 Aliexpress: €1,72/piece Mouser: @20,80/piece ??!!! Da fehlt mir noch der Überblick. PS zum "Nippelboard": Eine familientaugliche "rein digitale" Folge-Version müsste es auch erlauben, per WLAN oder Bluetooth vom Smartphone etwas einzuspielen. Und schon wird es nochmal komplexer. :-( Falk B. schrieb: > aber ich glaub REAL bringt das hier > wenig, wenn du so oder so auf einen Analogeingang gehst. Ich gebe zu: Auch Aktivboxen mit S/P-DIF und digitalen Frequenzweichen sind seit über 20 Jahren eine Projektidee von einem Kommiditonen, einem Arbeitskollegen und mir. Aber so weit will ich bei der akuten Wohnzimmer-Problematik nicht gehen. > "bisschen" … > Du MUSST das nicht! Es ist nur der einfachere Weg. In den letzten 2 Stunden habe ich viele "Blockschaltbilder" im Kopf gehabt. Alle sind komplexer als bei der ersten "fixen Idee". :-( Ich befürchte, Deine Einschätzung ist leider zu realistisch. Danke. Trotzdem: "Schwebungen" sollte man durch ausreichendes Oversampling doch ausmerzen können!
:
Bearbeitet durch User
> Hmm, und was ist mit Schwebungen etc.? Die Methode klingt verlockend > einfach, hat aber sicher einen Haken! Klar, sie klingt einfach Schei$$e... Wenn ein Gerät tatsächlich sowas macht, ist es definitiv nicht hochwertig. Entweder gemeinsamer Wordclock *) oder Sampleratenkonvertierung, was anderes gibts nicht. *) SRCs sind ja einfach erhältlich. Der AD1895 kostet bei digikey 9EUR, wenn man einen SRC nicht schon als Core rumliegen hat bzw. das aus Interesse machen will, ist das wohl nicht billiger zu haben. Allerdings verschlechtert jede SRC das SNR. Und im Profibereich wird AES/EBU auch gern zur Übertragung von Steuerinformationen benutzt, da wäre eine Interpolation eher schädlich ;)
@Torsten C. (torsten_c) Benutzerseite >> Hierfür gibt es asynchrone Samplerateconverter wie z.B. AD1896 >Aliexpress: €1,72/piece >Mouser: @20,80/piece Schön, aber mit so einem IC allein ist es nicht getan. >PS zum "Nippelboard": Eine familientaugliche "rein digitale" >Folge-Version müsste es auch erlauben, per WLAN oder Bluetooth vom >Smartphone etwas einzuspielen. Und schon wird es nochmal komplexer. :-( Du kennst das Märchen vom süßen Brei? ;-) >Ich gebe zu: Auch Aktivboxen mit S/P-DIF und digitalen Frequenzweichen >sind seit über 20 Jahren eine Projektidee von einem Kommiditonen, einem >Arbeitskollegen und mir. Seit 20 Jahren? Ohje? Wird das noch was vor der Rente oder abt ihr euch vollends auf's Philosphische verlegt? >In den letzten 2 Stunden habe ich viele "Blockschaltbilder" im Kopf >gehabt. Alle sind komplexer als bei der ersten "fixen Idee". :-( >Ich befürchte, Deine Einschätzung ist leider zu realistisch. Das Problem kenn ich ;-) >Trotzdem: "Schwebungen" sollte man durch ausreichendes Oversampling doch >ausmerzen können! Keine Ahnung, in der Thematik steck ich nicht drin. Ich sag nur Vorsicht ;-)
@ Georg A. (georga) >Klar, sie klingt einfach Schei$$e... Wenn ein Gerät tatsächlich sowas >macht, ist es definitiv nicht hochwertig. Entweder gemeinsamer Wordclock >*) oder Sampleratenkonvertierung, was anderes gibts nicht. Wie einfach ist doch die Analogwelt, ein paar Potis, gute OPVs und fertig ;-)
@Torsten C. (torsten_c) Benutzerseite >PS zum "Nippelboard": Eine familientaugliche "rein digitale" >Folge-Version müsste es auch erlauben, per WLAN oder Bluetooth vom >Smartphone etwas einzuspielen. Und schon wird es nochmal komplexer. :-( Solche Empfänger gibt es preiswert als Modul bzw. Brüllwürfel (im wahrsten Sinne des Wortes). Dort kann man auch einfach den Analogausgang nutzen und auf den Mischer, genauer, Addierer geben. (Mischen ist in der HF-Technik Multiplikation, nicht Addition)
Falk B. schrieb: > Du kennst das Märchen vom süßen Brei? ;-) Meine LAG hat es mir gerade erläutert. Ich verstehe. Georg A. schrieb: > Und im Profibereich wird AES/EBU auch > gern zur Übertragung von Steuerinformationen benutzt, da wäre eine > Interpolation eher schädlich ;) Wie gesagt: Hier geht es um "Consumer", nicht um "Profi". Aber bevor ich mich vollends auf's Philosphische verlege, sage ich: _________________________________________________________________ Der Thread ist allgemein offen für Ideen und Fragen zu dem Thema. _________________________________________________________________ Gern auch über die 6-Monate-Frist hinaus. Der Thread ist abonniert. Vielen dank für Euer Feedback!. :-) Ich habe zwar schon DEV-Boards mit FPGA, TosLink-In und TosLink-Out rum liegen, aber damit kann man auch was Anderes machen. Die Analogwelt ist einfach einfacher als die digitale Welt und die HF-Technik. Ich mache vernünftige PCB-Layouts und fertig! Evt. sogar "symmetrisch" über CAT5-Kabel, um die 10-20m zu überbrücken, für Geräte ohne S/P-DIF-Ausgang. Mal sehen.
:
Bearbeitet durch User
Also bei S/R von 192kHz steige ich aus, kannst ja mal vorbei kommen, wenns fertig ist, wir klemmen das dann hier mal an den R&S Audio Analyzer... Diese Samplerates nützen ja nix, wenn der Rest des Systems das nicht abbilden kann. Ebenso müssen ja DAC, Verstärker und Boxen das rüber bringen und man muss dann auch sein Wohnzimmer um die Anlage herum designen und nicht irgendwo ein paar Brüllwürfel hin stellen. Zurück zum Machbaren: IIS und S/P-DIF in VHDL sollte es fertig geben, da mache ich mir wenig Sorgen. Deinen Einwand wegen WLAN und Bluetooth verstehe ich nicht. die fertigen BT-Module liefern IIS und passen also direkt in des von mir vorgestellte "Alternativ-Modell" und auch an deine VHDLs. WiFi ist kein Audio, aber wenn Du Media-Player oder Internet-Radio meinst, dann kann man das immer auch mit IIS oder S/P-DIF finden. Bei mir sind im Wohnzimmer nur noch ein TV ein BluRay Player und ein SONOS System. CDs stehen nur noch zur Zierde da, die sind alle digitalisiert mit flac auf einem kleinen Raspi 2 mit Openmediavault.
Ulrich P. schrieb: > Also bei S/R von 192kHz steige ich aus Da ist das "Oversampling" ja schon drin, ganz ohne lineare Interpolation^^. Ulrich P. schrieb: > IIS und S/P-DIF in VHDL sollte es fertig geben Ein Link zu einem Beispiel würde diesen Thread fast vervollständigen. Ulrich P. schrieb: > die fertigen BT-Module liefern IIS und passen … Vielleicht ist das so einfach. Klingt gut. :-) Vielleicht läßt sich daraus noch was machen. Ulrich P. schrieb: > Bei mir sind im Wohnzimmer nur noch ein TV ein BluRay Player und ein > SONOS System. Und alle können sowohl "analog" als auch S/P-DIF. Daher der Gedanke für die bewährte Logik "Mixer" statt "Umschalten", halt nur "digital". Ulrich P. schrieb: > CDs stehen nur noch zur Zierde da, die sind alle digitalisiert Das ist bei uns auch so. Alles über NAS im LAN. Aber mein Sohn und meine Tochter höhren andere Musik. Das hatte ich mir anders gedacht. Mal sehen, Geschmäcker ändern sich. Ulrich P. schrieb: > Zurück zum Machbaren Dazu mein Fazit (nach Euren Anmerkungen): Es lohnt sich nicht, einen S/P-DIF Mixer selbst zu bauen.
:
Bearbeitet durch User
> Es lohnt sich nicht, einen S/P-DIF Mixer selbst zu bauen. Naja, wenn man sowas "schnell" bräuchte, würde ich es so machen: CS841x - SPDIF-Receiver CS5343 etc - ADCs AD1895/96 - SRCs Kleines FPGA/DSP - Mischer, Filter, Glue-Logic CS840x - SPDIF-Out CS4344 etc - DACs Sicher könnte man bis auf DAC/ADC alles in ein FPGA/DSP stopfen, kostet aber Entwicklungszeit ;) So muss man nur noch ein paar erprobte Module zusammenstöpseln und kann erstmal mit einem reinen Umschalter im FPGA anfangen und hat schon ein Erfolgserlebnis...
Torsten C. schrieb: > Matthias S. schrieb: >> Wenn du drei Quellen addierst … > > 3db sind gar nix. Die werden analog über den Lautstärkeregler > eingestellt. Es wird ja nicht ständig geschaltet. Das ist ja gerade der > Vorteil, den die Familie^^ mag. Du hast da was vergessen. Denn auch mit 3 Quellen kann es passieren, das du den Wertebereich der 16bit verlässt und glaube mir - übersteuernde Digitalsignale sind furchtbar. Zumal du beim FPGA vermutlich kein 'graceful overflow' wie in den meisten DSP hast, wenn dir da das Vorzeichenbit kippt, knallts in den Lautsprechern. Die Audio DSP hingegen bleiben dann in der Sättigung, was zwar auch nicht schön ist, aber wenigstens Ohren und Lautsprecher schont. Torsten C. schrieb: > Dazu mein Fazit (nach Euren Anmerkungen): > Es lohnt sich nicht, einen S/P-DIF Mixer selbst zu bauen. Was heisst schon lohnen? Der Aufwand ist, wie du hier gelesen hast, einfach enorm, Studiotakt hast du nicht, sondern alles Consumer Geräte, also musst du in jedem Eingang Samplerate Konverter haben. Dann musst du deine vier Eingänge (ich gehe mal vom bösen B. Gerät aus, was du schon hast) schalten, mixen und skalieren. Und dann gehts doch irgendwann wieder auf Analog und auf deine Ohren, die neben den Lautsprechern einfach das schwächste Glied in der ganzen Kette sind. Viel schneller am Ziel und mit galvanischer Trennung bist du eben mit den kleinen DAC Kisten von Dynavox, die auf Uwe Behringers Apparatschik geschaltet werden. Den kennt die Familie schon und hat ihn akzeptiert. Ein m.E. wirklich sinnvolles Bastelprojekt wäre es, den Minimon mit einer Fernbedienung auszurüsten, um nicht jedesmal zum Gerät zu müssen, wenn was umgeschaltet werden soll.
Am Anfang stand doch lediglich, dass aufgrund der räumlichen Änderung auf die digitalen Schnittstellen gewechselt werden soll, weil der Irrtum besteht, dass diese über lange Distanzen einfacher zu übertragen sind. Ich würde einfach vernünftige Bühnen Koax-Kabel einsetzen und fertig. Damit wären die größeren Distanzen kein Problem und die vorhandene und vertraute Technik kann weiter genutzt werden. Ich habe vor 10 Jahren mal mit VHDL gespielt und damals bei Design & Re-Use auch S/P-DIF Sachen gesehen. Es gab damals aber auch noch eine ganze Reihe hervorragender Audio Bausteine von Philips. NXP hat diese leider fast alle abgekündigt. Auch die hervorragenden military DACs von BurrBrown, die ich mal in einem Projekt verbaut hatte, sind nicht mehr zu haben. TI hatte sie gleich nach Übernahme auf deprecated gesetzt...
Matthias S. schrieb: > Zumal du beim FPGA vermutlich kein > 'graceful overflow' wie in den meisten DSP hast Matthias, im FPGA hast du zunächst mal nur einen Haufen Logik-Blöcke, die erst durch deinen Code eine Funktion bekommen. Es hängt ausschließlich vom Code ab, ob bei der Addition geclippt wird (eine VHDL-Zeile mehr) oder ein katastrophaler Überlauf auftritt. Ich weiß, dass du das weist... Ansonsten hast du natürlich Recht. Grüße, Uwe
Uwe B. schrieb: > Ich weiß, > dass du das weist... Ich? Ich weiss nur, das ich nichts weiss - und mit FPGA und VHDL kenne ich mich genau null aus :-) Es ist halt nur ein weiteres Bausteinchen, an das man denken sollte. Als ich noch mit dem alten 16-bit TMS320 rumspielte, war das Einhalten des Wertebereichs jedenfalls ein schönes Stückchen rumwurschteln. Ulrich P. schrieb: > Ich würde einfach vernünftige Bühnen Koax-Kabel einsetzen und fertig. > Damit wären die größeren Distanzen kein Problem und die vorhandene und > vertraute Technik kann weiter genutzt werden. Sehe ich auch so, und wenn man die kleinen Toslink-DAC einsetzt, hat man sogar wieder die galvanische Trennung, die bei Verkabelung über mehrere Räume manchmal Probleme macht.
Christian B. schrieb: > Frank K. schrieb: >> Du musst erstmal die digitalen Signale >> aufeinander synchronisieren. Und das ist aufwändig, und teuer. > > Nicht unbedingt, auch die hochwertigen nehmen da einfach den letzten > Abtastwert her der übertragen wurde. So lange die Abtastfrequenzen nahe > beieinander sind ist das sogar die hochwertigste Methode. Nenne mir bitte zwei Geräte, die al höherwertig gelten, die so arbeiten. Ernst gemeint. Ich komme aus der Branche und kenne keines, das so arbeitet. Frank K. schrieb: > Sicher. Aber wenn die Taktfrequenzen der digitalen Signale nicht > identisch sind, dann wirst Du irgendwann irgendwo ein Sample verdoppeln > oder verwerfen müssen. Und das hörst Du gnadenlos, und es wird Dich > gnadenlos nerven. Du hättest Recht, wenn es auf Sampletaktebene geschähe. Insbesondere der Jitter sorgt dafür, dass man um einen Taktübergang herum arge Probleme bekommt. Praktisch macht man das aber auf Sample-Ebene im FPGA, also mit z.. 192 MHz. Damit wird das Datum mit einem Faktor 1000 genau gesampelt und der Phasensprung ist dann immer nur 1/1000 für 192kHz. Man kann das regeln, wie Christian es beschreibt, braucht dann aber eine Logik, die auch Samples einfügen kann. Auch dies kann man machen und lösen aber auch das ist technisch schlecht. Ein Phasensprung um 1/1000 liefert an einer ungünstigen Stelle einen Fehler mit 1/1000/PI der voll in den Filter liefert und ein Signal um durchschnittlich 50dB bis 60dB verfälscht. Sicher kann man argumentieren, dass man das alleine für sich betrachtet, nicht hört. Aber man hat dann eben keine 80 oder 90dB Audiqualität. Daher gilt, was oben schon angedeutet wurde: Analog ist besser!
Matthias S. schrieb: > Du hast da was vergessen. Denn auch mit 3 Quellen kann es passieren, das > du den Wertebereich der 16bit verlässt und glaube mir Ich weiß zwar immer noch nicht, warum man 3 Quellel mixen will und was das werden soll, aber in der Tat bekommt man bei einer echten Addition einen potenziellen Overflow. Der lässt sich natürlich in VHDL genau so vermeiden, wie mit einem DSP. Kompressort, Limiter, AGC und ein Volumenregler. Das ist kein Problem. > Studiotakt hast du nicht, sondern alles Consumer Geräte Das ist auch nicht das Problem. Auch gute Consumergeräte haben keinen hörbaren Jitter mehr, will sagen, sie sind nicht arg schlechter. Das Problem ist, dass es überhaupt unsynchrone Quellen sind. Das Problem hat das Studio auch. Die wenigsten Quellen sind sinnvoll synchbar. Und die lösen das oft auch so, dass alles analog aufgezeichnet wird. Das gilt für die Neumann Digitalmikros und die digitalen Synthesizer.
Jürgen S. schrieb: >> Studiotakt hast du nicht, sondern alles Consumer Geräte > > Das ist auch nicht das Problem. Auch gute Consumergeräte haben keinen > hörbaren Jitter mehr, will sagen, sie sind nicht arg schlechter. > > Das Problem ist, dass es überhaupt unsynchrone Quellen sind. Ich habe nichts von Jitter gesagt, sondern nur, das die Quellen asynchron sind. Jitter sollte bei quarzkontrollierten Kisten so gut wie nicht vorkommen - es sei denn, die Quellen nutzen auch FPGA als Taktgeneratoren :-) Wir haben im Studio genau zwei digitale Audioquellen und das ist mein Bassverstärker und der ADC2496 von Uwe Beis. Die beiden S/PDIF Eingänge an unserem Audiosystem haben für diesen Zweck einen Sampleratekonverter, sonst würden selbst bei diesen beiden Quellen die Samplerates langsam auseinander laufen, denn der ADC2496 weiss ja nichts von meinem Bassverstärker. Und beide 10-Kanal Karten (Terratec Phase88 mit 8 analogen und 2 digitalen Kanälen) sind per Kabel untereinander synchronisiert.
Wenn ich das richtig verstehe sollen einfach mehrere Audio Quellen auf einen Verstärker gegeben werden, ohne umschalten zu müssen, aber man will eigentlich nur eine der Quellen zur selben Zeit hören. Was analog mit einem Mixer am einfachsten geht, würde ich digital mit einem DSP oder FPGA ganz anders lösen: Es wird einfach diejenige Quelle die das lauteste Signal sendet auf den Ausgang drchgeschaltet. Das löst alle Probleme mit unterschiedlichen Sampleraten oder Additionsüberläufen. Wenn man es irgenwie schafft aus dem digitalen Datenstrom zu erkennen ob da überhaupt ein Musiksignal oder einfach nur 'Stille' übertragen wird, dann braucht man vielleicht nicht einmal DSP oder FPGA, sondern nur ein Multiplexer IC. Andi
Torsten C. schrieb: > Ich möchte nichts > "umschalten", die Stereo-Audio-Signale sollen nur gemischt werden. Warum muß es unbedingt ein Mischer sein. Müssen wirklich 2 Quellen addiert hörbar sein? Ein automatischer Quellenumschalter ist deutlich einfacher (74HC151). Das Erkennen, ob auf einem Eingang Pegeländerungen erfolgen, sollte mit einem MC zu schaffen sein. Man kann dann auch Quellen einen Vorrang geben oder einfach, wer sich zuerst ändert, kriegt den DAC.
Angehängte Dateien:
-

Nippelboard.jpg
63 KB

Nochmal: > Das Prinzip gefällt der gesamten Familie: > Es muss nichts "umgeschaltet" werden. Matthias S. schrieb: > … um nicht jedesmal zum Gerät zu müssen, > wenn was umgeschaltet werden soll. Niemand muss "jedesmal zum Gerät". In der "Analogwelt" werden im Wohnzimmer immer alle Quellen durchgelassen. Zur Not muss man bei einem Gerät auf "Mute" drücken, wenn es kein "Pause" oder "Stop" gibt. Andi schrieb: > … aber man will eigentlich nur eine der Quellen zur selben Zeit hören. Bis auf ein konkretes Beispiel ist das vielleicht wirklich so: Das "Nippelboard" auf dem PC. Allerdings gibt es noch ein anderes Problem: Die S/P-DIF-Ausgänge gehen gar nicht auf "Mute"; und die Laustärke ist nicht verstellbar. Dadurch ist es in der Analogwelt nochmal einfacher: Z.B. der Kopfhörer-Ausgang vom TV lässt sich per TV-Fernbedienung verstellen. PS: Manchmal dreht die Familie die Gesamt-Laustärke hoch und macht später die Quelle leiser. Dann muss ich halt mal wieder korrigieren.
:
Bearbeitet durch User
Zum Thema Sample-Rate-Converter: Manchmal scheint mir der Unterschied zwischen, wie ich es vielleicht nennen würde, "starrem" und "flexiblem" Resampling nicht ganz klar zu sein (wobei ich euch nicht meine). "Starr", oder vielleicht auch "deterministisch" ist, wenn z.B. immer genau 441 Samples auf 480 Samples umgerechnet werden. Z. B., wenn die Daten eines Files konvertiert werden. Das geht verhältnismäßig einfach. "Flexibel" ist dass, worüber wir hier reden. Zwei Signale, generiert aus unabhängigen Taktgebern sollen vereint werden. Das können auch zwei Signale mit gleicher nomineller Abtastrate sein, aber in der Praxis hat eins z. B. 48000,034... Hz und das andere 48000,125... Hz, und das nur in einem Moment, denn es ändert sich zusätzlich ständig. Das zu synchronisieren ist gar nicht trivial, aber die SRCs von AD & Co können das. Ich habe allerdings keine Ahnung, wie (für Tipps bin ich dankbar). Mir fällt nichts besseres ein, als eine DA- mit anschließender AD-Wandlung, aber die Leistungsdaten der SRCs sind so nicht erreichbar. Zum Thema Jitter und Auslassen bzw. Verdoppeln von Samples, was ich selber auch schon auf einem FPGA gemacht und gehört habe: Zum einen kann ich mir nicht vorstellen, dass das ernsthaft in eine professionellen Umgebung zum flexiblen Synchronisieren zweier Quellen akzeptiert wird, da stimme ich Jürgen zu. Zum zweiten: Es ist natürlich in der Praxis bei normalen Quellen unhörbar. Aber mit speziellen Signalen wird es deutlich. Immerhin ist bei 10 ppm Differenz jedes 100000ste Sample betroffen, das liegt im Bereich weniger Sekunden. Bei einfacher Übernahme des letzten Samples spielt der Jitter natürlich eine Rolle, beim Überholvorgang werden immer viele Samples betroffen sein. Nicht nur die Präzision der Quelle spielt dabei eine Rolle, denn der S/PDIF-receiver regeneriert den Takt mit einem RC-Oszillator, und der dürfte sehr viel mehr zum Gesamtjitter beitragen. Aber auch das ist leicht lösbar, wenn man einen ganz kleinen Puffer für die Audiodaten einbaut. Zwei Samples reichen. Aus dem Puffer wird wie mit einem "Schleppzeiger" oder "temporalen Schmitt-Trigger" (Copyright dieser Wortschöpfung bei mir;-) ausgelesen. Auch das habe ich schon in der Praxis realisiert. Wenn man keinen anständigen SRC hat und nicht vorher in's Analoge wandeln kann, ist das immer noch besser als gar kein Plan B.
Uwe B. schrieb: > Es ist natürlich in der Praxis bei > normalen Quellen unhörbar. Es ist generell unhörbar. Grob gesagt besteht das Ohr aus einer Kette von Resonanzkreisen mit Nervenausgängen. Das Ohr kann also gar nicht einzelne Perioden oder den Jitter hören. Die Zeitkonstante des Resonanzkreises läßt das nicht zu. Das Ohr arbeitet daher völlig anders als ein ADC. Und nur deshalb funktioniert überhaupt MP3. Das Ohr kann nur sehr niederfrequente Schwankungen hören (Tremolo) und nicht den Jitter einer Periode. Ein Jitter mit 44kHz ist also komplett unhörbar. Hinzu kommt noch, daß bei hohen Frequenzen gerademal ihr Vorhandensein und die Stärke hörbar ist, aber keine Signalform (Oberwellen) mehr. Jüngere hören bis 15kHz, ältere oft nur noch bis 10kHz. D.h. max bis 7,5kHz könnte man zwischen Sinus und Rechteck unterscheiden.
Angehängte Dateien:

Uwe B. schrieb: > Ich habe allerdings keine Ahnung, wie (für Tipps bin ich dankbar). Schau Dir mal "Figure 5" aus dem Datenblatt an. Ich finde, das Bild sagt alles. Der "Low-Pass-Filter" ist digital. So ähnlich meinte ich es oben mit "Oversampling" und "Mittelwerte"^^. Ich stelle es mir in VHDL recht einfach und preiswert vor. Mehrere AD1896 sind wahrscheinlich teurer. Als "TDM MODE APPLICATION" (Figure 11) kann man I²S-Eingänge sparen. Ein Fehler in VHDL ist sicherlich leichter korrigiert als im "PCB-Layout". Gemacht habe ich bisher weder das eine noch das andere. Auch wenn sich das Thema für mich erstmal erledigt hat, interessieren tut es mich trotzdem: "AD1896 + DSP" oder "FPGA + VHDL"? Vielleicht kann jemand mit Erfahrungen dienen?
:
Bearbeitet durch User
Angehängte Dateien:
-

1kHzMitDoubleSample.png
35 KB
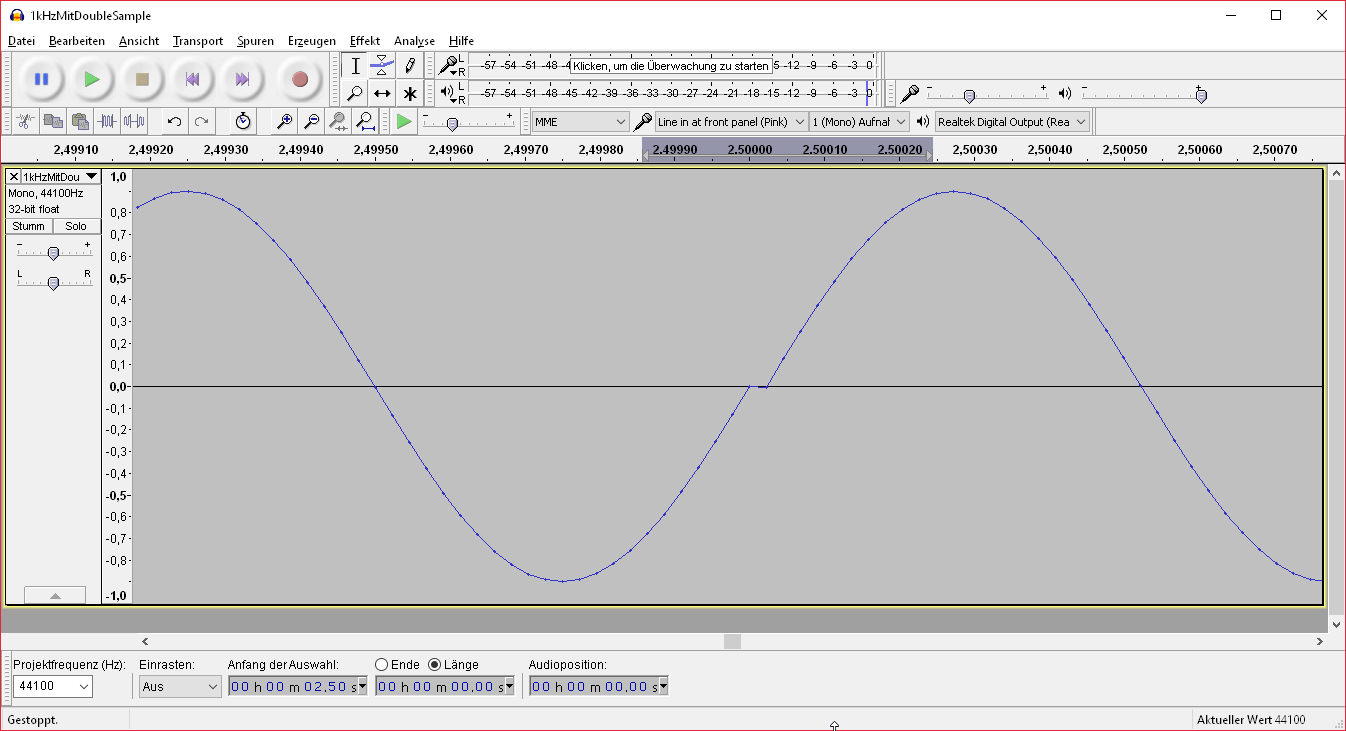
Hallo Peter, es ist mir doch unangenehm, wenn ich etwas aus der Erfahrung schreibe, und dann belehrt werde, dass ich Unsinn schreibe. Peter D. schrieb: > Uwe B. schrieb: >> Es ist natürlich in der Praxis bei >> normalen Quellen unhörbar. > > Es ist generell unhörbar. Also bin ich "zur Wahrung meines Gesichts" zum Gegenbeweis gezwungen. Hier ist er. Im angehängten WAV-file ist ein 1 kHz Ton mit 5 Sekunden Dauer, bei dem bei exakt 2,5 Sekunden ein Sample verdoppelt wurde. Screenshot von Audacity siehe oben. Hör' es die dir an, und bestätige, dass das, was ich schrieb, stimmt: Uwe B. schrieb: > Es ist natürlich in der Praxis bei normalen Quellen unhörbar. > Aber mit speziellen Signalen wird es deutlich. Dieses Signal ist so eine spezielle Quelle. Und die Informationen über die Physiologie des Ohres sehe ich eher für die anderen Leser bestimmt als für mich. Grüße, Uwe
Hallo Torsten, Torsten C. schrieb: > Schau Dir mal "Figure 5" aus dem Datenblatt an. > Ich finde, das Bild sagt alles. Danke, aber das ist genau das, was ich meinte mit: Uwe B. schrieb: > "Starr", oder vielleicht auch "deterministisch" ist, wenn z.B. immer > genau 441 Samples auf 480 Samples umgerechnet werden. Z. B., wenn die > Daten eines Files konvertiert werden. Das geht verhältnismäßig einfach. Dieses Verfahren im Datenblatt setzt ein starres Verhältnis von Eingangs- zu Ausgangssamples voraus. Und wie ich ja schrieb, stimme ich mit dir überein, dass das verhältnismäßig einfach geht. Mir fällt noch ein weiteres Stichwort dazu ein: Eine (in meinem Sinne) starre SRC kann auf einem zeitdiskret arbeitenden System durchgeführt werden, aber die flexible SRC setzt eine zeitkontinuierliche Verarbeitung voraus, die ein getaktetes System nun einmal nicht kann. Nachtrag: Mit extremen Aufwand zur (ausreichend) exakten Bestimmung der Phasen der beiden Eingangssinale, entweder durch enorm hohe Abtastfrequenzen oder besser durch AD-Wandlung der Takte, lässt sich rechnerisch auch in einem rein digitalen System das nachvollziehen, was sich durch direkte AD- und anschließende DA-Wandlung der Signale erreichen lässt. Das ist zwar kein rein digitales System mehr, aber ein anderer Ansatz, der vielleicht sogar zu einer besseren Signalqualität führt.
:
Bearbeitet durch User
> Es ist natürlich in der Praxis bei normalen Quellen unhörbar. Was ist normal? Man hört sowas schon bei reiner Klaviermusik, es sind einfach regelmässige Knackser. Klar, bei Motörhead fällts weniger auf... Die AD189x können sich auf unbekannte Sampleratenverhältnisse einstellen, indem sie einfach die Sampleraten (bzw die Bitclocks, da werden die Unterschiede schneller sichtbar) gegeneinander vergleichen. Allerdings braucht das auch etwas Zeit, extreme Änderungen im us-Takt werden zwangsweise ausgemittelt. Das Verhältnis geht dann in die Koeffizienten eines Polyphasen-Filters. Den braucht man so oder so zum Resamplen. Im AD1896-Datenblatt gibts eine "Theory of Operation".
Uwe B. schrieb: > Dieses Verfahren im Datenblatt setzt ein starres Verhältnis von > Eingangs- zu Ausgangssamples voraus. F_s_in kann Schwankungen unterliegen, z.B. zwischen 48000,034 und 48000,125 Hz. ^^ Also kein starres Verhältnis. Oder wie war die Frage gemeint?
:
Bearbeitet durch User
Hallo Torsten, ich müsste doch eigentlich eindeutig formuliert haben: Das Verfahren hinter dem Bild aus dem Datenblatt setzt ein starres Verhältnis von Eingangs- zu Ausgangssamples voraus. Ich frage aber nach einem nicht-starren Verhältnis von Eingangs- zu Ausgangssamples, bzw. wir haben es hier damit zu tun. Also mit z.B. 48000,034 und 48000,125 Hz, wobei sich die genauen Frequenzen ständig leicht ändern können. Korrekt: Das ist kein starres Verhältnis. Oder habe ich dich dieses Mal falsch verstanden? Wir kriegen das hin :-)
Uwe B. schrieb: > Wir kriegen das hin :-) Hoffentlich. Vielleicht versteht ein Mitleser, wo wir aneinander vorbei reden. Das ist doch genau so wie bei D/A- und anschließender A/D-Wandnung, nur dass der Tiefpass dazwischen nicht analog sondern digital ist. Bezogen auf das Bild "InterpolationAndResampling.png": Die Frequenz "F_s_in" kann beliebigen Schwankungen unterliegen und du fragst nach genau so einem nicht-starren Verhältnis von Eingangs- zu Ausgangssamples. Es wird halt immer der letzte Momentanwert genommen. Durch das "Oversampling" gibt es auch Zwischen-Werte. Nur als Gegenbeispiel: Bei "1kHzMitDoubleSample.png" gibt es keine solchen "Zwischenwerte".
:
Bearbeitet durch User
Ich glaube, ich verstehe. Du schriebst das Stichwort "Oversampling": Tatsächlich kann ich ein ankommendes Signal z. B. in einem FPGA mit vergleichsweise hoher Frequenz starr oversamplen und dann den jeweils am besten passenden herauspicken. D.h., bei nur 4-fachem Oversampling würde ich 4-mal so viel Phasensprünge (Auslassen oder Verdoppeln) bekommen, aber mit nur 1/4 der Amplitude und damit 1/16 der Energie. Mit entsprechend höheren Verhältnissen würde das entsprechend besser, nur die Leistungsfähigkeit der Hardware limitiert den Gewinn. Das ist zwar keine prinzipielle Lösung, aber eine Lösung, bei der das Phänomen zumindest in interessantem Maße reduziert wird. Hinzu kommt aber, dass die bisherigen Störungen im Sekunden-Bereich jetzt zwar mit erheblich geringerer Amplitude, aber dafür mit einer Frequenz näher am oder sogar im Hörbereich auftreten. Der Umweg über DAC und ADC bietet zwar eine prinzipielle Lösung, aber deren Nachteil ergibt sich aus den Schwächen der Analogtechnik. Gibt es einen Hinweis, dass die SRC-ICs genau so, als mit Sample-skipping -und doubling bei großer OSR arbeiten? (Lies' doch selber - ich weiß - aber zumindest nicht jetzt.) Uwe
> Lies' doch selber - ich weiß - aber zumindest nicht jetzt.
Warum nicht? Alles andere ist Second Source... Das Stichwort ist immer
noch Polyphase-Filter.
Uwe B. schrieb: > Im angehängten WAV-file ist ein 1 kHz Ton mit 5 Sekunden Dauer, bei dem > bei exakt 2,5 Sekunden ein Sample verdoppelt wurde. Screenshot von > Audacity siehe oben. Hör' es die dir an, und bestätige, dass das, was > ich schrieb, stimmt: Also für mich hört sich der Ton im VLC-Player sauber an. Was soll denn bei 2,5s zu hören sein?
Angehängte Dateien:
-

Ggeiz_ist_geil.png
11 KB

Der Mensch kann es wahrscheinlich nicht hören. Aber die Technik entlarvt es gnadenlos, wenn ein Sample bei 2.5s eingefügt wird.
@ Peter Dannegger (peda) >> Im angehängten WAV-file ist ein 1 kHz Ton mit 5 Sekunden Dauer, bei dem >> bei exakt 2,5 Sekunden ein Sample verdoppelt wurde. Screenshot von >> Audacity siehe oben. Hör' es die dir an, und bestätige, dass das, was >> ich schrieb, stimmt: >Also für mich hört sich der Ton im VLC-Player sauber an. >Was soll denn bei 2,5s zu hören sein? Ein Knackser. Da muss man aber SEHR genau hinhören und es wissen. So ein Sinus ist kein normales Tonsignal. Wie hört sich sowas bei normaler Musik an?
Ich bin echt baff. Hat das echt von euch noch keiner am eigenen Ohr ausprobiert, was passiert, wenn man selten Samples auslässt bzw. verdoppelt? <ichhabsschonimmergewusst>Damals (vor 22 Jahren), als ich mein erstes SPDIF-Interface für den Atari Falcon gebaut habe, war genau der Effekt das überraschendste. Da konnte man auch wählen, ob der Wiedergabetakt vom SPDIF-Eingang kommt oder trotz SPDIF-Daten aus einem Quarz erzeugt wird. Ich hätte vorher nie gedacht, dass das so auffällig sein kann.</ichhabsschonimmergewusst>
@ Georg A. (georga) >Ich bin echt baff. Hat das echt von euch noch keiner am eigenen Ohr >ausprobiert, was passiert, wenn man selten Samples auslässt bzw. >verdoppelt? Salvo errore et omissione!
Matthias S. schrieb: > Ich habe nichts von Jitter gesagt, sondern nur, das die Quellen > asynchron sind. Richtig, daher habe ICH das auch eingeworfen, denn der Jitter IST genau das Problem. Ohne einen Ratenkonverter (mit Buffer, der dafür nötig ist und dem damit verbundenen Abfangen des Jitters) bekommt man beim starren Übernehmen des Digitalsignals genau DADURCH die Probleme. Wenn man einfach nur ab und zu ein Sample verliert oder dupliziert, dann bekommt man den "kleinen Fehler" in dem hier über mir geposteten Audiofile, wobei auch das definitiv grundsätzlich hörbar ist (offenbar halt nicht von Jedem und in jedem Fall, wie man hier sehen kann). Wenn aber die eingehende Samplerate auf einem Kanal ziemlich genau der des anderen entspricht (und genau DAS ist bei guten Geräten ja der Fall) dann bekommt man bei fast gleichen Phasen STÄNDIG Phasensprünge infolge des Jitters. Den Effekt kann man schön beobachten, wenn ich mein altes TM D1000 Digitalpult anschalte und zwei Quellen von Außen nehme und noch nicht vom internen auf den externen Takt umgeschaltet habe. Man hört erst einmal einen durchaus guten Klang, teilweise nur leichte Störungen, aber nach etwas Warten, wenn die Takte der Quellen zufällig "passen", gibt es ein absolut mieses Gezerre, bis die Takte wieder auseinander gelaufen sind. Das kann schnell sein oder langsam, manchmal sind die mehrere Sekunden so synchron, dass die Takte ständig pendeln. Nach dem Umschalten am Pult nutzt es dann den externen 1 als Master und den zweiten Ext2 über den Ratenkonverter. Der ist zwar nix Besonderes, weil noch vor der Jahrtausendwende mit Standardchips gebaut, aber er löst das Problem perfekt. Da ist nichts mehr zu hören und fast nichts mehr zu messen. (Habe mal einen Supersinus reingegeben und das Spektrum im späteren Audiofile gemessen. Qualität besser als 90dB.)
Neuer Vorschlag für den TE: Eine Vorrangschaltung, die die Quellen nach einer bestimmten Reihenfolge auf den Ausgang lässt. Dann braucht man nur eine sehr billige DAC-Elektronik und einen Lautstärkemesser = Gleichrichter, der den Vorrang ermittelt. Das Signal, das die höchste Prio hat und zugleich auch Signal liefert, wird DIGITAL durchgeschaltet. Dann hat man jeweils nur ein Signal von Mehreren, aber voll digital. Man muss halt dann mit der Fernbedienung zusehen, dass immer nur eines an ist. Ich denke, dass ist die Lösung, die benötigt wird. Damit hat man die Funktion, aber die volle Digitalqualität. Ließe sich komplett digital in einem PLD machen, wenn man das S/PDIF decodiert, was bei einer einfachen Lautstärkeerkennung auch nochmal einfacher wäre. Man gibt dann einfach DAS Signal hart durch, das "gewonnen" hat. Darf man mal fragen, wer das Digitalsignal überhaupt auswertet? Lautsprecher mit Digitaleingang nehme ich an? Wenn es nur 3 Quellen wären, gäbe es auch die Option, einen Digitalmonitor zu nehmen, denn die haben oft XLR, TOSLINK und COAX als digitale Eingänge. Umgeschaltet wird am Speaker.
Falk B. schrieb: > Ein Knackser. Da muss man aber SEHR genau hinhören und es wissen. > So ein Sinus ist kein normales Tonsignal. Wie hört sich sowas bei > normaler Musik an? Ich höre das selbst in komplexer Geigenmusik heraus, wenn die Saite mal zu sehr kratzt. Solche Knackser kommen bisweilen auch durch schlechte Verbindungen und beschädigte Kabel. Und es ist sehr auffällig und sehr unangenehm und konterkariert den Wert der digitalen Technik vollständig. Aussetzer im Datenstrom geht garnicht. Hinten und vorne nicht. Selbst die Gleichlaufschwankungen bei Cassetten-Recordern und billigen Tonbandgeräten früherer Tage sind da leichter hinzunehmen. Man muss das auch im Zusammenhang sehen: In der Studiotechnik werden mehrere Signale gemischt und wenn da Phasen von Mikrosignalen springen, dann verschiebt sich schlagartig das Stereobild. Diese Problematik der Phasensprünge haben wir im Übrigen auch bei der DDS und dort ist sie der Grund, warum viele Puristen (z.T. zurecht!) digitale Synthesizer nicht mögen, weil die bei den üblichen zeitlichen Auflösungen im Bereich der Samplerate hörbare Artefakte produzieren, die sich aus Faltprodukten der Abtast- und Kanalfrequenzen ergeben und nicht im Zusammenhang mit der Tonfrequenz stehen und daher leicht erkennbar sind. Wer möchte: Effekte des Phasensprungs bei DDS: http://96khz.org/oldpages/limitsofdds.htm Auswirkung des Jitters bei digitalem Audio: http://96khz.org/oldpages/jitterinaudiosystems.htm Jittermessung in Digitalpulten: http://96khz.org/oldpages/jittertestsystem.htm
Falk B. schrieb: > Ein Knackser. Da muss man aber SEHR genau hinhören und es wissen. Ich müßte mal den Kopfhörer holen und sehr laut aufdrehen. Es wäre mal interessant, ob andere bestätigen können, daß es hörbar ist. Ich denke aber, man kann damit leben, da man eben nicht weiß, wann es passiert. Uwe B. schrieb: > Also bin ich "zur Wahrung meines Gesichts" zum Gegenbeweis gezwungen. Ich erhebe auch nicht den Anspruch, immer nur die absolute Wahrheit zu schreiben. So ein Forum ist ja auch dazu da, mal was neues zu lernen. Ich möchte aber lieber nicht wissen, welche Signalfehler alle im digitalen Pfad einem vorgesetzt werden. Teilweise liegen digitale Fehler bestimmt nur an Softwarebugs, bloß ist es schwer, diese zu hören. Bzw. man hört irgendwas komisches, kann es aber nicht zuordnen, liegt es an der Aufnahme, Speicherung, Komprimierung, Übertragung, Dekodierung usw. Was mir z.B. sehr unangenehm beim Kabel-TV aufstößt, ist das Muting an leisen Stellen. Man hört plötzlich das Räuspern des Publikums nicht mehr.
Jürgen S. schrieb: > Eine Vorrangschaltung, die die Quellen nach > einer bestimmten Reihenfolge auf den Ausgang lässt. Das wurde schon mehrfach vorgeschlagen, will er aber aus unbekannten Gründen nicht.
Peter D. schrieb: > Ich möchte aber lieber nicht wissen, welche Signalfehler alle im > digitalen Pfad einem vorgesetzt werden. Eigentlich KEINE! Es gibt zwar einen Abtastjitter, der jedoch bei heutigen Wandlern sehr klein ist, sofern gute Technik eingesetzt wird und nicht die lumpi-Soundkarte aus dem PC oder das Super-Audio-IF made in China für 99,- vom Grosshändler. Ferner gibt es einen Abspieljitter, der von der Technik abhängt, die im Wohnzimmer steht. Da kommt es eben drauf an, ob es ein guter AVR ist oder ein Billigteil. Es gab mal einen Aufnahme- und Pressjitter bei Audio-CDs der infolge der digitalen Abspielmethodik aber praktisch weg ist und durch den obigen ersetzt wurde. Und es gibt einen Jitter in digitalen Monitoren, der aber auch klein ist. Manchmal gibt es einen technisch bedingten relevanten Jitter bei USB-Audio, je nach Verkopplung. Das war es. Die Nichtlinearitäten in der Kette sind heute so klein, dass sie in den Ungenauigkeiten der Lautsprecher untergehen, sofern ordentliche Verstärker verwendet werden. *Aber*: Es gibt Leute, die den Musikern und Musikliebhabern einreden wollen, dass man 8 vollwertige Musikkanäle als reduziertes 7:1 übertragen und diese auch noch in einen 2D-Stream reinkomprimieren kann und es gibt andere, die generell alles in mp3 packen und behaupten, dass sei Qualität. DAS sind die Artefakte, die uns vorgesetzt werden. Peter D. schrieb: > Das wurde schon mehrfach vorgeschlagen, will er aber aus unbekannten > Gründen nicht. Dann bin ich auch überfragt.
Also ich höre den Knackser sehr deutlich. Auch bei z.B. angespielten Klaviernoten sind sie wahrnehmbar. Für mich wären Geräte mit solchen Artefakten inakzepabel.
Jürgen S. schrieb: > Eigentlich KEINE! Dann macht wohl der Kabelanbieter die Fehler rein. Ich nehme Konzerte von ZDFkultur auf und da gibt es gravierende Qualitätsmängel. Neben der Stummtastung leiser Stellen stört ein leichtes Zischeln, die AC3-Spur ist minimal besser. Sogar auf Youtube ist die Qualität besser.
Peter D. schrieb: > Ich nehme Konzerte von ZDFkultur auf und da gibt es gravierende > Qualitätsmängel. Neben der Stummtastung leiser Stellen stört ein > leichtes Zischeln, die AC3-Spur ist minimal besser. > Sogar auf Youtube ist die Qualität besser. Ich nehme mal an das du die Rock und Pop Konzerte meinst. Viele davon sind digitalisierte Masterbänder bei denen die Urform analog war. Selbst wenn der Mitschnitt digital war kommt es darauf an wie der Mitschnitt erfolgte. Es gibt himmelweite Unterschiede zwischen Digitalpulten, vorallem bei den Mikrofonwandlern. Wenn der Mitschnitt also z.B. nur die Stereosumme vom FOH war dann ist auch das digitale Signal oft grenzwertig. Livepulte sind nun mal keine Studiopulte. Es sei denn man setzt live z.B. auf Stagetec Nexus und holt sich dort das Signal per Madi ab wenn dann der Mitschnitt einfach nur da native Nexus Signal ist und im Studio auf entsprechendem Equipment aufbereitet wird für DVD / BluRay oder TV, dann sieht die Welt komplett anders aus. Das Zischeln in der Stereospur kommt vom Codec, diese Spur ist ein 192kbps verlustbehaftet codierter mpeg Stream. Die AC3 Spur ist normalerweise verlustfrei komprimiert (gemuxte AES-id3 Signale). Das Stummtasten kann von einem Rauschreduktionsverfahren kommen. Gruß René
Mach' das Projekt doch einfach zweistufig. Erst stellst du alle Quellgeräte auf digital um (also neue Kabel ziehen und alles umkonfigurieren), mischst dann aber trotzdem noch analog. - D/A-Wandlung erst kurz vor der endgültigen Ausgabe, also wenig Schaden im Signal. Keine Scherereien mit digitalem Clipping, Jitter oder unterschiedlichen Sampleraten. - Für die Familie ändert sich erstmal nix, und du siehst frühzeitig, ob alle deine Geräte S/P-DIF ordentlich machen oder ob es da ganz fürchterlich stinkt, z.B. bei der Software auf den Geräten. - Du hast dein Backup-System, wenn deine FPGA-/DSP-Entwicklung (noch) nicht sauber funktioniert oder mal kaputtgeht. Ich sehe da nur Vorteile. Und wenn der Teil steht, kannst du in aller Ruhe deinen S/P-DIF Mixer mit dazu passender Box entwickeln, testen und bauen.
@S. R. (svenska) >Mach' das Projekt doch einfach zweistufig. >Ich sehe da nur Vorteile. Und wenn der Teil steht, kannst du in aller >Ruhe deinen S/P-DIF Mixer mit dazu passender Box entwickeln, testen und >bauen. Aber damit zerfällt doch das seit gut 20 Jahren bewährte Konzept, nur drüber zu philosophieren und nie mal den Hammer in die Hand zu nehmen. Das wollen wir doch nicht ;-) Ausserdem, wenn die Analoglösung einmal funktioniert, wird dieses Provisorium ewig halten und die volldigitale Version nie angefangen werden.
Falk B. schrieb: > Ausserdem, wenn die Analoglösung einmal funktioniert, wird dieses > Provisorium ewig halten und die volldigitale Version nie angefangen > werden. Das ist doch prima. Nichts hält länger als ein Provisorium, und die Familie wird bis zum Auszug (oder dem Dahinscheiden) ewig glücklich sein. ;-)
Uwe B. schrieb: > Gibt es einen Hinweis, dass die SRC-ICs genau so, als mit > Sample-skipping -und doubling bei großer OSR arbeiten? Datenblatt: "The AD1896 is conceptually interpolated by a factor of 2^20" Bzw. in "InterpolationAndResampling.png"^^ oben links im Kasten. Das spricht natürlich gegen die FPGA+VHDL-Methode und für AD1896+DSP. Peter D. schrieb: > will er aber aus unbekannten Gründen nicht. Steht aber oben. Ist noch was unbekannt?
:
Bearbeitet durch User
Torsten C. schrieb: > Peter D. schrieb: >> will er aber aus unbekannten Gründen nicht. Wollte er schon, aber er schrieb auch: "zumindest nicht jetzt". Weil er auch noch was Anderes zu tun hat. Jetzt hat er aber. Und es ist wirklich ziemlich gut beschrieben. Auch die Punkte, von denen ich mir vorstelle, "Moment mal, wie soll denn das gehen", also mal eben mit 1 Million zwischen zwei 5 µs-Samples interpolierten Werten zu arbeiten oder mit einem endlich schnellen, zeitdiskreten System Phasenverhältnisse mit 5 ps Auflösung zu bestimmen, beginnen so langsam klar zu werden. Es scheint mir mittlerweile so, dass sich ein so arbeitender SRC auch in einem FPGA realisieren lässt. Da muss ich noch ein wenig studieren. Vielleicht, wenn ich mal groß bin... aber zumindest nicht jetzt.
Uwe B. schrieb: > Es scheint mir mittlerweile so, dass sich ein so arbeitender SRC auch in > einem FPGA realisieren lässt. An dieser Frage würde ich gern dran bleiben. Für erste "Gehversuche" mit dem Thema verstaubt schon seit einiger Zeit ein solches "Toslink to I2S WM8804 Board" in meiner Bastelecke, siehe auch ebay 321407674087: http://www.audiophonics.fr/en/interfaces/sure-digital-interface-spdif-coaxial-optical-toslink-to-i2s-wm8804-board-p-10098.html Zum Thema "Jitter"^^: Im Datenblatt vom Wolfson WM8804 steht: > A pass through option is provided which allows the device > simply to be used to clean up (de-jitter) the received digital > audio signals. Der WM8804 hat doch keinen nennenswerten FIFO. Wie geht das? Also stellt sich m.E. auch noch die Frage, ob man sowohl den WM8804 als auch den AD1896 spart und beide Funktionen in einem FPGA abbildet oder ob man besser (anderes Extrem) mit mehreren WM8804 und kaskadierten AD1896 und einem DSP arbeiten würde. Mir erscheinen diese zwei Varianten die attraktivsten zu sein: ❶ N x S/P-DIF → FPGA → S/P-DIF oder ❷ N x (WM8804 + AD1896) → I²S/DSP/I²S → WM8804 Uwe B. schrieb: > … 1 Million zwischen zwei 5 µs-Samples interpolierten Werten … Ob man das am besten mit einem FPGA macht? Ich weiss es auch nicht. Vielleicht muss es ja keine OSR von 2^20 sein. Bei ❶ könnte man in VHDL mit variablem Block-RAM-FIFO noch eine Jitter-Optimierung "nachrüsten". Bei ❷ würde man auf bewährte SCR-Algorithmen zurück greifen, statt "das Rad neu zu erfinden". PS: Bei ❶ wäre der Aufwand für die PCB-Bestückung kleiner und auch das PCB kleiner und preiswerter.
:
Bearbeitet durch User
Hallo Torsten, ganz entscheidende Frage: Wo bekommt man diese schönen ❶ und ❷ (und sicherlich noch viele andere interessante Symbole) her? Wenn ich dich richtig verstehe, ist für dich weniger das fertige System das Ziel als der Weg dort hin. Wäre das fertige System das Ziel, würde ich dir auch zum Mischen von mehreren analogen Signalen aus DACs, mit analogen Pegeleinstellern nach den DACs oder höchsten digitalen Pegeleinstellern vor den DACs raten. Auch für mich wäre der Weg das Ziel. Ich habe schon einige, wie ich meine nicht unbedingt triviale Audiotechnik auf FPGAs gemacht, wobei ich grundsätzlich jeden Code selber schreibe. Auch S/PDIF Rx- und Tx war dabei und das einfache Mischen von unsynchronen Quellen mit Vermeidung der heftigen Störungen, die beim Phasendurchlauf entstehen, wenn man es sich zu einfach macht. Ein guter SRC schien mir bisher aber unlösbar, während er jetzt möglich scheint und ich mir das gerne als praktisches Know-How aneignen würde. Von vielen Detailaufgaben habe ich eine Vorstellung, wie man da 'ran gehen könnte, weiß aber nicht, ob die Ideen dazu zu dem gewünschten Ergebnissen führen würden (Beispiel: Phasenerkennung, digitale PLL). Aber andere Theorien fehlen mir ganz, zum Beispiel die Polyphasenfilter (mit IIR-Filtern kenne ich mich dafür gut aus, aber das nützt nix) und vor allen Dingen gibt es höchstwahrscheinlich noch so viele Details und Klippen zu umschiffen, dass ich nicht glaube, dass in meinem Leben im Rahmen meines Hobbys zu schaffen. Bei AD hat das sicherlich auch nicht ein einzelner mal so nebenbei gemacht. Also nicht ❶, d.h., selber etwas auf die Beine stellen, sondern ❷: Zukaufen. Was liest man hier dann so oft: Wozu das Rad neu erfinden, wenn man doch alles kaufen kann? Ja, wozu überhaupt was lernen, wenn man doch alles kaufen kann? Und wozu die ganzen Kraftwerke - bei uns kommt der Strom doch auch aus der Steckdose! (Mit den Kühen und er Milch aus dem wüste ich auch noch einen...) Ja, ich bin ein Anhänger von "selber können", nicht zukaufen, nicht abkupfern, aber damit komme ich natürlich nicht so weit, wie jemand, der einen mit mit einem Raspi und Open-Source-Software komplexe Projekte erstellt, die ich zu Fuß niemals überhaupt nur in Erwägung ziehen würde. Als S/PDIF-Rx habe ich CS8416 und LC89091 (letzterer ist super-klein, super-einfach und super-billig). Zur Jitter-Optimierung bzw. De-Jitter braucht man kein RAM, denn der Jitter ist viel kleiner als eine Sample-Periode. Ein einfacher Puffer als 1-Sample-FIFO reicht um Jitter von +- 1/2 Sample zu abzufangen. Für einen versierteren µC-Programmierer als mich wäre ❷ eine simple Routineaufgabe. Ein µC hat auch einige Hardware an Board, die mit einem FPGA extern realisiert werden müsste, z. B. einen ADC um die Potis für die Lautstärke einzulesen. Ich habe hier PIC32MZ in Betrieb, der hat 4 I2S-Schnittstellen - damit kommt man auch schon ganz schön weit. Ganz neu: Die ALTERA MAX10 haben auch ADCs. Mit denen + SRC könnte auch ich routinemäßig das Ganze realisieren. GGF. sogar ohne separate S/P-DIF-Rx und -Tx: ❸ N x (S/P-DIF → FPGA → I2S → AD1896 → I2S) → FPGA → S/P-DIF. Ach, du schreibst korrekt S/P-DIF, das finde ich gut, ich hatte das auch getan und dann auf S/PDIF vereinfacht, aber SPDIF finde ich doch zu sehr verstümmelt. Grüße, Uwe Nachtrag: Gefunden: ❸!!!
:
Bearbeitet durch User
Torsten C. schrieb: > Mir erscheinen diese zwei Varianten die attraktivsten zu sein: > 1 N x S/P-DIF → FPGA → S/P-DIF oder > 2 N x (WM8804 + AD1896) → I²S/DSP/I²S → WM8804 Du musst schon einiges tun, damit Du mit einem FPGA besser wirst, als der Chip. Wenn Du einfach digital über-abtastest, bist Du schlechter, weil die Chips das intern mit einigen Gigahertz können und der FPGA rund Faktor 10 langsamer ist. Um ein Sample auf GH abzutasten, brauchst du im FPGA mehrere lanes, die parallel zeitversetzt arbeiten. Ich habe für eine Nicht-Audio-APP eine Applikation entworfen, die das mit 2 PLLs zu insgesamt 16 Takten kann. Die Granularität beträgt 150MHz 16 ca 8, weil ich noch parallel switchbare IO-lanes mit justierten IO-Delays verwende. Das möchtest Du aber sicher nicht bauen. Der Grund, warum ich seinerzeit mit FPGAs resampelt habe, war, dass es keine 96kHz resampler gab - und als es sie gab, hatte meine Hardware schon 384kHz intern. Zudem rechne ich mit einem echten Interpolator auf FIR-Basis, der den mathematischen Zwischenwert zwischen zwei Samples einfach ausrechnet. Übergeben wird dabei eine angepasste Interpolationsgleichung, die für eine bestimmte Periode gilt. Damit kann in der anderen Domain, JEDER Zwischenwert ausgerechnet werden. Die Gleichungen überlappen, sodass man irgendwann wechseln kann. Auch das läuft mit der damaligen FPGA-Taktfrequenz von 25 MHz, hat halt nur einige Takte delay. Du musst dazu eine Gleichung bilden, die auf 5-7 Samplepunkte schaut und mit wenigstens 48 Bit Genauigkeit rechnet. Ob sich das lohnt, sei dahin gestellt. Die Genauigkeit entspricht etwa dem, was man mit offline-Korrekturen auf Samplebasis im Bereich 48kHz hinbekommen kann. Das ist den gängigen resamplern, die man kaufen kann, nach wie vor auch überlegen. Aber es kostet halt rund das 50-fache :-) Uwe B. schrieb: > Zur Jitter-Optimierung bzw. De-Jitter braucht man kein RAM, denn der > Jitter ist viel kleiner als eine Sample-Periode. Man braucht im Prinzip nur 2 Worte an Buffer, um einschreibende Domain und auslesende Domain zu trennen. Da man aber mit einer entsprechenden Überabtastung und Filtern arbeitet, braucht man eine entsprechende Zahl von Filter-TAPs mit Koeffizienten- und Daten-RAM. Der Filter muss sich über wenigstens 3, besser 5 samples erstrecken und inklusive Überabtastung mit z.B. 128 bekommt man da schon einige BRAMs voll. Lässt man den Filter weg, gibt es Interpolationsartefakte und man erreicht nicht die hiQu-Audiogüte. Denkbar sind optimierte Methoden mit einem CIC und einem FIR auf sample-Frequenz. Realisiert habe ich auch schon einen 5:1 für 192kHz siehe mein Drumcomputer Design auf Spartan 6 Basis. An den TE: Wenn wir mit unseren Universalboard schon weiter wären, könnte ich Dir was anbieten: Beitrag "Re: Suche Mitwirkende für Universal-FPGA board" Angedacht sind 8 S/PDIFs pro Karte rein und auch wieder raus für 8-Kanal-Audio. Das System kann Echokompensation und Intermodulationskompensation.
Wie mischt man eigentlich das Copyprotection-Bit? (duckundweg)
:
Bearbeitet durch User
Hallo Jürgen, ich schätze, dass du an der FPGA-Front mehr Erfahrung als ich hast. Wenn du meinst, meine Vorstellungen wären Unsinn, lass' es mich wissen (aber gaaaaanz schonend ;-) Jürgen S. schrieb: > Um ein Sample auf GH abzutasten, brauchst du im > FPGA mehrere Lanes, die parallel zeitversetzt arbeiten. In ADs SRC wird die Phase auf 5 ps genau bestimmt, das klingt nach einer Abtastrate von 200 GHz. Das muss offensichtlich anders gehen, und ich halte es für ziemlich sicher, dass folgendes passiert: Die erwähnte digitale PLL braucht sehr viele Samples, bis sie eingeschwungen ist. Sie mittelt also sehr viele mit relativ grober Abtastung und großen Fehlern behaftete Zeitpunkte der Taktflanken (Rauschen in der Bestimmung der Phase). Je mehr sie mittelt, desto feiner die Auflösung des DDS-Oszillators ist, desto genauer wird die Bestimmung der momentanen Frequenz und Phase (Tiefpass für das Rauschen). Natürlich wird die Bestimmung auch proportional mit der Sample-Rate genauer (kleineres Rauschen), also sollte die auch möglichst hoch sein. Ich denke, dass man ohne sehr große Mühe mit nur einer Taktphase im FPGA mit 100 - 200 MHz abtasten kann, aber um daraus eine 1000-fach höhere Genauigkeit zu mitteln, braucht es sehr lange. Im Quadrat, weil der Fehler (das Rauschen) statistisch verteilt ist, also Faktor 1000²? Bei 192 kHz wären das 5 Sekunden, vielleicht nicht mal unrealistisch, wenn man noch die eine oder andere Kohle nachlegt? Es sind, glaube ich, 5 um 72° versetzte Takte, die bei einer Altera-PLL (oder war es ein Clock-Modul oder so was?) von Haus aus zur Verfügung stehen. Dann ist es nur noch 1 Sekunde. Deswegen schrieb ich auch: "ich weiß aber nicht, ob die Ideen dazu zu dem gewünschten Ergebnissen führen würden...". Aus der Phaseninformation wird dann die genaue Position des zu interpolierenden Ausgangssamples bestimmt, daraus wiederum die Koeffizienten für den Filter (das sehe ich als besondere Herausforderung, AD schreibt, dass auch die Filterkoeffizienten aus einer kleineren Tabelle interpoliert werden - linear?), dann verwenden die einen 64-Tap-FIR (wieder einfach). Das schreibt sich leicht, aber wenn man das codiert und zum Laufen bringen will, kommt, schätze ich, so manches "Ach du Schei..., was nun?"-Erlebnis. Beispiel: Es geht nicht ohne Vereinfachungen. Aber welche Vereinfachung erzeugt wie viel Fehler? Mach ich an irgendeiner Stelle völlig überflüssig viel Aufwand, und an einer anderen durch eine zu starke Vereinfachung zu viel kaputt? Wie einfach darf ich die Tabelle und ihre Interpolation machen? Grüße, Uwe Copyprotection: Das geht bei Addition clockwise: 2 x Copyright = 1 x Copyback, 3 x Copyright = 1 x Copyleft, 4 x Copyright = Gar kein Copy.
Joe F. schrieb: > Wie mischt man eigentlich das Copyprotection-Bit? You just made my day! +1 :-) Das waren noch Zeiten, ich hatte 2 DAT-Recorder. Alles andere später, bin gerade im Stress.
:
Bearbeitet durch User
Moin, In der xapp514.pdf gibt's ein Kapitel "Asynchronous Sample Rate Converter". Das unters Kopfkissen legen, kann ja mal nicht schaden. Zu den absurden Abtastraten - das muss man eher relativ sehen :-) Man kann z.b. 2 Tiefpassfilter bauen, die sich hauptsaechlich in der (bei jedem dieser Filter moeglichst konstanten) Gruppenlaufzeit bloss um ein kleines Bisschen unterscheiden, also z.b. um 5ps - damit kann man dann bei "normalen" Abtast- und Taktfrequenzen solche etwas erhoehten Anforderungen relativ "billig" hinkriegen. Gruss WK
Hallo WK, der XAPP415-Tipp ist wirklich gut. Leider habe ich gestern Abend versäumt, es mir unter's Kopfkissen zu legen, deshalb musste ich heute morgen hinein schauen. Viel Wissen, viele Erklärungen, viel Text - zu viel, um es mal eben alles zu verstehen und nachvollziehen zu können. Das käme erst dann, wenn ich mich die nächsten Wochen und Monate ernsthaft mit dem Thema befassen wollte. Wichtig ist mir die Wahl der Fachbegriffe: Was ich oder wir als "flexible" oder "asynchrone" SRC bezeichnen, also zwei Quellen mit nominell gleicher, aber minimal unterschiedlicher Frequenz, nennt sich "plesiochron". "Asynchron" ist mit nominell ungleichen und nicht starr gekoppelten Frequenzen. Das mit den 2 Tiefpassfiltern habe ich nicht verstanden. Es geht doch nicht darum, zwei um 5 ps versetzte Ergebnisse zu bekommen, so wie ich deine Aussage verstehe. Es wird ja auch nicht mit absurden 200 GHz abgetastet, es wird nur auf 1/(200 GHz)-stel genau angegeben, wie die Phasen zueinander liegen. Dafür kann man wesentlich niederfrequenter abtasten. Dazu, aber nicht unbedingt wegen deines Vorschlags, ein paar Zahlenwerte: Nehmen wir 10 ppm Frequenzunterschied an, das ist ein in der Praxis plausibler Wert. Während eines Samples verschiebt sich dabei die Phasenlage der Signale ebenfalls um 10 ppm. Bei 48 kHz ≘ ~20 µs sind das ~200 ps. 5 ps war nur die von AD genannte "Granularität", mit der in dem IC die Phasenlage aufgelöst werden kann, wobei ich meine, dass das prinzipiell nur eine Frage der Rechengenauigkeit ist und relativ leicht beliebig hoch getrieben werden kann - nur, ähnlich wie die Anzahl der Bits in einem ADC oder DAC, physikalisch ab einem bestimmten Punkt einfach nicht mehr sinnvoll ist (die Sache mit dem Rauschen und den Tiefpässen, die ich oben beschrieb) . Grüße, Uwe
René S. schrieb: > Livepulte sind nun mal keine Studiopulte. Danke für die Erläuterungen. Hätte nicht gedacht, daß es so große Qualitätsunterschiede gibt und daß sich die ÖRs keine ordentliche Technik leisten können. Vielleicht mal bessere Technik kaufen und dafür ein Fußballspiel weniger übertragen. Es wird ja immer von der Werbung suggeriert, digital sei absolut störungsfrei.
Uwe B. schrieb: > 5 ps war nur die von AD genannte "Granularität", mit der in dem IC die > Phasenlage aufgelöst werden kann, wobei Ist das gfs einfach der Phase dither, der da beaufschlagt wird? solche PLLs sind doch meistens digital mit Analogkomponente und da ist eine "Auflösung" von 5ps nichts ungewöhnliches. Schwingen tut da ganz sicher nichts mit 200GHz.
Ich wollte gerade antworten, dass es ganz offensichtlich einfach nur der Mittelwert von über lange Zeit (einigen Sekunden) mit einer Auflösung von ca. 10 ns gemessenen Sample-Perioden ist. Das würde auf ca. 5 ps Genauigkeit hinaus laufen. Da fiel mir auf, dass man ja auch direkt die Zeit von z. B. 2000 Sample-Perioden messen kann, bei 10 ns Messauflösung kommt man auch auf 5 ps. Und dann fiel mir auf, dass, wenn ich den Mittelwert über z. B. 2000 unmittelbar nacheinander gemessenen Sample-Perioden bilde (das dauert wenige Millisekunden), genau das selbe heraus kommt, dass also gar nicht mehrere Sekunden nötig sind, wie es bei unkorrelierten Messwerten der Fall wäre. Je länger ich über die Aufgabenstellung nachdenke, desto mehr erkenne ich... Dither, also künstliches Rauschen irgendeiner Art, hat hier nichts zu suchen. Eine PLL ist, soweit ich erkennen kann, im Gegensatz zu meiner früheren Vorstellung auch nicht erforderlich.
:
Bearbeitet durch User
Dein ganzes Projekt ist ein IC von AD: ADAU1445 - 9 I²S Eingänge - 1x SPDIF - 16 SRCs - Bis zu 170ms Delay - Klang - Lautstärke - Frequenzweiche - ... Gruß Jobst
:
Bearbeitet durch User
Peter D. schrieb: > Danke für die Erläuterungen. Hätte nicht gedacht, daß es so große > Qualitätsunterschiede gibt und daß sich die ÖRs keine ordentliche > Technik leisten können. Vielleicht mal bessere Technik kaufen und dafür > ein Fußballspiel weniger übertragen. > Es wird ja immer von der Werbung suggeriert, digital sei absolut > störungsfrei. Nuja die ÖR's haben schon gute Technik der BR z.B. Stagetec, der WDR Lawo ZDF meist auf Lawo oder Studer unterwegs und das sogar im Ü-Wagen. Das Problem liegt eher an den Verleihern / Livecrew. Hier haben hauptsächlich Digico, Soundcraft (gehört wie Studer zu Harman hat aber etwas abgespeckte Technik drin) oder Yamaha Pulte verwendet. Die Aufzeichnung solcher Konzerte machen jedoch meist private Firmen die sich nur entweder die Direct Outs holen oder gleich den kompletten FOH Mix und da liegt das Kind bereits im Brunnen. Dazu kommt das Livemikros oft deutlich mehr rauschen als Recording Micros. Leider auch die lieblings Mics der Rocker, Shure, nochmehr als z.B. Sennheiser. Weiterhin erhöht auch das Nutzen von Funkstrecken bei Gitarre und Bass nochmals das Rauschen. Das alles hört man im Livemix nicht, wohl aber unter Kopfhörern bei fehlendem Umgebungs"lärm". Bei den Wandlern hat derzeit Stagetec klar die Nase vorn. Die digitalisieren ohne das Mic vorzuverstärken und rechnen es danach digital hoch (Eigenrauschen von –132,5 dBu (bei einem Quellwiderstand von 0 Ohm) und kann umschaltfrei Pegel bis 24 dBu verarbeiten. Daraus ergibt sich ein Dynamikumfang von 156,5 dB) Für diese Dynamik würden 27bit ausreichen, die Karte arbeitet nativ mit 32bit). Alle anderen verstärken erst analog und digitalisieren dann. Die HD Wandler von Studer oder Lawo kommen da zwar auch fast ran aber rauschen ein wenig mehr. Alles andere an Wandlern auch die "budget" Wandler von Studer die z.B. bei Soundcraft (VI Serie) standard sind können da nicht mithalten. Nochwas zum Takt in Funkhäusern und Studios bzw. Konzerthäusern wird meist ein Haustakt verwendet. Der wird sternförmig verteilt und die Masterclock hat meist eine Rubidium Basis die per GPS auf 10MHz gehalten wird. GPS geht aber nur für Langzeitstabilität, der Wordclock oder Trilevel Sync ist für Kurzeit deutlich stabiler, die Masterclock sorgt nur für den Phasengleichlauf der Inselclocks. Bei Liveproduktionen ist meist das FOH Pult Master bzw. wird direkt mit einer externen Masterclock gesynct, die auch Trilevel für die Cams bereitstellt. Wobei manchmal auch die Cams freilaufen und das Bild und Ton erst um Studio Ü-Wagen reclockt reembeddet wird mit einem Dolby E Reclock. Bie Aufzeichnungen wird nur im Schnittsystem Video und Audio zusammengefügt dabei bedient man sich der Timecode Infos die im Bild als auch im Broadcastwave vorhanden sind. Ein guter Hörtest für dich Peter wäre der deutsche ESC Vorentscheid. Den produziert der NDR. Die nutzen soweit ich weiß Lawo Ravenna HD oder Stagetec Nexus als Wandler, setzen das Madisignal dann mit Riedel Rocknet auf Riedel Mediornet um. Im Mediornet ist dann Ton Bild Telefon etc. an jeder Senke abholbar. Für den Livemix dürfte ein Digico oder Lawo Pult benutzt werden, Monitoring könnte eine VI oder Lawo sein, der TV Ton entsteht im Ü-Wagen auf Lawo oder Studer. Mics dürften Sennheiser sein, zumindest war das in etwa das Setup beim ESC in Deutschland nachdem Lena ihn hergeholt hat. Wenn da keiner Mist baut sollte das Signal deutlich besser sein als bei den normalen Konzertmitschnitten. Es durchaus gibt noch mehr TV / Radio Ausstrahlungen oder auch CDs bei denen ich dir sagen kann womit die produziert wurden. Leider gibts da keine Möglichkeit TV und DVD/CD zu vergleichen da meist entweder für TV oder für DVD produziert wird selten beides zu gleicher Zeit. Gruß René
Hallo René, meine Vermutung ist ja, daß die Aufnahmequalität schon gut ist, aber KD es dann zu Tode komprimiert. Ich gehe direkt vom PC über Toslink auf den Onkyo, der die 2 Quadrals antreibt. CD, DVD und Youtube klingen auch sauber, nur DVB-C ärgert mich. Ich nehme die TS-Datei, d.h. auf dem PC erfolgt keine weitere Bearbeitung.
Hallo Peter, KD bearbeitet das Signal nicht, die Signale werden von den Sendern entsprechend komprimiert und an die KD Kopfstationen geliefert. Teilweise wird das auch über Satellit zugespielt auf einem verschlüsselten Transponder via Astra 28,2° Ost, zeitweise waren auch Zuspielkanäle auf 19,2°. Wie ich schon oben schrieb der normale Stereoton ist im mpeg2 drin also Video und Audio verlustbehaftet kodiert. der AC3 Ton ist zwar auch ein komprimierter allerdings mit psychoakustisch verlustbehafteter Komprimierung die deutlich besser klingt, übrigens auch auf DVD. Der Supergau entsteht eigentlich dann wenn aus dem 5.1 ein Stereodownmix gemacht wird, das ist Datenreduktion en Mass. Bei DVD hörst du den Unterschied nur deswegen nicht weil das Downmixdedöns nicht wieder digitalisiert und komprimiert wird sondern direkt zu hören ist Gruß René
Jobst M. schrieb: > Dein ganzes Projekt ist ein IC von AD: ADAU1445 > - 9 I²S Eingänge > - 1x SPDIF > - 16 SRCs > - Bis zu 170ms Delay > - Klang > - Lautstärke > - Frequenzweiche Dann brauch er aber noch die S/PDIF zu I2S wandler und es schaltet auch noch nicht automatisch um. Der IC leistet von dem was TE will, leider nichts.
Audio Manni schrieb: > Dann brauch er aber noch die S/PDIF zu I2S wandler Stimmt. Und? Sowas gibt es einfach und billig. > und es schaltet auch > noch nicht automatisch um. Will der TO ja auch nicht. Er möchte mischen. Und das kann das Ding. Die SW gibt es sogar auch schon fertig von AD. Gruß Jobst
Jobst M. schrieb: > Stimmt. Und? Sowas gibt es einfach und billig. Guter Einwurf - ich suche was Besseres, als DAS hier: Beitrag "Re: Vorstellung digitaler Audioausgang für Raspberry Pi" Uwe B. schrieb: > In ADs SRC wird die Phase auf 5 ps genau bestimmt, das klingt nach einer > Abtastrate von 200 GHz. Das muss offensichtlich anders gehen, Das ist sicher nicht die Auflösung einer digitalen PLL und die wäre auch nicht nötigt. Das klingt in der Tat mehr nach Phasenfehler, mit dem sich der Chip auf den Eingangstakt synched.
Jürgen S. schrieb: > ich suche was Besseres, als DAS hier Das ist ein I²S -> S/P-DIF Converter, soweit ich das beim Überfliegen verstanden habe. Da kann man eigentlich nicht viel falsch machen. Was möchtest Du verbessern? Wäre ein eigener Thread nicht besser geeignet? Dann aber bitte gleich mit ALLEN Angaben: - Was GENAU möchtest Du haben? - Was soll besser sein? - Was stört Dich an diesem? Gruß Jobst
Falk B. schrieb: > … vollends auf's Philosphische verlegt? Scheint fast so. Da unser Wohnzimmer nun geeignete (symmetrische?) Analog-Kabel bekommt, ich schrieb: > Der Thread ist allgemein offen für Ideen und Fragen zu dem Thema. Jobst M. schrieb: > Wäre ein eigener Thread nicht besser geeignet? Seitens des TO daher gern hier!
:
Bearbeitet durch User
Torsten C. schrieb: > Seitens des TO daher gern hier! Mag sein. Es ist nur nicht zielführend, ab nun alle Probleme zu Digital-Audio hier hinein zu schreiben. Damit wäre im Nu die Struktur eines Forums zerstört. Oder möchtest Du alle Antworten auf alle Fragen in einem einzigen Thread suchen müssen? Er verlinkt ja sogar schon auf einen anderen Thread, in dem seine Frage sogar wesentlich besser aufgehoben wäre. Er kann den neuen Thread ja auch hier verlinken. Was er macht, ist natürlich seine Entscheidung ... Gruß Jobst
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.