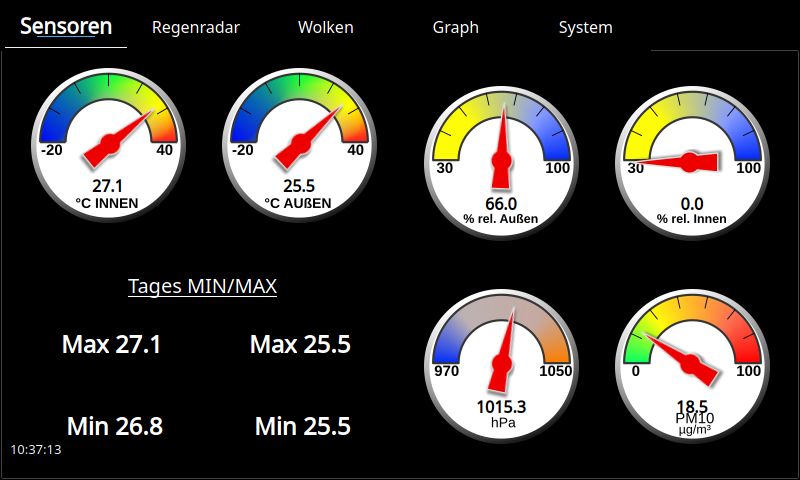
Vorhaben:
Ich möchte vorerst nur immer die letzte Reihe aus der Datei auslesen
und die Werte einfach nur plump auf meine Webseite stellen:
Temperatur innen: 27.1°C
Temperatur außen: 25.4 °C
Luftdruck: 1015.3 hPa
...
Die Webseite soll alle ~5min neue Daten "ziehen"...
Später würde ich sehr gerne per SVG/Javascript Animation
so kleine Anzeigeinstrumente auf die Seite einfügen und zusätzlich
die CSV Datei richtig als Graph einbinden, evtl sogar interaktiv mit
Zoom und so... dafür gibt es ja ein haufen JS Lösungen.
Allerdings stehe ich ein bisschen auf dem Schlauch wie ich nun einfach
von meine Webseite an die Daten in der CSV Datei komme und einbinde.
Ich hatte eine annähernde Lösung per JS, aber die erforderte immer ein
<input> mit Benutzerinteraktion (File Open.. File Drag/Drop)... das ist
nicht was ich will.
Ist das überhaupt ohne PHP machbar, nur mit JS? Oder wäre es eleganter
einfach ein C++ / Python Programm zu schreiben das die CSV Datei parst
und dann meine HTML Seite generiert bzw. periodisch nach Updateintervall
erzeugt?
Bisher habe ich meine selbst gebaute QT App verwendet (Bild) die mir die
CSV Datei parst und richtig hübsch darstellt, allerdings hab ich kein
Bock mehr auf QT wenn sich das ganze auch elegant in einem Browser
darstellen lässt....
Achso nebenbei: die Webseite soll natürlich nur lokal als Datei auf dem
RPi in einem Browser im Vollbildmodus angezeigt werden... also
irgendwelche Server einrichten war eigentlich nicht mein Ziel...
Hat jemand einen Vorschlag welcher weg sinnvoll sein könnte?
IoBroker, benutzt Websockets um die Werte dynamisch darzustellen. Kann
Daten aus so ziemlich allen Quellen lesen, natürlich auch MQTT. Und es
gibt mittlerweile wohl ein Dutzend Möglichkeiten die zu visualisieren.
Über einen IoT Adapter kann auch aus dem Internet zugegriffen werden,
das ist zwar kostenpflichtig, aber noch sehr günstig.
Paul G. schrieb:> Webseite soll natürlich nur lokal als Datei auf dem RPi in einem Browser> im Vollbildmodus angezeigt werden... also irgendwelche Server einrichten> war eigentlich nicht mein Ziel...
wenn die himbeere eh schon läuft, dann langweilt er sich mit dem messen
der sensordaten zu tode. lass ihm doch einfach die freude einen indianer
laufen zu lassen (also apache).
und schreib die daten besser in eine datenbank. also litesql, mariadb
o.ä.
an überarbeitung stirbt da trotzdem keiner
Dirk schrieb:> Anstatt über die CSV Datei zugehen bietet sich hier auch Mqtt an.>> https://entwickler.de/online/javascript/mqtt-mit-javascript-579860931.html
Ich habe eine Tasmota Wlan Steckdose die auch mqtt kann also hatte ich
das vor längerer Zeit mal angeschaut aber sorry, bei mqtt stellen sich
mir die Haare im Nacken auf... Ich komm damit irgendwie überhaupt nicht
klar... Wenn wirklich alle Stricke reißen und absolut gar nix anderes
mehr geht werde ich mir das nochmal anschauen... :D
Johannes S. schrieb:> IoBroker,
Overkill für mein vorhaben
quotendepp schrieb:> wenn die himbeere eh schon läuft, dann langweilt er sich mit dem messen> der sensordaten zu tode.
Ja wenn, dann lighttpd, das sollte auch reichen... aber wie gesagt ich
wollte eigentlich das ganze Datenbankzeug und PHP vermeiden.
Dirk K. schrieb:> Das Programm, welches in die CSV schreibt,> könnte auch eine statische HTML-Seite erzeugen.
Das war bis eben auch mein bevorzugter Gedanke, leider spricht da etwas
dagegen. Ich will dann später ja auch User Interaktion auf der Seite
zulassen.
Das bedeutet wenn ich mir gerade den Regenradar oder einen Plot aufrufe
dann will ich nicht das irgendein Auto-reloader die Seite genau in dem
Moment nachläd wenn ich mir irgendwas anschauen will. Das bedeutet es
soll(t)en wirklich nur die Werte in diversen Teilen der Webseite
aktualisiert werden (div's oder so) anstatt die ganze HTML Seite zu
reloaden.
Ich bin zwischendurch über dieses Ajax Tutorial gestoßen
https://www.youtube.com/watch?v=qqRiDlm-SnY
und versuche das mal nachzubauen. Dann lasse ich mir das daten.csv und
die Seite doch von nem kleinen Lighttpd Server liefern... mal sehen ob
das klappt.
Hallo Paul,
Mqtt ist ja eher für die Übertragung der Messwerte vom Sensor zur
"Aufzeichnung" für dein Problem also keine Lösung.
Wo kommt die Website im Moment her?
Auf dem PI brauchst du auf jeden Fall einen Webserver, lighttpd reicht.
Mit einem Pythonscript kannst du deine Daten aus der csv lesen und
praktischer Weise einen json-String erstellen den der Webserver bei
Abruf dann ausliefert. Deine Website kann diese Datei per JavaScript
mittels XMLHttpRequest zyklisch abrufen und die Werte auf der Website
mit den aktuellen ersetzen.
Sascha
>> Vorhaben:>> Ich möchte vorerst nur immer die letzte Reihe aus der Datei auslesen> und die Werte einfach nur plump auf meine Webseite stellen:>> Temperatur innen: 27.1°C> Temperatur außen: 25.4 °C> Luftdruck: 1015.3 hPa> ...>> Die Webseite soll alle ~5min neue Daten "ziehen"...> Später würde ich sehr gerne per SVG/Javascript Animation> so kleine Anzeigeinstrumente auf die Seite einfügen und zusätzlich> die CSV Datei richtig als Graph einbinden, evtl sogar interaktiv mit> Zoom und so... dafür gibt es ja ein haufen JS Lösungen.>> Allerdings stehe ich ein bisschen auf dem Schlauch wie ich nun einfach> von meine Webseite an die Daten in der CSV Datei komme und einbinde.>> Ist das überhaupt ohne PHP machbar, nur mit JS? Oder wäre es eleganter> einfach ein C++ / Python Programm zu schreiben das die CSV Datei parst> und dann meine HTML Seite generiert bzw. periodisch nach Updateintervall> erzeugt?
Ja, natürlich ist das ohne PHP machbar. Und dazu gibt es unendlich viele
Lösungen, die... naja, sich im Endeffekt einerseits durch die
verwendeten Technologien, und andererseits deswegen durch ihren Aufwand
unterscheiden.
Wie groß dieser Aufwand ist, liegt aber alleine an Dir, an dem, was Du
aus Deinen Daten machen willst, daran, ob Du zukünftig ähnliche Aufgaben
haben wirst, und was Du vielleicht zukünftig mit Deinen Daten machen
möchtest.
Ich ganz persönlich benutze für solche Aufgaben gerne Python mit numpy,
scikit oder Pandas für Numbercrunching, Datenexploration, -Analyse,
-Aggregation und natürlich die -Visualisierung, aber, naja, ich mache
das halt auch professionell und hab ein paar Jahre Erfahrung damit. Und
es ist einfach, Web daraus zu machen, Flask ist da mein Favorit fürs
Webserving in der Entwicklung -- und für die Visualisierung gibt es
ungefähr drölfzig Millionen Möglichkeiten, lokal mit Matplotlib oder im
Web mit Bokeh, Flot, mpl3d, JsWidgets, ...
Aber bitte, versteh' mich nicht falsch: ich verarbyte täglich
Massendaten, die mit hoher Wahrscheinlichkeit wesentlich umfangreicher
sind als alles, was Du vorhast. Dafür eine neue Programmiersprache zu
lernen -- und wenn es eine besonders simple wäre wie Python -- halte ich
für Unsinn, besonders wenn das Dein einziges Projekt wäre, in dem Du
(erstmal eher kleine) Datenmengen verarbeiten willst.
Aber wenn Du in zehn Jahren die Daten der letzten zehn Jahre bis ins
feinste Detail untersuchen möchtest, sieht die Sache wieder völlig
anders aus. Wenn Du in näherer Zukunft andere Daten bekommst: dann sieht
die Sache anders aus.
Ach so: Du kannst Deine Daten natürlich auch in einen ELK-Stack pumpen.
Das ist nur Konfigurationszeugs und Du bekommst eine sehr
leistungsfähige, streßfreie Lösung -- aber das wird auf einen RasPi3
nicht sauber laufen... ;-)
quotendepp schrieb:> wenn die himbeere eh schon läuft, dann langweilt er sich mit dem messen> der sensordaten zu tode. lass ihm doch einfach die freude einen indianer> laufen zu lassen (also apache).> und schreib die daten besser in eine datenbank. also litesql, mariadb> o.ä.> an überarbeitung stirbt da trotzdem keiner
Das sehe ich ähnlich, aber... eine klassische Datenbank? Wirklich?
Rein datentechnisch reden wir hier über ein Append-Only-Log. Das braucht
nichts, das eine SQL-Datenbank bietet: keine Transaktionen, kein MVCC,
...
Danke erstmal für eure Gedanken.
Ich bin zwischenzeitlich bei "Papa Parse" angekommen. Damit lese ich
einfach per JS meine daten.csv in ein Array ein. Die Datei hole ich
lokal von einem lighttpd Server ab. Jetzt kann ich mir schon mal die
letzte Datenreihe aus der csv rauspicken und nun ist es eigentlich nur
noch HTML und ein bisschen JS um die Werte in den <body> zu bekommen...
mehr sollte es eigentlich erstmal nicht sein.
Meine "Wetterstation" schreibt nur alle 6 Minuten neue Werte in die CSV
Datei und löscht immer den ersten Eintrag. Damit hab ich immer 240 Werte
(Reihen) in der Datei die einen ganzen Tag darstellen. Mehr wird es
nicht und Datenbanken halte ich dafür zu viel des Guten :)
Mein Vorschlag wäre folgendes kleines pythonscript das einfach
regelmäßig die csv Datei parst und den letzten wert in eine statische
html Seite verwandelt. dazu muss allerdings das jinja2 module via pip
auf den rasperypi installiert werden und deine csv mit einer headline
versehen werden.
Imonbln schrieb:> Der Vorteil von den ansatz ist, dass dein Webserver immer nur eine> Statische Datei ausliefern muss.
Der Nachteil ist das immer die ganze Seite neu geladen werden muss. Ich
hätte es dann doch ganz gerne dynamisch auf einzelne HTML-Elemente :)
Das wird dann später wichtig wenn ich ein "One pager" baue wo dann unter
den Sensoranzeigen noch ein Plot oder der Regenradar zu finden ist. Das
würde mich stören wenn ich gerade den Plot bestaune und plötzlich lädt
die ganze Seite neu...
die Lösung dafür wurde hier doch schon genannt:
Beitrag "Re: Messwerte auf localer Webseite einbinden?"
Websockets wären auch eine moderne Möglichkeit, da kann der Server die
Werte aktiv liefern und ein Stück JS im Client macht das Update der
Controls im Browser.
Ich hatte sowas änliches mal mit server-sent events[1] gemacht.
Im Server kann man einfach ein simples CGI Script platzieren. Ich hab es
gerade nicht mehr vor mir, aber es müsste ungefähr so ausgesehen haben:
1
#!/bin/sh
2
3
echo"Cache-Control: no-cache"
4
echo"Content-Type: text/event-stream"
5
echo
6
7
tail-n1-Fmein_csv.csv|sed's/.*/data:\0\n/'
Und schon bekommt man neue Zeilen sofort mit. JS Seitig ist es auch
Simpel:
Paul G. schrieb:> Und was genau spricht jetzt gegen meine Lösung via csv Parser "Papa> parser"?
Eigentlich nichts, nur das die Webwelt vielleicht lieber mit JSON als
Datenformat arbeitet.
Ich hatte deine Lösung etwas übersehen, und dann ging es wieder um eine
statische Seite. Aber die Aufteilung in statischen Teil und angeforderte
Daten hast du mit dem csv parsen ja gemacht.
Paul G. schrieb:> Meine "Wetterstation" schreibt nur alle 6 Minuten neue Werte in die CSV> Datei und löscht immer den ersten Eintrag. Damit hab ich immer 240 Werte> (Reihen) in der Datei die einen ganzen Tag darstellen. Mehr wird es> nicht und Datenbanken halte ich dafür zu viel des Guten :)
Ja, da hast Du natürlich Recht, für eine so überschaubare Datenmenge
braucht es keine großen Analysewerkzeuge und natürlich auch kein
hochentwickeltes Datenbank-Backend, insofern wünsche ich Dir auch
weiterhin viel Spaß und Erfolg!
Solltest Du allerdings früher oder später größere Datenmengen
verarbeiten und darauf womöglich auch noch verschiedene Operationen
ausführen und vielleicht professionelle interaktive Visualisierungen
erzeugen wollen, möchte ich Dir wärmstens die Werkzeuge Pandas [1] und
Bokeh [2] aus dem Python-Universum ans Herz legen.
Pandas ist eine Bibliothek für Python zur Analyse von Daten, viele
Profis sagen, es sei dafür DIE Standard-Python-Bibliothek schlechthin.
Es basiert auf dem bekannten numpy und bietet auch eine starke
Integration für die Visualisierungsbibliothek matplotlib; große Teile
dieser Bibliotheken sind in C und / oder C++ geschrieben und zum Teil
nutzt insbesondere numpy sogar denselben Fortran-Code wie andere
Werkzeuge aus diesem Umfeld, wie MATLAB und R.
Bokeh dagegen ist eine Bibliothek zur interaktiven Datenvisualisierung
im Web und kann seine Daten nicht nur aus einfachen Python-Listen,
sondern auch aus numpy-Arrays und Pandas-Series beziehen. Die erzeugten
Visualisierungen können sowohl als statische HTML-Dateien, als auch
dynamisch erzeugt und natürlich in Infrastrukturen wie Django oder Flask
eingebettet werden. Aber Deinen Anwendungsfall, das Erzeugen einer
statischen HTML-Seite aus eingelesenen Daten, deckt Bokeh bereits mit
seinem ersten Skript im "Quickstart" ab, siehe [3] direkt unter "Getting
Started".
Wenn dies Dein einziges Projekt dieser Art ist und es vorraussichtlich
auch bleiben wird, lohnt es sich für Dich aber natürlich nicht, neue
Programmiersprache oder gar professionelle Datenanalyse- und
Visualisierungsbibliotheken zu erlernen. Aber wenn Du sowas in Zukunft
vielleicht öfter machen möchtest...?
[1] https://pandas.pydata.org/
[2] https://docs.bokeh.org/en/latest/
[3] https://docs.bokeh.org/en/latest/docs/user_guide/quickstart.html
Paul G. schrieb:> Und was genau spricht jetzt gegen meine Lösung via csv Parser "Papa> parser"?
Solange Deine Anforderungen so bleiben, wie sie sind: nichts. Aber wenn
Du etwa die Daten ordentlich plotten willst, etwa mit JqPlot, Flot,
JqWidgets oder eben mit dem eben bereits erwähnten Bokeh, wird das
irgendwann ziemlich ressourcenaufwändig und somit leider auch ziemlich
langsam.
Aber bitte, laß' Dich nicht verrückt machen, für jetzt ist Deine Lösung
super, auch wenn Du 240 Zeilen CSV-Datei parst, um am Ende nochmal über
alle zu iterieren und letztlich dann doch nur den letzten Datensatz zu
verwenden und obwohl Du das sogar regelmäßig (nämlich mit automatischen
Reloads) machen möchtest... ;-)
Johannes S. schrieb:> Ich hatte deine Lösung etwas übersehen, und dann ging es wieder um eine> statische Seite. Aber die Aufteilung in statischen Teil und angeforderte> Daten hast du mit dem csv parsen ja gemacht.
Naja, so eine statische HTML-Seite kann man ja ausliefern, und die zieht
sich ihre Daten dann über AJAX und kann Drittquellen -- der TO hat den
Regenradar genannt -- mittels einfacher externer Links (CSP nicht
vergessen!) einbinden.
Aaaaber: CSV-Dateien mit JavaScript zu parsen, ist vermutlich ein
ziemlicher Aufwand, und spätestens, wenn man sie zum Plotten umformen
und womöglich sogar eindampfen mag, könnte das sehr schnell sehr
aufwändig werden. Ob es nicht einfacher wäre, bereits in diesem Stadium
des Projekts eine dynamische Seite auf einem Webserver einzurichten,
oder (für eine rein interne Seite!) mit einem Framework wie Flask oder
Django sogar ausnahmsweise deren eingebettete Webserver zu nutzen,
stelle ich mal dahin, denn das hängt natürlich primär davon ab, wie sich
die Anforderungen des TO im Laufe der Zeit entwickeln -- was womöglich
sogar er bisher nur sehr rudimentär sagen kann. ;-)
Naja, nicht jeder will Admin einer MegaEDV werden oder wissen wollen wie
die Temperatur vor 15 Jahren im Keller war. Die Erben formatieren die
Datenplatte sowieso neu und hauen ein Ballerspiel drauf.
Johannes S. schrieb:> Naja, nicht jeder will Admin einer MegaEDV werden oder wissen wollen wie> die Temperatur vor 15 Jahren im Keller war.
Das stimmt, aber ich habe doch weder Hadoop noch Spark, Storm, Heron
oder Gearpump vorgeschlagen, nicht Postgres-XL oder... "MegaEDV"? Im
Ernst? ;-)
Tatsache ist: mit seinem bisherigen Ansatz wird der TO wahrscheinlich
früher oder später auf die Nase fallen, wenn seine Anforderungen größer
werden. Das ist nicht schlimm, Anforderungen ändern sich nunmal. Dann
muß man seine Lösung anpassen und wahlweise erweitern oder neuschreiben
-- ja, auch das kommt vor.
Nach meiner Erfahrung ist es dabei leider meistens so, daß eine
Neuimplementierung viele Entwickler massiv abschreckt, weil sie noch im
Hinterkopf haben, welch große Arbeit die Erstimplementierung war. Häufig
wird sich solange möglich an den ersten Festlegungen gehalten, um die
grundsätzlichen Probleme nicht lösen zu müssen...
Stattdessen wird dann oft um die Designprobleme, die fehlenden
Funktionen und die Fehler herum entwickelt, bis das Projekt zu einem
unwartbaren Chaos wird, und dem Entwickler beim nächsten Upgrade von
Betriebssystem, Bibliotheken, Compiler, Data Store oder Bibliotheken um
die Ohren fliegt.
Dann wird häufig ein wachsender Aufwand betrieben, um die vorhandene
Software auf aktuelleren Plattformen zu betreiben. Nur deswegen
beschäftigen viele Unternehmen immer noch Fortran-, Cobol- und
Smalltalk-Entwickler, und versteh' mich nun bitte nicht falsch: bei
denen mit ihrer riesigen Codebasis kann das ökonomisch durchaus sinnvoll
sein -- was dann aber oft auch noch andere Gründe hat...
Wie auch immer, können wir Deine und meine Lösungen ja mal vor dem
Hintergrund nebeneinander halten, was passiert, wenn die Anforderungen
des TO wachsen.
Du schlägst ein Framework namens IoBroker vor, das auf auf Javasript und
Node.js basiert. Das ist sicher eine großartige Software und natürlich
OpenSouce, so daß unser TO fehlende Funktionalitäten selbst nachrüsten
könnte. Zudem beherrscht er offentlichtlich schon die Programmiersprache
JavaScript, insofern ist Deine Idee zweifellos sinnvoll und nützlich --
natürlich vor allem für ein Projekt, das im Wesentlichen aufs Web
abzielt.
Andererseits gibt es jedoch auch Gründe dafür, warum Python die
beliebteste Sprache der Welt und insbesondere auch in der
DataScience-Community so beliebt ist, und der wesentliche Faktor dafür
sind seine Einfachheit und seine Infrastruktur. Und, klar, die riesige
Menge an millionenfach getestetem Code und sehr guter Dokumentation.
Aber eine "MegaEDV"? Im Ernst? Ist es wirklich so ein großer
Unterschied, ob ein Entwickler "npm install" oder "pip install" aufrufen
muß? Ich glaub nicht, lasse mich aber immer gerne eines Besseren
belehren. Wohlan! ;-)
Sheeva P. schrieb:> Tatsache ist: mit seinem bisherigen Ansatz wird der TO wahrscheinlich> früher oder später auf die Nase fallen, wenn seine Anforderungen größer> werden.
Das sehe ich etwas anders :) Die Wetterstation ist so wie sie ist schon
5 Jahre im Einsatz: 6 Sensoren, 240 Messwerte am Tag (nicht
archivierend, als Ringbuffer sozusagen). Daran wird sich vermutlich auch
in den nächsten 6 Jahren nix ändern. Gut, evtl. kommt hier und da noch
ein Geigerzähler oder CO Sensor dazu aber mehr wirds nicht werden.
Sheeva P. schrieb:> Aaaaber: CSV-Dateien mit JavaScript zu parsen, ist vermutlich ein> ziemlicher Aufwand, und spätestens, wenn man sie zum Plotten umformen
Warum, man braucht doch nur "Papa parse" und c3.js, wo genau ist da
jetzt der Aufwand?
https://www.youtube.com/watch?v=1OK4TJfCzdY
Sheeva P. schrieb:> Aber eine "MegaEDV"? Im Ernst?
Das ist natürlich eine Frage wie weit man sich schon mit Servern,
Datenbanken, Progammiersprachen und Frameworks für Datenanalyse
auseinandergesetzt hat und ob man das in Zukunft braucht oder möchte.
Dagegen steht das parsen einer einfachen csv Datei die aus Sensordaten
selbst generiert wurde.
Das parsen der 240 Zeilen in JS wird ein paar ms dauern, da braucht nix
optimiert werden. Mit der Funktionalität von NodeJS bekommt man das auch
ohne Papa Libs hin, aber egal.
Und ioBroker und Datenanalyse Tools sind zwei sehr verschiedene Dinge,
aber die schliessen sich sogar nicht einmal aus. Der Broker ist, wie der
Name schon sagt, nur ein Vermittler. Der kümmert sich nur darum die
Daten aus verschiedensten Quellen abzugreifen und vereinheitlicht
anderen Interessenten zur Verfügung zu stellen. Die Daten können vom
lokalen Sensor kommen, aus einem Standard Bussystem oder aus dem
Abfallkalender, Wetterdienst oder Spritpreise vom Tankerkönig, alles
möglich. Die 'Anderen' die was mit Daten machen kann die Visu sein, die
per Editor generierte Webseiten darstellt, das kann Logik in JS /
NodeRed / Szenensteuerung sein, das können Datenbankmodule sein oder
eben Numbercruncher die aus den Daten den Sinn des Lebens berechnen.
Alles nur eine Frage ob man das möchte. Ich habe Spaß daran und sammele
nicht nur Daten sondern steuere auch Dinge damit, anderen reicht der
Klimatrend der letzten 24 h. Kostet trotzdem Zeit für Pflege und
Einarbeitung.
Paul G. schrieb:> Sheeva P. schrieb:>> Tatsache ist: mit seinem bisherigen Ansatz wird der TO wahrscheinlich>> früher oder später auf die Nase fallen, wenn seine Anforderungen größer>> werden.>> Das sehe ich etwas anders :)
Letztendlich kannst das natürlich nur Du sagen, wenngleich vermutlich
auch nur mit einer begrenzten Sicherheit. "Prognosen sind schwierig, vor
allem wenn sie die Zukunft betreffen". Auch mir ist es -- wie vermutlich
vielen anderen hier auch -- schon viele Male passiert, daß sich während
eines Projekts neue Ideen und damit natürlich auch neue Anforderungen
ergeben haben -- nicht nur, aber auch bei meinen eigenen Projekten.
> Die Wetterstation ist so wie sie ist schon> 5 Jahre im Einsatz: 6 Sensoren, 240 Messwerte am Tag (nicht> archivierend, als Ringbuffer sozusagen). Daran wird sich vermutlich auch> in den nächsten 6 Jahren nix ändern. Gut, evtl. kommt hier und da noch> ein Geigerzähler oder CO Sensor dazu aber mehr wirds nicht werden.
Nunja, alleine Deine Anfrage hier ist ja ein gutes Beispiel dafür, wie
sich die Ideen und Anforderungen eines Projekts im Laufe der Zeit
verändern können. Und sofern Du vielleicht irgendwann mal
Langzeitbetrachtungen machen willst, kann es möglicherweise sinnvoll
sein, Dir jetzt schon eine passende Basis für so etwas aufzubauen. Dies
insbesondere dann, wenn Du nicht nur in diesem Projekt, sondern auch in
anderen privaten oder beruflichen Tätigkeiten mit der Analyse und / oder
Visualisierung von Daten zu tun hast oder künftig haben wirst. Das
kannst nur Du anhand Deiner aktuellen und anhand Deiner persönlichen
Annahmen über die künftige Situation entscheiden.
> Sheeva P. schrieb:>> Aaaaber: CSV-Dateien mit JavaScript zu parsen, ist vermutlich ein>> ziemlicher Aufwand, und spätestens, wenn man sie zum Plotten umformen>> Warum, man braucht doch nur "Papa parse" und c3.js, wo genau ist da> jetzt der Aufwand?
Oh, bitte entschuldige, daß ich nicht darauf hingewiesen habe, ich meine
hier nicht den Programmier-, sondern den Ressourcenaufwand. JavaScript
ist leider nicht gerade für einen sparsamen Speicherverbrauch oder eine
übermäßige Performance bekannt, und in verschiedenen Tests habe ich
bisher auch keine JS-Engine gefunden, die keine erheblichen Memoryleaks
hatte.
Drahtverhau schrieb:> Warum nicht einfach Blazor nehmen u d die Daten per Entity Framework> speichern? Da gibt's auch alle möglichen Chartelemente schon fertig
Ja, oder den ELK-Stack aus Elasticsearch, Logstash und Kibana... leider
reichen die Ressourcen eines RaspberryPi 3 für den Betrieb dieser
Software nicht ganz aus.