Wie viele andere sicher auch, war ich schon immer mal neugierig, wie die
SMART Attribute einer defekten Platte aussehen. Jetzt ist es passiert:
am Donnerstag ist eine Platte aus meinem RAID ausgestiegen.
Heute habe ich sie ausgetauscht und examiniere nun die (noch warme :)
Festplatten-Leiche. Und so, meine Damen und Herren, meldet sich eine
tote Platte:
Ausschlaggebend war also die Anzahl der reallokierten Sektoren (nach
einem Defekt). OK, nach 45948 Stunden, entsprechend 5 Jahren und 3
Monaten, kann das schon mal passieren.
Das syslog ist auch ganz aufschlußreich:
Axel S. schrieb:> Wie viele andere sicher auch, war ich schon immer mal neugierig, wie die> SMART Attribute einer defekten Platte aussehen.
Der Zähler eines der Pre-Fail-Felder sinkt sinkt unter den bei Threshold
angegeben Wert. Das ist nicht direkt geheim – hätte ich bei meinen
bisherigen gestorbenen Platten auch einen Thread aufmachen sollen? ;)
Hat die Platte denn schon mal Warungen gebracht, bevor sie gestorben
ist? bzw. hast du die SMART Werte schon früher mal ausgelesen, das das
sozusagen Tod mit Ansage war?
Die reallocated Sektors lassen darauf schließen. Und die Spin up Time
sieht auch komisch aus.
Bei einem RAID 5 isses ja nicht so wilde, nach einem Rebuild mit neuer
Platte ist alles wieder schicky. Guck dir die SMART Werte der anderen
Platten an, nicht das es dort auch schon "bröselt". Ganz blöd wäre, wenn
noch wärend des Rebuild die nächste Platte leise Servus sagt.
Gerald B. schrieb:> Hat die Platte denn schon mal Warungen gebracht, bevor sie gestorben> ist? bzw. hast du die SMART Werte schon früher mal ausgelesen, das das> sozusagen Tod mit Ansage war?
Die Warnungen im syslog halt. Und bis eben war ich der Meinung, daß
smartd die Platten auch monitored. Habe aber gerade gesehen, daß ich das
mal auskommentiert habe, um die Selbsttests nicht zu machen. Dabei hätte
es ja gereicht, die -s Option auszukommentieren. Habe das jetzt mal
geändert.
> die Spin up Time sieht auch komisch aus.
Nö, das ist normal. Da ist auch noch viel Luft. Die Platte ist nach
einem Powercycle ja auch wieder angelaufen. Aber wie gesagt: einen SMART
Status FAILED habe ich noch nicht gesehen. Oder ein Attribut, das Fail:
NOW sagt. Bisher sind Platten immer gleich komplett ausgefallen. Und ich
habe schon viele Platten beerdigt.
> Bei einem RAID 5 isses ja nicht so wilde
Es ist sogar ein RAID6. Eine Platte dürfte noch :)
> Guck dir die SMART Werte der anderen Platten an, nicht das> es dort auch schon "bröselt". Ganz blöd wäre, wenn> noch wärend des Rebuild die nächste Platte leise Servus sagt.
Schon gemacht. Alles schick.
Hallo Axel,
ich bin ein Mitleiender. Habe die gleiche HDD - Siehe mein Tread aus ca.
März und April '21.
Wenn Du diese HDD verhöckern möchtest, ich hätte Interesse, um ggfls die
Controller zu tauschen..
Thomas S. schrieb:>> ich bin ein Mitleiender. Habe die gleiche HDD - Siehe mein Tread aus ca.> März und April '21.
Ich leide nicht. Gerade deswegen liegen die Daten ja auf einem RAID,
weil eine Einzelplatte halt immer mal kaputt gehen kann. Ob man sonst
genug Vorwarnzeit hat, um die Daten zu retten, steht in den Sternen. Man
muß ja auch erst mal den Speicherplatz dafür haben. In den meisten
Fällen wird es auf eine Ersatzplatte hinauslaufen und die hätte ich
frühestens 18 Stunden nach der Warnung gehabt.
Nach über 5 Jahren darf eine Festplatte auch mal die Hufe hochreißen.
Die Garantie endet auch für gewerbliche Nutzung nach 5 Jahren. Und dann
fliegen die Platten auch gnadenlos raus. In meinem Fall war die Garantie
seit 2 Jahren abgelaufen. Sonst hätte ich die Platte auch per RMA
getauscht. Mit einem Frühausfall (aus exakt diesem RAID) habe ich das
gemacht.
Tatsächlich sollte ich mir überlegen, ob ich dieses RAID nicht auch neu
(auf neuer Hardware) aufbauen will. Die Maschine selber ist ja auch 5½
Jahre alt (Netzteil, Mainboard, Prozessor). Allerdings habe ich heute
reingeschaut und bis auf ein bißchen Staub auf dem CPU-Kühler (das sich
wegpusten ließ) war nichts ungewöhnlich.
Alle vorherigen RAIDs haben nach einer Weile sämtliche Platten auf
Garantie getauscht bekommen (fast alles WD). Wenn dann die erste Platte
ohne gültigen Garantievertrag gekommen ist, war das eigentlich immer das
Signal, den Rechner und das RAID zu erneuern.
> Wenn Du diese HDD verhöckern möchtest, ich hätte Interesse, um ggfls die> Controller zu tauschen..
Gegen Portoerstattung kannst du die gern haben. Ist wie gesagt Teil
eines RAID6, das wiederum Backend eines LUKS Containers ist. Das
Überschreiben mit Nullen läuft auch gerade. Deswegen habe ich kein
Problem damit, die einem Unbekannten auszuhändigen.
Melde dich an und schreib mir eine PN.
Hallo,
Axel S. schrieb:> Ich leide nicht. Gerade deswegen liegen die Daten ja auf einem RAID,> weil eine Einzelplatte halt immer mal kaputt gehen kann. Ob man sonst> genug Vorwarnzeit hat, um die Daten zu retten, steht in den Sternen.
Raid (Mirror o.ä.) sichert die Verfügbarkeit bei Plattenausfall.
Raid ist kein Backup, wenn es das Dateisystem eines Raid mal richtig
zerlegt, hast Du auch nur noch intakte Platten mit Schrottdaten...
Gruß aus Berlin
Michael
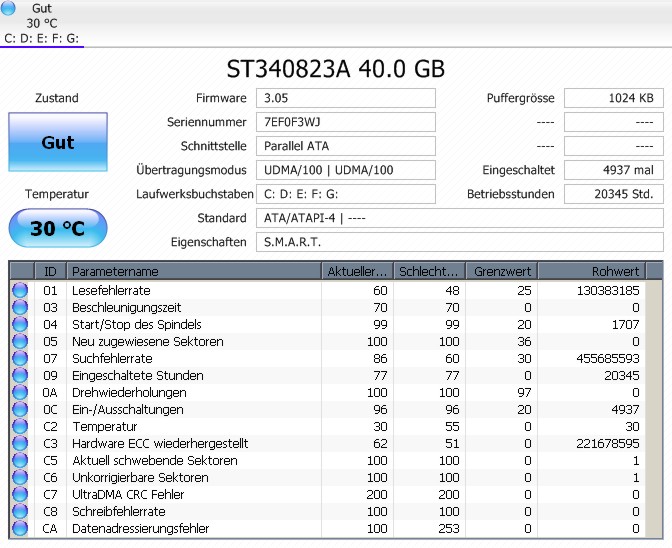
Axel S. schrieb:> 5 Reallocated_Sector_Ct PO--CK 133 133 140 NOW 1955
Das heißt nur, SMART gibt keine Neuzugewiesenen Sektoren mehr aus, nicht
daß die Sektoren defekt sind !
> Ausschlaggebend war also die Anzahl der reallokierten Sektoren
Warum ? Da sind hunderttausende Sektoren, nicht bloß 63.
Die Fehlerursache ist :
> *I/O error*
Controller defekt, einzelner Lesekopf defekt, Lesekopfmechanik defekt,
Spindelmotor defekt ..
Der HDD-controller kann -nun- nicht mehr mit dem Controller der
Festplatte kommunizieren . Die Festplatte wird daher ex-kommuniziert .
Man darf diese Angaben nicht besonders ernst nehmen, da es sich nur um
einen Wert handelt, der oft nur vom Hersteller entschlüsselt werden
kann. Ich hatte mal bei ama eine HDD gekauft, die hatte bereits (mehrere
Tausend?) Stunden am Buckel ! Als ich reklamierte, find ich den Zettel
mit dem Wert nicht, hing die Platte wieder rein und finde gleichzeitig
den Zettel: plötzlich schon wieder einige Stunden mehr !
Sind tatsächlich Minuten gewesen .
Mir persönlich gefällt CrystalDisk deutlich besser als Linux, da kann
man sich noch was vorstellen drunter .
Wie gesagt: WAS AUCH IMMER das Dargestellte heißen mag
Rudi Ratlos schrieb:> Man darf diese Angaben nicht besonders ernst nehmen, da es sich nur um> einen Wert handelt, der oft nur vom Hersteller entschlüsselt werden> kann.
Oh je – der Ratlose wieder. Wenn das Device in der Datenbank ist, dann
entsprechen die interpretierten Werte und die Schwellen den Vorgaben des
Herstellers. Erkennbar ist das an folgender Zeile in smartctls Ausgabe:
1
Device is: In smartctl database [for details use: -P show]
Demgemäß erzählst du mal wieder Stuss. Warum erzählst du mal wieder
Stuss?
Rudi Ratlos schrieb:> Mir persönlich gefällt CrystalDisk deutlich besser als Linux, da kann> man sich noch was vorstellen drunter .
Da stehen exakt die gleichen Sachen, wie in der Ausgabe von smartctl
(ein Programm, das unter Linux läuft, aber nicht Linux ist), nur in
anderer Farbgebung … m(
Rudi Ratlos schrieb:> Axel S. schrieb:>> 5 Reallocated_Sector_Ct PO--CK 133 133 140 NOW 1955> Das heißt nur, SMART gibt keine Neuzugewiesenen Sektoren mehr aus, nicht> daß die Sektoren defekt sind !>>> Ausschlaggebend war also die Anzahl der reallokierten Sektoren> Warum ?
Ja. Warum wohl steht in der "FAIL" Spalte ausgerechnet bei diesem SMART
Attribut "NOW". Rätsel über Rätsel!
> Die Fehlerursache ist :>> *I/O error*>> Controller defekt, einzelner Lesekopf defekt, Lesekopfmechanik defekt,> Spindelmotor defekt ..> Der HDD-controller kann -nun- nicht mehr mit dem Controller der> Festplatte kommunizieren . Die Festplatte wird daher ex-kommuniziert .
Du machst deinem Namen alle Ehre.
Ich frage mich nur, warum ich diese Festplatte dann an meinem Desktop-
Rechner (in einer USB3-SATA Bay) in Betrieb nehmen und obige Werte
erhalten konnte? Wieso ließ sich die Platte trotzdem noch lesen und
schreiben? Schreiben ging zwar vergleichsweise langsam mit nur 10MB/s
aber ich konnte problemlos größere Bereiche der Platte (vor allen den
Bereich mit Metadaten von LUKS) ausnullen.
Merkst du was? Du laberst Unsinn. Die Platte konnte einen Schreibvorgang
( blk_update_request ) nicht durchführen. Sie reportet einen Medium
Error (gemeint ist das Speicher Medium). Und anschließend auch noch,
das die Reallokation eines Ersatzsektors fehlgeschlagen ist.
michael_ schrieb:> Axel S. schrieb:>> Device Model: WDC WD60EFRX-68L0BN1>> Natürlich hat die einen Treffer.
"Natürlich"? Weil sie nach über 5 Jahren ausgefallen ist? Weil 4 ihrer 5
Schwestern noch klaglos ihren Dienst tun?
Oder was nennst du natürlich?
> Aber lass da mal WD Life Guard drüber laufen.
Das läuft nicht unter Betriebssystemen. Nur WinDOS. Irnksoein Bootloader
für Daddelkinder. Habichnicht.
Axel S. schrieb:>>> 5 Reallocated_Sector_Ct PO--CK 133 133 140 NOW 1955> Ja. Warum wohl steht in der "FAIL" Spalte ausgerechnet bei diesem SMART> Attribut "NOW". Rätsel über Rätsel!
Schau, erklär mir mal die Bedeutungen dieser kryptischen Zeichen:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
4 Start_Stop_Count -O--CK 100 100 000 - 10
5 Reallocated_Sector_Ct PO--CK 133 133 140 NOW 1955
9 Power_On_Hours -O--CK 038 038 000 - 45948
Angeblich hättest du diese Platte bei *46.000 Betriebsstunden* -BLOSS-
10 mal gestartet ? Und der "Grenzwert" wäre aber 100 mal starten gewesen
? Und in welcher EINHEIT wird raw_value ausgegeben?
>>> Die Fehlerursache ist :>>> *I/O error*> Ich frage mich nur, warum ich diese Festplatte dann an meinem Desktop-> Rechner (in einer USB3-SATA Bay) in Betrieb nehmen und obige Werte> erhalten konnte? Wieso ließ sich die Platte trotzdem noch lesen und> schreiben?
Weil das meist der Anfang vom schnellen Ende ist.
Die Platte hatte bereits einen *I/O error* . Diese/r werden nun
häufiger. Die Platte beginnt zu spinnen: Sie schreibt, aber es is nix
drauf. Sie versucht zu lesen, aber findet nix. Irgendwann klackert
sie... dasEnde .
Liest du das regelmäßig ein ?
Schreibst ja selber: "Sie reportet.. dies und das.. und Schreibfehler"
und nur 10MB/s und bald? Lesefehler .
Jack V. schrieb:> (ein Programm, das unter Linux läuft, aber nicht Linux ist)
Mei, bist du heit gscheit! Hast am Morgen wieder
Haferschleim-Intelligenz gelöffelt .. Bua, Bua .
User Capacity: 6,001,175,126,016 bytes [6.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
5 Reallocated_Sector_Ct PO--CK 133 133 140 NOW 1955
Unfaßbar viele defekte Sektoren? Alles klar.
Rudi Ratlos schrieb:> Schau, erklär mir mal die Bedeutungen dieser kryptischen Zeichen
Die Flags? Die Bedeutung steht doch in der Ausgabe selbst:
1
||||||_ K auto-keep
2
|||||__ C event count
3
||||___ R error rate
4
|||____ S speed/performance
5
||_____ O updated online
6
|______ P prefailure warning
Rudi Ratlos schrieb:> Und in welcher EINHEIT wird raw_value ausgegeben?
Was meinst du, was „raw“ bedeuten könnte? Hint: dict.cc
Rudi Ratlos schrieb:> Unfaßbar viele defekte Sektoren?
Der Hersteller hat die Schwelle auf interpretiert 140 gesetzt, das
Laufwerk ist mit 133 darunter. Wenn du meinst, der Hersteller wär’ zu
blöde, dann geh’ hin und erkläre dem, wie es richtig geht.
Rudi Ratlos schrieb:> Angeblich hättest du diese Platte bei *46.000 Betriebsstunden* -BLOSS-> 10 mal gestartet ?
Ja – und? Gibt Platten, die starten nur genau einmal in ihrem Leben:
wenn der Server nach dem Einbau hochgefahren wird.
Rudi Ratlos schrieb:> Und der "Grenzwert" wäre aber 100 mal starten gewesen> ?
Nein. Der Grenzwert ist interpretiert Null. Wenn du auf dict.cc wegen
„raw“ nachschaust, so gucke doch am besten auch gleich, was „threshold“
bedeuten könnte, und überlege, wofür das Feld wohl stehen mag.
OT:
Rudi Ratlos schrieb:> Hast am Morgen wieder> Haferschleim-Intelligenz gelöffelt
Besser, als gar keine Intelligenz. Sonst würd’s mir ja wie dir gehen.
Wobei – es heißt ja: „Mit dem Doofsein ist es, wie mit dem Totsein – man
selbst bekommt gar nichts davon mit. Es ist nur unheimlich schwer für
das Umfeld“. Erzähl mal, wie ist das so: merkt man tatsächlich nix
davon, wenn man so abgrundtief blöde ist?
Jack V. schrieb:> Was meinst du, was „raw“ bedeuten könnte?
Was meinst du? Hex, Dez, Okt, Bin, Dec-1byte, Dec-2byte,
Guck´ma mal wer da spricht
> Der Hersteller hat die Schwelle auf interpretiert 140 gesetzt,
Also bei *1.465.130.646 Sektoren* hat er die 'Schwelle' auf 140?
gesetzt.
oder -logischen- 12 GigaSektoren .
So ein Glump kann man niemand empfehlen .
> Ja – und? Gibt Platten, die starten nur genau einmal in ihrem Leben:
beim Werkstest. Oder wenn der Strom 46.000 Stunden nicht ausfällt !
> Erzähl mal, wie ist das so: merkt man tatsächlich nix> davon, wenn man so abgrundtief blöde ist?
Nein.
Für den TO hab ich noch eine defekte INTENSO-TOP 128gb SSD:
mit 33 Stunden - 209 Starts
funktioniert sonst ganz 'normal' ; schreibt alles, stundenlang,
aber nachher is nix drauf
und zum Vergleich einen nagelneuen Ersatz .
Rudi Ratlos schrieb:> Axel S. schrieb:>>> Ja. Warum wohl steht in der "FAIL" Spalte ausgerechnet bei diesem SMART>> Attribut "NOW". Rätsel über Rätsel!>> Schau, erklär mir mal die Bedeutungen dieser kryptischen Zeichen:> ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE> 4 Start_Stop_Count -O--CK 100 100 000 - 10> 5 Reallocated_Sector_Ct PO--CK 133 133 140 NOW 1955> 9 Power_On_Hours -O--CK 038 038 000 - 45948>> Angeblich hättest du diese Platte bei *46.000 Betriebsstunden* -BLOSS-> 10 mal gestartet ?
Ja. Das ist ein Server. Der hatte diesmal eine uptime von 430 Tagen. Das
ist kurz. Ursache war IIRC ein Stromausfall.
> Und der "Grenzwert" wäre aber 100 mal starten gewesen ?
Nein. Die 3 Spalten VALUE, WORST und THRESH (Threshold) können nur Werte
von 0 bis 255 annehmen (ergo: 8 Bit unsigned) und der Hersteller hat ein
Mapping der RAW Werte darauf definiert. Bei diesen Werten gilt: je
höher, desto besser. Bei Unterschreiten von THRESH wird ein SMART Fehler
ausgelöst.
Manche zählen von 100 runter, z.B. die Betriebsstunden. Das kann man
dann als eine Anzeige ansehen, die den noch möglichen Verschleiß in %
angibt. Die Betriebsstunden sind mal bei 100 gestartet, 62 sind schon
weg (38 noch übrig). Die Platte hat also 62% ihrer projektierten
Lebensdauer schon rum. Daraus kann man ausrechnen, daß der Hersteller im
Schnitt von einer Lebensdauer von 75000 Stunden ausgeht.
Andere (z.B. Reallocated_Sector_Ct) starten bei 200 und zählt auch
runter. So sah die Platte übrigens am Anfang aus:
1
Vendor Specific SMART Attributes with Thresholds:
2
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
> Und in welcher EINHEIT wird raw_value ausgegeben?
Herstellerspezifisch. Exakt kann den Wert nur das Herstellertool
angeben. smartctl versucht aber, den Wert bestmöglich zu interpretieren.
Da smartctl aber auch das sagt:
1
Device is: In smartctl database [for details use: -P show]
kann man davon ausgehen, daß die Werte mal mit dem Herstellertool
abgeglichen wurden und zumindest plausibel sind.
Rudi Ratlos schrieb:> Oder wenn der Strom 46.000 Stunden nicht ausfällt !
Von USVs hast du noch nie gehört?
Rudi Ratlos schrieb:> Jack V. schrieb:>> Was meinst du, was „raw“ bedeuten könnte?> Was meinst du?
Dezimale Repräsentation der Werte in den entsprechenden Feldern.
Einheitenlos. Erkennbar, und dokumentiert.
Rudi Ratlos schrieb:>> merkt man tatsächlich nix>> davon, wenn man so abgrundtief blöde ist?> Nein.
Danke für die aufrichtige Antwort – das erklärt Einiges (und leider
auch, warum’s absolut umsonst ist, deinen Stuss richtigstellen zu
wollen). Ich kann dir im Gegenzug versichern: für uns Andere ist es
sehr schwer und sehr traurig, wenn du mal wieder einen Thread mit deinem
mentalen Durchfall bar jeden Realitätsbezugs befallen hast.
Axel S. schrieb:> Herstellerspezifisch. Exakt kann den Wert nur das Herstellertool> smartctl versucht aber, den Wert bestmöglich zu interpretieren.
Du begründest wenigstens, statt zu schimpfen .
Es ist eben nur ein Anhaltspunkt.
Ob eine ständige SMART-kontrolle das plötzliche Versagen voraussagen
kann, bezweifle ich. Auch, ob evtl. 'Datenbanken' ausreichend
aktualisiert werden (bzw.überhaupt können). Letztendlich ist es nur
unleserliches Zeug.
Mir fällt dazu immer nur ein : Selbst HDD-Controller auszutauschen ist
nicht möglich, weil die FW häufig nicht zur 'Hardware' paßt. Warum soll
dann ausgerechnet SMART austauschbar passen ?
Oder um Gretel Dünnberg rechtSMART zu zitieren: bla, bla, bla ..
there is no planet B !
Pardon, du hast ja noch: planet B & C .
> Letztendlich ist es nur unleserliches Zeug.
Das können auch 256 Fehlercodes , Jede Zahl mit eigener Bedeutung ,
sein.
Rudi Ratlos schrieb:> Axel S. schrieb:>> Herstellerspezifisch. Exakt kann den Wert nur das Herstellertool>> smartctl versucht aber, den Wert bestmöglich zu interpretieren.>> Du begründest wenigstens, statt zu schimpfen .
Und du plenkst
> Ob eine ständige SMART-kontrolle das plötzliche Versagen voraussagen> kann, bezweifle ich. Auch, ob evtl. 'Datenbanken' ausreichend> aktualisiert werden (bzw.überhaupt können).
Die "Datenbank" betrifft nur die Abbildung der RAW Werte. Ob also z.B.
eine Temperatur in °C oder in Fahrenheit angegeben wird. Ein Hersteller
bleibt üblicherweise bei einem Schema.
> Letztendlich ist es nur unleserliches Zeug.
Keineswegs. Genau darum gibt es ja die normalisierten Spalten.
> Mir fällt dazu immer nur ein : Selbst HDD-Controller auszutauschen ist> nicht möglich, weil die FW häufig nicht zur 'Hardware' paßt. Warum soll> dann ausgerechnet SMART austauschbar passen ?
Weil dafür eben genau die normierten Spalten geschaffen wurden. Es ist
auch eigentlich egal, ob die Platte nach 2.000 oder nach 10.000
reallokierten Sektoren ausfällt.
PS: und falls das nicht klar war. Wenn du weißt daß
Reallocated_Sector_Ct bei 200 für "fabrikneu" startet und bei 140
"kaputt" sein wird, dann kannst den aktuellen Wert auslesen und in einem
Z.B. Balkendiagramm darstellen. Oder farblich von grün (OK) zu rot
(Kaputt) einfärben. Der RAW-Wert kann dir dafür vollkommen schnuppe
sein. Selbst wenn du weißt, das es 4711 defekte Sektoren gab, mußt du ja
immer noch wiseen, wieviel Reserve die Platte vorhält. Genau davon
abstrahiert SMART. Das ist die eigentliche Leistung.
Axel S. schrieb:> bei 200 für "fabrikneu" startet und bei 140 "kaputt" sein wird,
Das war mir tatsächlich NEU . Und trotzdem ergibts keinen Sinn.
Kannst Du mir sagen , was genau an meiner Intenso-SSD defekt ist ?
Das ist das Problem .
Oder was an meiner Seagate-40gb defekt werden wird ?
nach 20.000 h (=23%) mit 5.000 Starts (=4%) und
einer Suchfehlerrate von 457 Millionen.
In meinem Leben? wohl nie mehr etwas .
Axel S. schrieb:>> Aber lass da mal WD Life Guard drüber laufen.>> Das läuft nicht unter Betriebssystemen. Nur WinDOS. Irnksoein Bootloader> für Daddelkinder. Habichnicht.
Kannst du das mal ins Deutsch übersetzen?
Geh doch mal zu WD um denen zu zeigen, wie man ihre HD analysiert und
repariert.
Rudi Ratlos schrieb:> Axel S. schrieb:>> bei 200 für "fabrikneu" startet und bei 140 "kaputt" sein wird,>> Das war mir tatsächlich NEU . Und trotzdem ergibts keinen Sinn.> Kannst Du mir sagen , was genau an meiner Intenso-SSD defekt ist ?> Das ist das Problem .>
Intenso läßt man im Regal,
da steckt doch jedesmal was anderes drin.
Bei USB Sticks schien das so zu sein ;)
egal,
https://www.mikrocontroller.net/attachment/535436/Intenso_SSD_SATAIII_AA000000000000051472_2021-07-21___2.txt
bzgl. CRC err ct u. retract count könnt auch einfach was mit der
Stromversorgung sein. Wenn noch nicht gemacht Kabel erneuern u. an
anderem REchner Probieren.
>> funktioniert sonst ganz 'normal'
linux;
journalctl -r -p err [ |grep offline]
solche Meldungen sind interessant:
... exception ... frozen
ata5: SError: { PHYRdyChg PHYInt }
ata5.00: revalidation failed (errno=-5)
ata5: COMRESET failed (errno=-16)
ata5: reset failed, giving up
-> rejecting I/O to offline device
Unbemerkt ins nichts verschwindet da eher nichts
Die platte ist dann halt erstmal raus.
Dem Betriebssystem entgeht das nicht.
(Kabel war lose, resultierte in UDMA_CRC_Error_Count -> 25)
>> schreibt alles, stundenlang,>> aber nachher is nix drauf
Einer Anwendung oder dem Anwender selber evtl. schon, das bspw. ein
livestream von einem mediaplayer nicht mehr mitgeschnitten wird, wärend
man guckt. Denkbar jdf.
les die logs.
++++
> Oder was an meiner Seagate-40gb defekt werden wird ?> nach 20.000 h (=23%) mit 5.000 Starts (=4%) und> einer Suchfehlerrate von 457 Millionen.>> In meinem Leben? wohl nie mehr etwas .
So doch eher nicht.
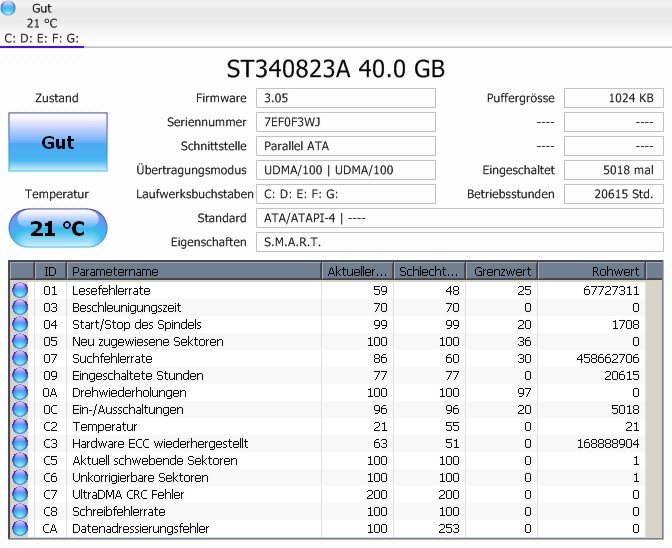
Rudi Ratlos schrieb:> Das obere Bild ist vom 28.August , das hier von heute.
Das hier wurde in einer Textbox geschrieben.
Antwort lieber als Bild?
innerhalb ~74 Tage, 81 mal ein und aus, 270 Betriebsstunden o.k.
Raten und Normalisierte Werte sind nie konstant.
Und von den "Rohwerten" interessieren bestenfalls nur die "Zähler"
von irgendwo oben, ist aber eher keine seagate:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-K 200 200 051 - 0
Die 'Raw_Read_Error_Rate' als Beispiel ist nunmal kein Zähler,
sonst stünde da statt - ein c bei flags
was mag das bei deiner alten konventionellen Seagate bedeuten,
andere machen das eben ggf. anders:
https://t1.daumcdn.net/brunch/service/user/axm/file/zRYOdwPu3OMoKYmBOby1fEEQEbU.pdf
als Beispiel;
Wie und wann es berechnet wird:
Where the factor of 512*8 is to convert from sectors to bits. The attribute value is only
5
computed when the number of bits in the "transferred bits" count is in the range 1010 to 1012.
6
The counts are cleared when Number Of Bits Transferred To Or From Host > 1012.
7
“Number of sectors requiring retries” does not count free retry or hidden retry.
8
Normalized Raw Error Rate is evaluated to a number between 1 and 166.
9
Raw Usage
10
Raw [3 – 0] = Number of sector reads
11
Raw [6 - 4] = Number of read errors.
(sieben Byte, BYTEORDER little-endian ->
"rohwert" gezeigt von smartctl als unsigned base-10 integer)
das sind temporäre Zustände, die sich immer wieder ändern.
Interssant und überflüssig Ignorieren
Das einzige was daran interessiert ist ob der wie auch immer erechnete
normalisierte Wert den Grenzwert falls es einen gibt unterschreitet,
dann wäre jetzt gerade was im Busch und es gibt wenn es vom Typ Pre-fail
ist die ganz oben auch zu sehende Warnung mach was, sichere jetzt!
Und das ist ja auch egal ob das nun auf 100,200,255 gerechnet wird
Manchmal geht das, oft auch nicht.
derzeitiger normalisierter Wert vs. Grenzwert falls es einen geben
sollte, das ist das einzige was wirkich interessiert.
Bspw. Wenn das Kabel abgeht wird sich das im CRC_Error_Count verewigen,
wenn das Problem behoben ist ändert sich aber nichts mehr.
Verlorene Sektoren nach einem "crash" sind halt weg, solange das gleich
bleibt aber recht egal. DIe Platte kann auch noch lange über die
angenomme Betriebsdauer funktionieren, deshalb kein Grenzwert zeigt
einfach an das wenn der Wert auf Null zugeht die antipizierte
Betriebsdauer erreicht ist, ob das Auto weiter gefahren wird ist dir
überlassen. etc. etc.
kristallklarer scheixx:
"ID A0 Drehwiederholung"
Autsch wie wärs mit , Attribut 10: Anlaufversuche
3.7 Attribute ID 10: Spin Retry Count
Normalized Spin Retry Count = 100 – average number of retries in the
last eight spin ups
Raw Usage
No raw values.
schwebende ...
S.M.A.R.T "saugt" so schon genug.
Aber bitte Text und nicht in Bildern die man auch noch suchen muss.
---
zurück auf Anfang:
Drive failure expected in less than 24 hours. SAVE ALL DATA.
besser wirds doch nicht.
5 Reallocated_Sector_Ct PO--CK 133 133 140 NOW 1955
1955*4096 auf ~6TB ist zunächst noch nicht viel
aber das ist ja momentan im steigen begriffen.
und noch geht eben was.
bei ldgl. 40GB wäre evtl. früher schluss.
Was Attribut 5 bei Seagate (oben war WD) bedeuten soll findet sich ua.
in dem angehangen PDF. Prinzip, das gleiche.
Zu deiner ssd such halt wenn du es genauer wissen wolltest ob sich ggf.
unterlagen finden.
Una Meit schrieb:> Zu deiner ssd such halt wenn du es genauer wissen wolltest ob sich ggf.> unterlagen finden.
Das kannst im SMART eben nicht ablesen . Ich habs ja lange ausprobiert,
du kopierst Dateien auf irgendeine Partition, Fortschrittsbalken ...
weg, die Dateien sind alle kopiert worden, man klickt auf ein PDF, das
erscheint ... Man kopiert von dieser Partition nun auf eine andere
Platte, nun sind die Dateien AUCH auf der anderen Platte. Man fährt den
PC runter und rauf - und fort sind die Dateien auf der INTENSO.
Fehler? Ist echt intensiv.
Dasselbe gilt fürs formatieren und partitionieren. Du löscht die
Partition, und im nächsten Moment ist sie weider da.
ama hat sie mir geschenkt. Zum Glück, eines Tages möchte ich sie
'reparieren'.
War nur einer der Gründe, warum ich von SMART nicht mehr gar viel halte.
COUNTER und :wirres Zeug.
> und :wirres Zeug.
.. im für uns sichtbaren Teil.
Ich glaube, daß, wenn eine Platte innerhalb der Garantiezeit ihr Leben
aushaucht, die Servicefirma (wohin die Platte zur Vernichtung geht),
direkt aus dem Platten-Controller den kompletten "Lebenslauf"
minutengenau ausliest und an den Hersteller schickt.
Und der (wirklich uralte) SMART nur eine 'Information für die User' ist.
Rudi Ratlos schrieb:> War nur einer der Gründe, warum ich von SMART nicht mehr gar viel halte.
Der eigentliche Grund ist, dass du’s nicht verstehst. Und damit ist auch
nichts verkehrt. Verkehrt ist nur, etwas beurteilen zu wollen, das man
nicht versteht, um das Resultat dann als Fakt hinzustellen. Vielleicht
solltest du davon mal einfach Abstand nehmen – nicht nur bei diesem
Thema.
Hallo,
bisher hat mir Smart durchuas geholfen den Zustand der Platten
einzuschätzen und auftretende Fehler zuordnen zu können.
reallocated sector count zuerst, wenn RAW da nicht 0 ist, stimmt was
nicht.
Schwebende Sektoren sollte es auch nicht geben, da ist aber schon die
Frage, ob echt oder zeitweise. Diese Sektoren werden beim Lesezugriff
gekennzeichnet. Wenn beim nächsten Schreiben auf den Sektor alle klappt
wird das wieder zurückgesetzt, sonst wird reallociert.
Das kann aber auch selten z.B. durch Stromausfälle o.ä verursacht
werden.
UDA-Fehler sind Übertragungsfehler, auch durch z.B. defekte SATA-Kabel.
Dummerweise werden die nie zurückgesetzt, man müßte sich also den Wert
merken, wenn man da z.B. das SATA-Kabel tauscht.
Betriebsstunden/Start-Stop usw. interessieren mich selten, allerdings
war da die Interpretation der Tools auch durchuas zutreffend.
Bitfehlerraten, Anlauf-/Positionierzeiten sind mir eigentlich egal,
einfach, weil ich die Smartdaten der HDs nicht aufhebe, um das
vergleichen zu können.
Im Moment sind hier fast nur Seagate und WD (teilweise Green) im
Einsatz, hergestellt 2014/2015. Ausfälle nach der Zeit wenig, geschätzt
wohl 10-15%, Einsatz in externen Gehäusen, NAS, Rechner.
Grund zum Nachschauen bei mir ist meist, daß der Zugriff auf einen
Datenträger plötzlich merklich länger dauert als üblich. Das habe ich
recht gut im Gefühl beim Arbeiten, auch ohne Buchführung.
PS: Zu Rudi Ratlos sage ich mal lieber nichts mehr...
Gruß aus Berlin
Michael
Michael U. schrieb:> Grund zum Nachschauen bei mir ist meist, daß der Zugriff auf einen> Datenträger plötzlich merklich länger dauert als üblich.
Also schaust auch erst? wenn etwas defekt ist - oder defekt erscheint.
Und wenn dir dann etwas spanisch erscheint, dann suchst nach einem
Fehler.
In den SATA-Kabeln, der Southbridge ..
> Ausfälle nach der Zeit geschätzt wohl 10-15%,
da brauche ich mit Verlaub -keinen SMART dazu.
Jack V. schrieb:> Der eigentliche Grund ist, dass du’s nicht verstehst. Und damit ist auch> nichts verkehrt. Verkehrt ist nur, etwas beurteilen zu wollen, das man> nicht versteht, um das Resultat dann als Fakt hinzustellen. Vielleicht> solltest du davon mal einfach Abstand nehmen – nicht nur bei diesem> Thema.
Du stellst Deine 'Meinung über mich' auch als FAKT dar.
Weil: du es nicht besser verstehst oder einfach nicht liest .
Denn sonst würdest meine Theorien wohl unschwer widerlegen.
DAS ist ein FAKTUM. Empirisch bewiesen .
Hallo,
Rudi Ratlos schrieb:> Michael U. schrieb:>> Grund zum Nachschauen bei mir ist meist, daß der Zugriff auf einen>> Datenträger plötzlich merklich länger dauert als üblich.>> Also schaust auch erst? wenn etwas defekt ist - oder defekt erscheint.> Und wenn dir dann etwas spanisch erscheint, dann suchst nach einem> Fehler.
Im Gegensatz zu Dir suche ich nicht nach Fehlern wenn der Rechner sich
völlig normal benimmt. Macht er das nicht, dann dann grenze ich eben die
möglichen Ursachen ein, dazu eben auch das Auslesen der Smartwerte.
Bisher hat mich das immer rechtzeitig vorgewarnt.
> In den SATA-Kabeln, der Southbridge ..
Ich war bisher weder in meinen SATA-Kabeln noch in einer Southbridge
drin, ist mir einfach zu eng da drinnen...
Fehler durch Kontaktprobleme bei den Kabeln treten meist nach
irgendwelchen Umbauten im Rechner auf, fast nie im normalen Betrieb nach
Tagen oder Monaten. Im Zusammenhang damit sind plötzlich auftauchende
UDMA-Fehler ein direkter Hinweis das zu überprüfen. Hatte ich den Jahren
einmal bei mir und einmal beim Rechner eines Bekannten.
>> Ausfälle nach der Zeit geschätzt wohl 10-15%,> da brauche ich mit Verlaub -keinen SMART dazu.
Der Unterschied ist: ich habe bisher diese 10-15% HDs immer erkannt und
getauscht BEVOR es irgendeinen Datenverlust gab.
Du merkst das sicher auch ohne Smart-Daten schon daran, daß die Daten
eben plötzlich weg sind. Natürlich kannst Du auch ohne jeden logischen
Zusammenhang wahllos alles mögliche tauschen, irgendwann findest Du
damit auch die Ursache.
Gruß aus Berlin
Michael
Rudi Ratlos schrieb:> Du stellst Deine 'Meinung über mich' auch als FAKT dar.> Weil: du es nicht besser verstehst oder einfach nicht liest .>> Denn sonst würdest meine Theorien wohl unschwer widerlegen.
Ich habe meine Meinung über dich nach zahlreichen Beiträgen von dir,
sowie deinen Reaktionen auf Antworten darauf, auch solchen von mir, in
einem Prozess sorgfältiger Beurteilungen und Abwägungen gebildet. Es
deutet in ca. 97,2% deiner Beiträge einfach nichts darauf hin, dass du
weißt, was du da schreibst. Und je weiter du von den tatsächlichen
Fakten weg bist, desto überzeugter gibst du dich in der Regel.
Im Normalfall quote ich eine falsche Aussage von dir, und stelle sie
richtig – das kann man sehr wohl so interpretieren, dass ich deine teils
abstrusen Darstellungen widerlege, denke ich. Zumindest schaffen es
viele Leute, die nicht du sind – hab ich mir erzählen lassen.
@TE: sorry für das erneute OT, ich werd’ auf den Spinner hier auch nicht
weiter eingehen – versprochen :)
Jack V. schrieb:> dass ich deine teils abstrusen Darstellungen widerlege,
So sans die Preissen . Sie können über den eigenen Tellerrand nicht
hinausblicken. Darum verstehen sie weder den Erfolg von google noch von
amazon. Streng genommen: verstehen sie die Welt nicht mehr !
Das was solche Firmen machen ist in deutschen Augen abstrus !
Die Google-Zentrale besteht nur aus solchen Leuten wie mir. Zuerst muß
man etwas 'denkmöglich' machen bevor man es in die Realität umsetzen.
Hältst DU also jede Behauptung für abstrus, weil sie für DICH
denkunmöglich ist, bist in der heutigen Wirtschaft fehl am Platz.
Darum haben die Amis immer die Nase vorn, und werden sie auch immer vorn
haben. Und die Chinesen werden genauso auf die Schnauze fallen wie die
Europäer. Denn in beiden Regionen sind die "Spinner" :nicht willkommen.
Demnächst eine neue Sendung im ARD: Welche tragende Rolle wird Das Neue
Deutschland in der Welt spielen?
Nach Merkel?: gar keine.
Die letzte Spinnerin verlässt die visionäre Bühne ...
Axel S. schrieb:> In den meisten> Fällen wird es auf eine Ersatzplatte hinauslaufen und die hätte ich> frühestens 18 Stunden nach der Warnung gehabt.
man hat IMMER eine Platte mit genügend Platz zur Datensicherung parat!
alleine auch schon, um die Möglichkeit zu haben,
ein gezogenes Image auch zu testen.
●DesIntegrator ●. schrieb:> Axel S. schrieb:>> In den meisten>> Fällen wird es auf eine Ersatzplatte hinauslaufen und die hätte ich>> frühestens 18 Stunden nach der Warnung gehabt.>
Jo, der `Health Status' wird sich nur selten ändern.
Allenfalls kurz vor Knapp, wirklich mal ansehen was das bedeuten soll.
Und muß ja dann nicht weiter laufen.
>>> und es gibt auch eine Vorgeschichte:>>> # zcat syslog.*.gz | fgrep sdf
also läuft der smart Daemon, man smartd.conf
nur überflogen devicescan -H gepaart mit
-m root -M exec .../shell/script/...
---> z.B. mail absetzen u. platten rausnehmen
umount oder /sbin/shutdown einleiten, hdparm -Y, ...
Das eine Woche später im Log zu lesen bringt ja nichts. ;)
> man hat IMMER eine Platte mit genügend Platz zur Datensicherung parat!>> alleine auch schon, um die Möglichkeit zu haben,> ein gezogenes Image auch zu testen.
Ohne Raid gibt es sicher immer einen Verzug.
Die Kopie hängt immer hinterher.
Zuhause am Einzelrechner nimmt das als seltenes Einzelereignis eben
hin.
●DesIntegrator ●. schrieb:> Axel S. schrieb:>> In den meisten>> Fällen wird es auf eine Ersatzplatte hinauslaufen und die hätte ich>> frühestens 18 Stunden nach der Warnung gehabt.>> man hat IMMER eine Platte mit genügend Platz zur Datensicherung parat!
Ähhm. Nein. Vielleicht, wenn man nur einen Desktop-Rechner mit einem
überschaubaren Bestand hat.
Ich habe derzeit 17 TB im aktiven Datenbestand. Da hätte ich Probleme,
überhaupt ein Medium zu finden, wo das alles drauf paßt. Das ist
selbstverständlich ein RAID. Und statt RAID5 + Spare (Ersatzplatte) habe
ich mich für RAID6 entschieden. Denn sonst ist es ein Va-banque-Spiel
wenn eine Platte ausfällt. Wenn dann nämlich noch eine sagt "ich mag
nicht mehr", dann wars das mit den Daten. Passiert besonders gern beim
Resync.
3 TB von den 17 halte ich für derartig wichtig, das ich davon ein Backup
auf einer anderen Platte habe. Aber den Rest würde ich schon vermissen.
> alleine auch schon, um die Möglichkeit zu haben,> ein gezogenes Image auch zu testen.
Wir leben offensichlich in verschiedenen Welten. "Ein Image ziehen" ...
was soll das sein? Warum würde man das tun wollen und warum braucht man
dafür eine extra Platte?
Axel S. schrieb:> Ich habe derzeit 17 TB im aktiven Datenbestand. Da hätte ich Probleme,> überhaupt ein Medium zu finden, wo das alles drauf paßt.
Das Finden sollte kein Problem sein. Das Bezahlen vielleicht eher:
https://www.youtube.com/watch?v=ZFLiKClKKhs (100TB-SSD Teardown)
Wobei „normale“ Menschen sich da wohl einen Stapel 10TB-HDDs oder gleich
ein ordentliches Bandlaufwerk besorgen würden.
Wenn die 17TB aber wichtig sind, wirst du ja sowieso ein Backup haben
(denn RAID ersetzt sowas bekanntermaßen ja nicht) – insofern ist’s ja
auch nicht so dramatisch, wenn es ein Problem mit dem RAID geben sollte.
Michael U. schrieb:> Im Moment sind hier fast nur Seagate und WD (teilweise Green)
Oh weh ... die Green. Die sind bekannt für Ausfälle.
Aber mal was ich über die Interpretation von SMART-Werten bei Seagate
weiß.
Die Werte kann eigwentlich nur Seagate selbst eruieren. Es gibt Tabbelen
zum Umrechnen der Werte. Ich weiß nicht wie, aber in einem SMART-Wert
mit scheinbarem 'hohen' Werten verbergen sich meines wissens 3 Werte,
die das Ganze wieder halbwegs normal erscheinen lasse.
Deshalb ist es gefährlich hier Seagate-Smart mit WD-Smart zu
vergleichen.
PC-Freak schrieb:> Deshalb ist es gefährlich hier Seagate-Smart mit WD-Smart zu> vergleichen.
weder Äpfel noch Birnen zählen halt zu Gemüse.
Die raw-werte interessieren bei den Angstverbreitenden Attributen
praktisch nicht u. deren default Darstellung als Dezimalzahl verleitet
zudem zu falschen Schlüssen. Die werden auch wiees scheint nur unter
bestimmten Bedingungen und nicht fortlaufenden erfasst und berechnet.
Seagate dient nur als Beispiel,
ist ja nicht mal sicher ob das heute noch stimmt
beiden Laufwerken gehts prächtig,
wd
198 198 051 Pre-fail Always - 24236
vs.
sg
115 099 006 Pre-fail Always - 92660016
der einzige unterschied zwischen den beiden ist das von der wd in
jüngster Vergangenheit keine nennenswerten Datenmengen gelesen wurden.
Vollkommen unabhängig wie das im Details berechnet wird.
92660016
smartcl -A -v 1,hex56 | der spricht ja auch hex
0x0000000585e940
meinetwegen so wenns stimmt, spielt aber keine Rolle
Raw [3 - 0] = Number of sector reads
Raw [6 - 4] = Number of read errors.
aber eben auch nicht absolut sondern
The attribute value is only
.... computed when the number of bits in the "transferred bits" count is
in the range 10^10 to 10^12 The counts are cleared when Number Of Bits
Transferred when Number Of Bits Transferred To Or From Host ......
Erst bei einer bestimmten Übertragungsrate, den Effekt das der Wert
schlagartig sinkt und im leerlauf wieder steigt kann man leicht
beobachten,
smartd u. aufgehobene journale o. syslogs vorrausgesetzt
Z.B. in der Art:
$journalctl -r -u smartd |grep -i read| cut -d ' ' -f 1-3,12-
Nov 13 06:38:52 1 Raw_Read_Error_Rate changed from 114 to 115
Nov 12 19:38:51 1 Raw_Read_Error_Rate changed from 113 to 114
Nov 12 16:38:52 1 Raw_Read_Error_Rate changed from 112 to 113
Nov 12 06:38:52 1 Raw_Read_Error_Rate changed from 107 to 112
Nov 11 23:38:52 1 Raw_Read_Error_Rate changed from 106 to 107
Nov 11 17:08:52 1 Raw_Read_Error_Rate changed from 105 to 106
Nov 11 06:38:52 1 Raw_Read_Error_Rate changed from 103 to 105
Nov 11 04:08:52 1 Raw_Read_Error_Rate changed from 102 to 103
Nov 11 02:08:52 1 Raw_Read_Error_Rate changed from 118 to 102 <-
Nov 10 17:08:52 1 Raw_Read_Error_Rate changed from 117 to 118
Nov 10 15:38:52 1 Raw_Read_Error_Rate changed from 115 to 117
Nov 10 15:08:53 1 Raw_Read_Error_Rate changed from 114 to 115
sinkt der Wert X zu irgendeinem Zeitpunkt unter die Schwelle Y?
(bei dem Exemplar läge der threshold bei 6, pendelt derzeit immer so zw.
99 u. 120, der Tiefstwert wird mit zunehmender Nutzungsdauer immer nach
unten wandern)
Bei der wd liegt er eben bei 51
Das Prinzipsollte für alle gelten.
ganz oben, die defekt gehende
1 Raw_Read_Error_Rate POSR-K 200 200 051 - 2
auch mit Leseschwierigkeiten wird sich recht sicher diese Rate nach
Leerlauf wieder erholen.
solche raw-werte, ignorieren.