Ich habe mich mit drei memcpy Versionen gespielt, und das Timing
mit dem Pentium Time Stamp Counter gemessen.
- Einfache C for schleife
- libc memcpy Funktion
- movsb Assembler Befehl
Die Ergebnisse sind recht überraschend, und interessieren vielleicht
auch
andere.
Der Gewinner ist mit Abstand der einfache Assembler Einzeiler,
zumindest auf einer halbwegs aktuellen CPU.
Der movsb schafft bis zu 24 Bytes / Takt, die for Schleife gerade mal
0.8 Bytes / Takt (sofern nicht die AVX2 Optimierungen angemacht werden).
Mehr Infos zum Timing sind im Anhang.
1
#if SOLUTION == 0
2
3
/* dumb C solution */
4
void*testcpy(void*dst,void*src,size_tlen)
5
{
6
size_tn;
7
BYTE*p=dst;
8
BYTE*r=src;
9
10
for(n=0;n<len;n++)
11
p[n]=r[n];
12
13
returndst;
14
}
15
16
#elif SOLUTION == 1
17
18
/* libc memcpy solution */
19
void*testcpy(void*dst,void*src,size_tlen)
20
{
21
returnmemcpy(dst,src,len);
22
}
23
24
#elif SOLUTION == 2
25
26
/* simple libc independent memcpy based on "rep; movsb". */
Bei Intel gibt es die intrinsics, vielleicht als Tipp:
#include "immintrin.h"
__m256i x = _mm256_loadu_si256((__m256i*) src_address);
_mm256_storeu_si256((__m256i*) tgt_address, x);
Solche Messungen sind sicher interessant, wichtig ist da aber die exakte
Konstellation:
- Ist der Daten-Cache schon mit den zu kopierenden Bytes gefüllt?
- dito für den Code-Cache
- Ist die Menge zu schreibender Daten so klein dass sie komplett in den
Write-Buffer passen?
- Läuft das ganze im L1/L2/L3-Cache
- Laufe ich Single-Core oder blockieren ggf. andere Cores temporär
einzelne Datenpfade.
Heute jedenfalls ist das ganze weit komplizierter als vor 30 Jahren beim
vergleich von z.B. 68k mit i486.
Auf Embedded-Systemen (insbesondere Bare-Metal Code) ist das (noch)
einfacher im Griff zu halten als auf der PC-Platform.
Hier mal meine generellen Hinweis zum Daten-kopieren:
- Nutze die Kopierfunktionen die dir den einfachsten Quellcode geben
- Nutze portable Kopierfunktionen (also.z.B. keine _movsb als
inline-Asm, das kann der Compiler besser, insbesondere auch nach Umstieg
Intel zu Arm)
- Hardcore-Messungen nur dort wo es wirklich kritisch wird
Ansonsten natürlich wenn es dich interessiert, mach es und hab Spaß
dabei :-)
Grüße, Reinhold
Der Asm Code ist natürlich maximal schnell kann aber nicht damit umgehen
wenn sich die Speicherbereiche überlappen, testet nicht das
Richtungsbit, verwendet auch nicht movsw/movsd. Wenn du das alles
einbaust, wird der Unterschied zur lib nicht mehr so gross sein.
Thomas Z. schrieb:> Der Asm Code ist natürlich maximal schnell kann aber nicht damit> umgehen wenn sich die Speicherbereiche überlappen
Das darf bei memcpy ohnehin nicht passieren, weil das undefined
behaviour wäre.
Der Durchsatz von MOVSx kann sich auf verschiedenen Prozessoren
erheblich unterscheiden, und dabei auch erheblich von Randbedingungen
wie Grösse und Alignment abhängen. Nicht durch Caches spielen dabei eine
Rolle. Es kann sein, dass manchmal MOVSx schneller ist, manchmal eine
andere Variante.
Wenn man im eigenen Programme stets den optimalen Durchsatz benötigt,
sollte man beim Start des Programmes ein paar Varianten mit
realistischen Parametern durchmessen.
Thomas Z. schrieb:> Der Asm Code ist natürlich maximal schnell kann aber nicht damit umgehen> wenn sich die Speicherbereiche überlappen,
Kann memcpy() auch nicht. Dafür gibt es memmove(), früher unter BSD auch
noch bcopy(), was mittlerweile deprecated ist.
Ich habe den Source Code mit den compilierten exe Files angehängt.
Wer möchte, kann das gerne selber ausprobieren, und idealerweise
die Ergebnisse hier veröffentlichen.
Wäre sehr interessant, wie die Ergebnisse für AMD oder für ältere
Intel Prozessoren ausschauen.
Im Source Code ist ein Script run.sh, dass alle Programme
ausführt, und ein Log File erzeugt. Ich verwende die Kommandozeile
von www.cygwin.com
(Installieren => Terminal aufmachen => und ./run.sh ausführen).
Ohne Cygwin kann man die einzelnen Programme auch auf der cmd.exe
aufrufen: test_cl_2.exe <bytes> <offset>
Im Source Code Verzeichnis gibt es ein makefile, dass alle
exe baut. Ich habe das unter Win10 mit Cygwin gebaut.
Für den MS cl.exe Compiler muss INCLUDE und LIB auf die Header- und Lib
Verzeichnisse gesetzt werden. Der gcc ist der Mingw, der mit Cygwin
mitkommt.
Im Anhang auch noch ein Update der Grafik. Jetzt auch mit dem
neueren 2019 cl.exe (besser), und mit der Blockgrösse auf der
x-Achse.
cppbert3 schrieb:> -wie sieht denn dein Test-Code aus? (wie viele Testläufe usw.)> -hast du im Assembler-Code nachvollzogen warum das so ist?
Sind 194 Zeilen C Code. Du kannst den im Zip File vom letzten Post
anschauen. Beim Compilieren das Define METHOD=N setzen, N={1-6}.
Ich habe mir den Asm Code teilweise angeschaut.
Gerade der Intel Compiler ist sehr gut darin, alle möglichen
und unmöglichen Anwendungen für die optimierte intel_memcpy zu finden.
Ich schätze mal, dass der neuere Intel Compiler noch besser ist,
gerade was die neueren Prozessorerweiterungen betrifft.
Er ist auch relativ aggressiv beim Loop Unrolling, und beim Inlinen.
Der MS cl.exe ist der vom Driver Development Kit, der älteste Compiler,
aber extrem gutmütig.
Der optimiert zwar nicht besonders super, aber produziert kleine
Binaries ohne Überraschungen.
Der gcc ist inzwischen sehr gut, macht oft besser lesbaren Asm
als der ICL. Der ICL hat aber viel integriertes Wissen,
welche Befehle parallel ausgeführt werden können, und kann davon
manchmal profitieren. Die Stärke des Intel Compilers liegt aber
aber vorallem in den mitgelieferten Libs.
Thomas W. schrieb:> Bei Intel gibt es die intrinsics, vielleicht als Tipp:> #include "immintrin.h">> __m256i x = _mm256_loadu_si256((__m256i*) src_address);> _mm256_storeu_si256((__m256i*) tgt_address, x);
Ja Danke.
Ich schätze mal, dass der Mikrocode von rep; movsb; genau das macht.
256 Bits sind 32 Bytes. Damit kommt man ungefähr auf 32 Bytes / Takt.
Komischerweise sehe ich sogar bis zu 45 Bytes pro Takt, obwohl die
Anwendung nur Single-Threaded ist. Keine Ahnung, wie das geht.
Reinhold E. schrieb:> Solche Messungen sind sicher interessant, wichtig ist da aber die exakte> Konstellation:> - Ist der Daten-Cache schon mit den zu kopierenden Bytes gefüllt?
Ja, ist er. In der Auswertung nehme ich die Ausreisser raus.
> - Ist die Menge zu schreibender Daten so klein dass sie komplett in den
Im letzten Diagram sieht man sehr schön, den Cache Effekt.
> Ansonsten natürlich wenn es dich interessiert, mach es und hab Spaß> dabei :-)
So soll es sein :-)
Thomas Z. schrieb:> Der Asm Code ist natürlich maximal schnell kann aber nicht damit umgehen> wenn sich die Speicherbereiche überlappen, testet nicht das> Richtungsbit, verwendet auch nicht movsw/movsd. Wenn du das alles> einbaust, wird der Unterschied zur lib nicht mehr so gross sein.
Der Asm Code von Agner Fog kann das alles.
Mein Asm Code ist nur ein Einzeiler, der kann das nicht.
Aber soweit ich weiss, muss jede Funktion die das Richtungsbit ändert,
dieses auch wieder zurücksetzen (ja, ja...).
(prx) A. K. schrieb:> Der Durchsatz von MOVSx kann sich auf verschiedenen Prozessoren> erheblich unterscheiden, und dabei auch erheblich von Randbedingungen> wie Grösse und Alignment abhängen. Nicht durch Caches spielen dabei eine> Rolle. Es kann sein, dass manchmal MOVSx schneller ist, manchmal eine> andere Variante.
Der rep; movsb; dürfte schon ziemlich an der theoretischen Grenze
kratzen. Die Anwendung ist ja nur Single-Threaded, MOVSx wird da
wahrscheinlich nichts bringen.
Miss-Alignment drückt die Performance von 44 Bytes/Takt auf 28
Bytes/Takt. Aber interessanterweise nur im Falle das man den Peak von
44 überhaupt
erreicht. Sonst spielen andere Faktoren eine grössere Rolle.
Ich wollte noch erwähnen, dass die Compiler alle mit -O2 übersetzen.
Ausnahme sind die Kurven mit "_max" im Namen, die optimieren
aggressiver,
und verwenden auch AVX Befehle.
Noch etwas Hintergrundinfo:
Im Intel Architectures-optimization-manual.pdf steht im Abschnitt 3.7.6
mehr zu memcpy Implementierungen.
Demnach ist rep; movsb; ab Ivy Bridge optimiert.
Ab Ice Lake auch für kurze Strings.
udok schrieb:> Der rep; movsb; dürfte schon ziemlich an der theoretischen Grenze> kratzen.
Das war allerdings nicht immer so. Zudem muss Microcode allen Kram zur
Laufzeit abfragen, wogegen der Compiler möglicherweise a priori um
Alignment und Grösse weiss. Bei kleinen Transfers kann der Overhead des
Microcodes eine wesentliche Rolle spielen.
Bestimmte Charakteristika von wiederholten Transfers, die dem
Programmierer bekannt sind, aber dem Compiler nicht, können sich in
explizitem Prefetching im Programm niederschlagen, und in Tuning in
Bezug auf die Nutzung der Caches. Das kann dann andererseits sehr von
der realen Maschine abhängen.
Mikro 7. schrieb:> Going faster than memcpy:> https://squadrick.dev/journal/going-faster-than-memcpy.html
Danke für den interessanten Link.
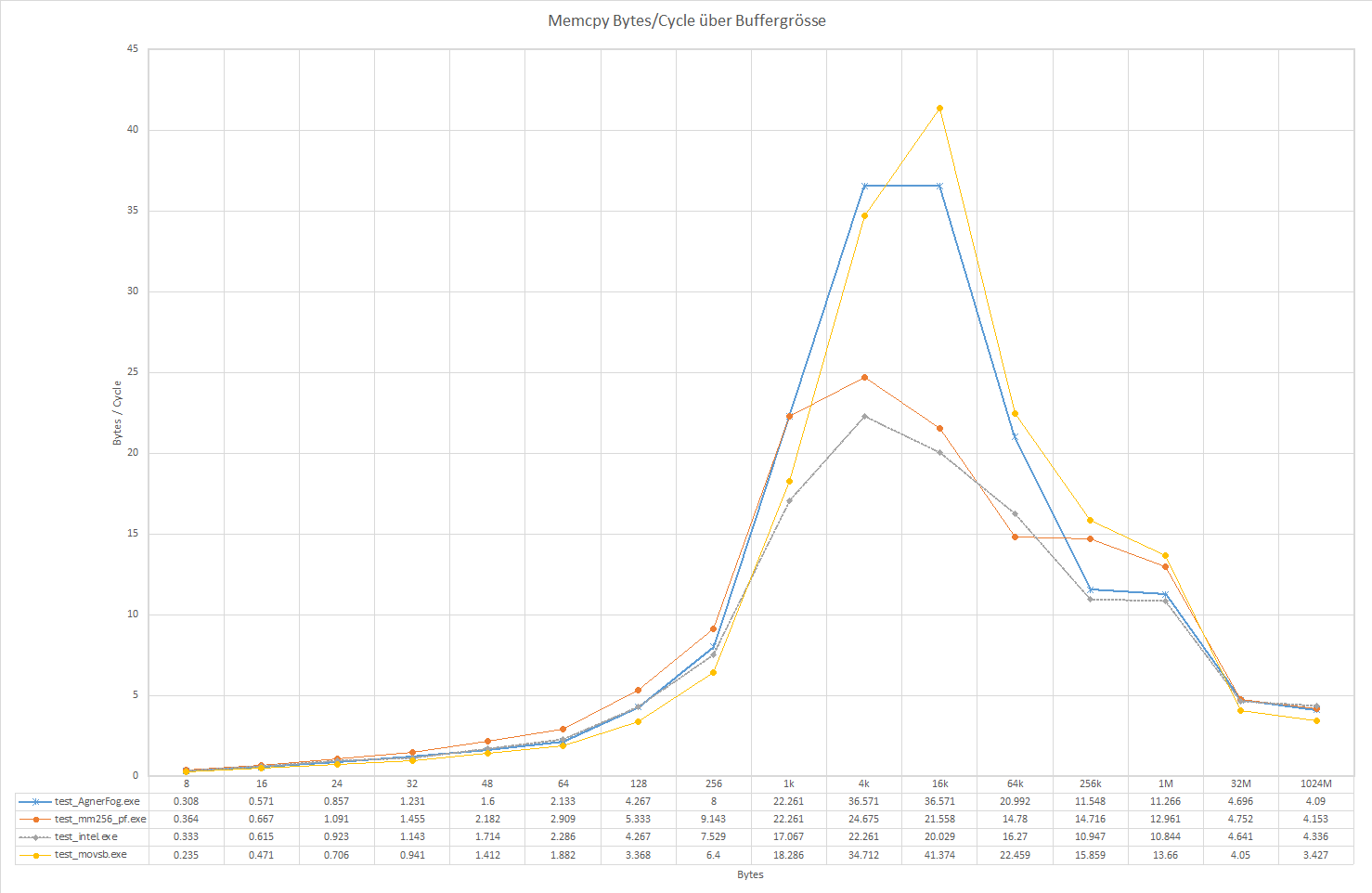
Ich habe die 256 Bit AVX Methode mit Prefetch eingebaut:
Die Performance ist recht gut zwischen 64 Bytes und 1k, drüber ist
die repsb Variante die schnellste.
Die Werte unter 64 Bytes sind gemogelt, da immer 64 Bytes kopiert
werden.
Auch müssen die Daten aligned sein, und durch 64 teilbar, was
in der einfachen Funktion nicht geprüft wird.
Für 1 GB gewinnt wieder die Intel memcpy, die auch bei kleinen Daten
unter 64 Bytes gewinnt.
Für > 8k ist die repsb die mit Abstand schnellste, mit > 160 GB/Sekunde.
5 Bytes / Takt entsprechen ca. 21 GB/Sekunde bei 4.2 GHz.
Ich habe ein zip mit den vier exe angehängt, falls jemand probieren
möchte.
Das Bash Skript run2.sh ruft die Programme auf, und macht eine txt
Tabelle.
Interessant wäre die Performance auf einer AMD Zen Architektur.
Ich habe noch Tests gemacht mit der 256 Bit AVX Prefetch Methode
(test_mm256_pf.exe).
Die Daten müssen aligned sein, sonst stürzt das Program mit Segfault ab!
Die repsb (rep movsb) Version ist ziemlich immun bei misalignment,
und kommt auch mit nicht power-2 Blöcken gut zurecht.
Genauso die AgnerFog und Intel Variante. Misalignment und krumme Blöcke
kosten aber schon ca. 20% in den einfachen Tests (121 Bytes statt 128).
Zwei Hinweise:
udok schrieb:> Die Daten müssen aligned sein, sonst stürzt das Program mit Segfault ab!
Daher; und weil aligned Zugriffe schneller sind, segmentieren Funktionen
wie memcpy den zu kopierenden Bereich (bspw. movsb bis aligned; dann
movsq; und das Ende wieder mit movsb).
udok schrieb:> 5 Bytes / Takt entsprechen ca. 21 GB/Sekunde bei 4.2 GHz.
Statt der Angabe pro Takt (auch in deinen Bildern) den Durchsatz
vielleicht besser grundsätzlich in GB/s angeben. -- CPU Takt und
Bus/Speicher Takt(e) sind entkoppelt. -- Die Werte kann man dann auch
besser mit dem th. peak Durchsatz des RAMs vergleichen (bspw. 1600 MHz
Bus x 64 x 2 = 25,6 GB/s).
Mikro 7. schrieb:> udok schrieb:>> Die Daten müssen aligned sein, sonst stürzt das Program mit Segfault ab!>> Daher; und weil aligned Zugriffe schneller sind, segmentieren Funktionen> wie memcpy den zu kopierenden Bereich (bspw. movsb bis aligned; dann> movsq; und das Ende wieder mit movsb).
Das interessante ist, das missaligned bei modernen Prozessoren
nicht langsamer ist. Die Agner Fog Lib zum Beispiel entscheidet zu
Laufzeit ,
welche Subroutine die schnellste ist, und auf meinem Laptop ist
es die memcpyU256, die Unaligned mit 256 Bits arbeitet.
Die ist bei kleinen Daten < 256 Bytes die schnellste, bei sehr
grossen Daten > 1 MByte sind aber aligned Zugriffe wieder schneller...
> udok schrieb:
>> 5 Bytes / Takt entsprechen ca. 21 GB/Sekunde bei 4.2 GHz.>> Statt der Angabe pro Takt (auch in deinen Bildern) den Durchsatz> vielleicht besser grundsätzlich in GB/s angeben. -- CPU Takt und> Bus/Speicher Takt(e) sind entkoppelt. -- Die Werte kann man dann auch> besser mit dem th. peak Durchsatz des RAMs vergleichen (bspw. 1600 MHz> Bus x 64 x 2 = 25,6 GB/s).
Ja, macht wahrscheinlich mehr Sinn. Wobei dann auch die Taktfrequenz
und
nicht nur die Architektur eingeht.
Aber ich lasse das mal so wie es ist, und die Ausgangsfrage ist ja erst
mal
genügend geklärt.
Nur mal so eine laienhafte Bemerkung: Ist denn das memcpy nicht
normalerweise als einfache Schleife implementiert*? Oder gibt es noch
Architektur-optimierte Varianten, die abhängig von der Zielarchitektur
dann wirklich ASM (in der Implementierung) nutzen?
*) Siehe z.B.
https://github.com/gcc-mirror/gcc/blob/master/libgcc/memcpy.c
Helpdesk schrieb:> Nur mal so eine laienhafte Bemerkung: Ist denn das memcpy nicht> normalerweise als einfache Schleife implementiert*?
Nein, das ist bloß die portable Referenzimplementierung, damit man auf
jeder Architektur (insbesondere auf neuen) garantiert was Lauffähiges
hat.
Noch ein Update mit einem übersichtlicheren Balkendiagram:
- Skalierung ist in GByte / Sekunde
- Compiliert wurde mit aktuelleren Intel 2019 und MS 2019 Compilern
- Die 2019 memcpy aus der vcruntime.lib (MS Universal Runtime UCRT)
is deutlich schneller als die aus der alten MSVCRT
- Der gcc macht aus einer for schleife mit -O3 -march=native
guten AVX Code, auch ohne Aufruf einer Lib Funktion.
- Die mm256 Versuche verwenden die AVX _mm256_load_si256()
und _mm256_store_si256() Funktionen, vor allem die Streaming Variante
mit 64 Byte Cache Line Prefetch ist bei Daten > 4 MByte sehr schnell
(L3 Cache ist 9 MByte).
Wünsche ein schönes Wochenende!