Hallo leute,
Ich habe mein custom design(Lattice ECP3-LFE3-35EA-7FTN256I) aus ein vom
Lattice
Reference Design(Versa ECP3-LFE3-35EA-8FN484C) abgeleitet.
Natürlich musste ich dann die Projekte-Eigenschafte anpassen:
Family
Device
Performance grade
Package type
Operation condition
Damit diese an mein neuen Baustein stimmen. Bisher war die Entwicklung
und einfacher Test super gelaufen.
Die großte Änderung die ich implementiert habe betrifft nur das
wb_tlc_dec.v
module in dem die IORequest übertragen werden im gegensatz zu Reference
Design wo nur Memory Request behandelt werden.
4000-43ff: IO MAP (UART1,UART2)
5000-xxxx: MMAP (sonstige)
Dann habe ich seit letzter Montag das folgende Problem:
1)Lesen aus ein UART-Register durch loop bis 1000 klappt nicht
Er liest problemlos bis 237 dann 5 Mal 0xFF danach bleibt das System
hangen.
2)Wenn ich nun der Memory-Space 4000-43ff als MMAP definiere und der
Test durclaufen lasse (20Uhr - 7 Uhr Morgen), wird die richtige Werte
0xC1 gelesen bis 4000 000 loops dann meldest sich der Test Treiber ab.
(Kling für mich as Timer Lattice IPCore bin ich nicht sicher)
Deswegen hätte ich gern ein Feedback von euch. Woran kann es liegen ?
beigefügt ist das einzige Module das ich geändert habe um die IO Request
zu ermöglichen.
Ich bitte um Hinweise schon 4 Tagen ohne Lösung.....
es gelingt mir bis(UART1,UART2)
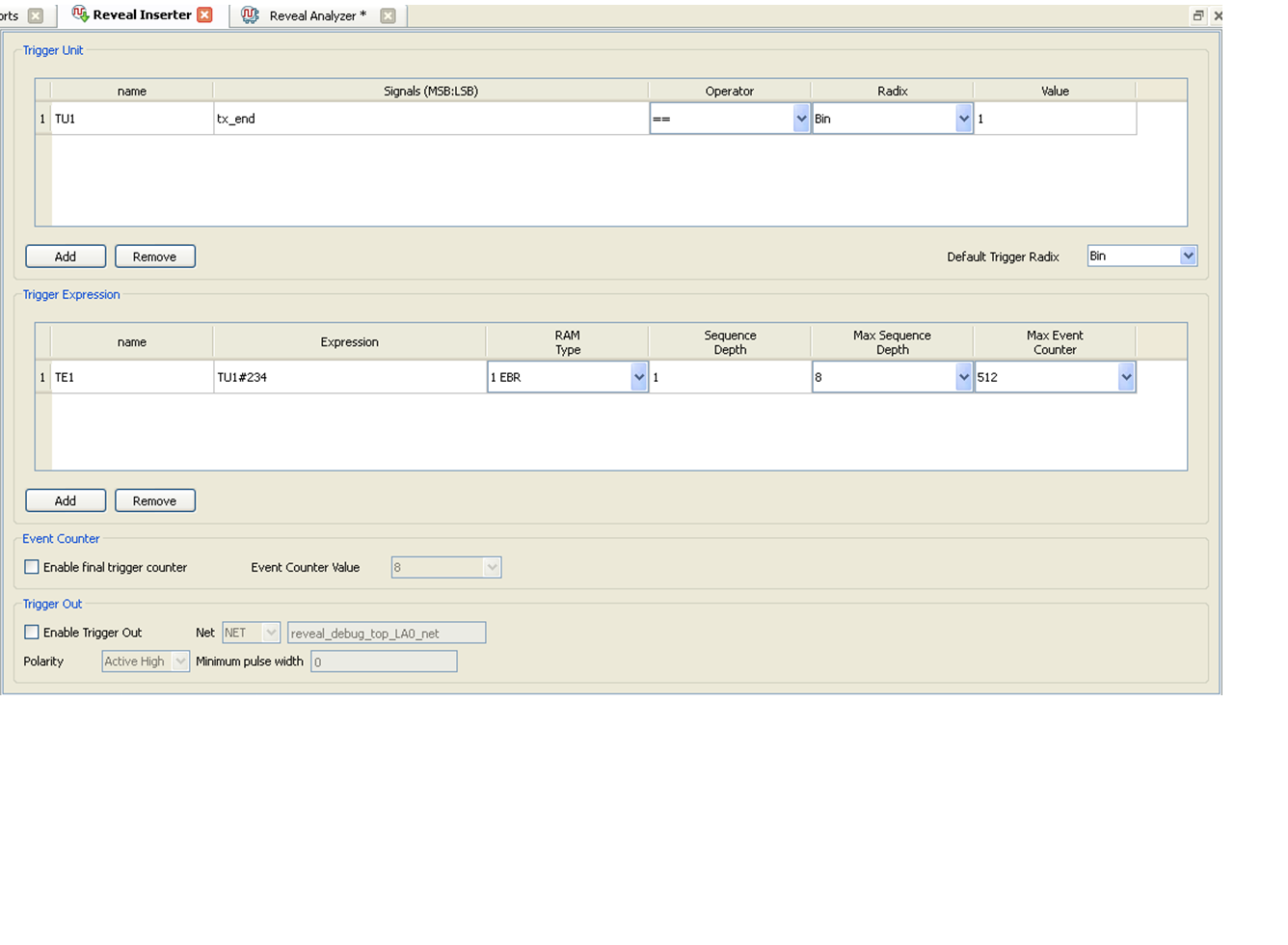
Mein Logik Analyser sieht gut aus. Da ich mit dem Counter bis 234
getriggert habe.(Reveal_Inserter.PNG und LogikAnalyser_Output.png)
Und 0xC1 Data ist im TLP Packet.(Sieht Bilder)
Hinzu habe ich auch mein topdesign damit du siehst wie die Clock
verteilt sind.
Die UARTs brauchen 25 MHz. Die habe ich über PLL erzeugt.
Ich möchte mal das Lattice Basic Reference Design machen und nur IO
Request im Module wb_tlc_dec.v zulassen.
Und der selbe Test beim Lesen GPIO Adresse 0002 durführen.
Ob ich problemlos 04 bis 1000 gelesen wird?
Im gpio Module steht :
1
9'h002:begin
2
if(rd)wb_dat_local<=16'h1204;
3
end
Oder bin ich auf dem falschen Lösungsweg ? vielleicht Routing Problem ?
Das Verhalten deutet auf einen PCIe Protokollfehler.
Erstens, das Naheliegende:
Was sagt die Timinganalyse. sind die für PCIe nötigen 125 MHz noch
erfüllt?
Zweitens:
Änderung Memory Access auf IO Access ist nicht trivial, IO Writes
brauchen im Gegensatz zu Memory Writes eine Completion. Und
Intelchipsätze reagieren allergisch auf fehlende Completions.
Die Erzeugung von Completions ist beim Lattice Core in der Verantwortung
des Userscodes.
Ob der Latticewrapper dessen Source du hast, die Erzeugung von
Completions für IO Writes enthält habe ich nicht nachgeprüft.
Davon abgesehen: IO Access ist angefaultes Legacy!
OK !
beigefügt ist meine Timing Analysis: sieht diese versprechend aus oder
sieht man kritishe Punkte drin ?
Nach der Lattice Beschreibungen sind die Completions TLP in folgende
Module behandelt: wb_tlc_cpld.v und wb_tlc_cpld_fifo.v
Und es scheint als Memory sowie IO TLP Completion generiert werden. Aber
ich bin noch nicht ganz sicher, ich analysiere noch den Inhalt.
>> Und es scheint als Memory sowie IO TLP Completion generiert werden. Aber> ich bin noch nicht ganz sicher, ich analysiere noch den Inhalt.
Bei Memoryaccess braucht nur Read eine Completion, die gelesenen Daten
müssen ja zurück :-)
Memory Write ist postet und braucht keine.
Bei IO Access mus auch für Write eine Completion erzeugt werden, ohne
Daten.
(siehe PCIe Spec 2.2.9)
OK ,
Wenn ich ein IORead mache, habe ich den richtige Daten. Das Problem
tritt nur wenn nacheinander gelesen wird.
Also in meinem Verstandnis werden IO TLP vom cpld Module behandelt aber
nicht vollstanding oder bist du andere Meinung ?
keller thomas schrieb:> OK ,>> Wenn ich ein IORead mache, habe ich den richtige Daten. Das Problem> tritt nur wenn nacheinander gelesen wird.> Also in meinem Verstandnis werden IO TLP vom cpld Module behandelt aber> nicht vollstanding oder bist du andere Meinung ?
Dein wb_tlc_cpld.v erzeugt nur die Completions für die WB Lesezugriffe.
Überprüfe mal ob für die IO Zugriffe eventuell auch UR Completions
erzeugt werden (UR = Unsupported Request)
(Das ganze schreit nach einem PCIe Analyzer)
Nach deiner Anmerkung habe ich nochmals das ganze angeschaut.
Die Äderung die ich im Module wb_tlc_dec.v gemacht habe allein reicht
nicht
für eine effiziente Behandlung der IO TLP Transaction.
Sondern folgende Module sollen auch entprechend für eine effiziente IO
Completion geändert werden:
UR.v
ip_rx_crpr.v
1 ) also insgesamt 3 Module meiner Meinung nach angepasst werden. Bisher
habe ich nur wb_tlc_dec.v mit folgende hinzugefügt um IO Request zu
laasen:
IO transactions requests are restricted to 32 bits of address using the
3DW TLP Header format, and should only target legacy devices.
Since PCI Express still permits either 32 bit or 64 bit memory
addressing but the size of System IO Map is limited to 32
bits(4GB),although in many system only lower 16 bits(i.e 64 KBs) are
used.
So you can customize the existing code as per your requirement in order
to account for IO request and should be responsible for sending an
Unsupported Request completion based on the capabilities of your
customized design.
For example, if in case your custom design only works with IO
transactions and not memory transactions, then memory transactions are
unsupported. These types of transactions require an Unsupported Request
completion.
However there are several instances in which an Unsupported Request must
be generated by the user. These conditions are
listed below.
• rx_us_req port goes high with rx_st indicating a Memory Read Locked,
Completion Locked, or Vendor Defined
Message.
• Type of TLP is not supported by the user's design (I/O or memory
request)
Table 2 in ipug75 on page 35 shows the types of unsupported TLPs which
can be received by the IP core and the user interaction.
Link to download ipug75
http://www.latticesemi.com/~/media/Documents/UserManuals/MQ/PCIExpress11x1x4IPCoreUsersGuide.PDF#search=%22ipug75%22
Hallo Hier die Anworte vom Lattice Support:
IO transactions requests are restricted to 32 bits of address using the
3DW TLP Header format, and should only target legacy devices.
Since PCI Express still permits either 32 bit or 64 bit memory
addressing but the size of System IO Map is limited to 32
bits(4GB),although in many system only lower 16 bits(i.e 64 KBs) are
used.
So you can customize the existing code as per your requirement in order
to account for IO request and should be responsible for sending an
Unsupported Request completion based on the capabilities of your
customized design.
For example, if in case your custom design only works with IO
transactions and not memory transactions, then memory transactions are
unsupported. These types of transactions require an Unsupported Request
completion.
However there are several instances in which an Unsupported Request must
be generated by the user. These conditions are
listed below.
• rx_us_req port goes high with rx_st indicating a Memory Read Locked,
Completion Locked, or Vendor Defined
Message.
• Type of TLP is not supported by the user's design (I/O or memory
request)
Table 2 in ipug75 on page 35 shows the types of unsupported TLPs which
can be received by the IP core and the user interaction.
Link to download ipug75
http://www.latticesemi.com/~/media/Documents/UserManuals/MQ/PCIExpress11x1x4IPCoreUsersGuide.PDF#search=%22ipug75%22
Hallo,
nun meine Frage glaubst du dass, das Problem nur mit Änderungen
von 2 Modules:
UR.v
und
wb_tlc_dec.v
gelöst wird ?
Da Lattice Support nicht über das Module iprxcrpr.v spricht ?
keller thomas schrieb:> Hallo>> Ich verstehe nicht was ich falsch gemacht, da du das selbe Code> eingefügt hast.
Du musst genauer hinschauen, ist nicht derselbe.
1
one_ph <= 1'b1;
2
one_pd <= 1'b1;
versus
1
one_nph <= 1'b1;
2
one_npd <= 1'b1;
> Kannst du bitte genauer meinen Fehler erlautern ?
Das geht sehr ins Eingemachte, und nur einfach zu erkären wenn du weisst
wie bei PCIe Flusskontrolle implementiert wird, was der Unterschied
zwischen Postet und Non Postet Requests ist, und noch einiges mehr.
Hallo Gute Nachricht!
Es tut schon beim Lesen!!!!!!!!!
Habe ich 100 000 000 Loop problemlos gelesen!
Nun soll ich auch Write schaffen und da ist mir beim Credit Processing
noch nicht klar.
reicht folgende Code für IO Write ?
keller thomas schrieb:> Hallo Hier die Anworte vom Lattice Support:> IO transactions requests are restricted to 32 bits of address using the> 3DW TLP Header format, and should only target legacy devices.
Dem schliesse ich mich an, angefaultes stinkendes Legacy.
Warum willst du es eigentlich machen? DOS 3.3? Windows 95/98?
>> Since PCI Express still permits either 32 bit or 64 bit memory> addressing but the size of System IO Map is limited to 32> bits(4GB),although in many system only lower 16 bits(i.e 64 KBs) are> used.>
Das bedeutet nur, dass du IO Requests mit 4 DW Headern als UR ablehnen
sollst. Ist relativ unkritisch, da diese normalerweise nicht vorkommen
sollten. (Ausser in Verifications Umgebungen)
keller thomas schrieb:> Hallo Gute Nachricht!>> Es tut schon beim Lesen!!!!!!!!!> Habe ich 100 000 000 Loop problemlos gelesen!> Nun soll ich auch Write schaffen und da ist mir beim Credit Processing> noch nicht klar.>> reicht folgende Code für IO Write ?
Nein, IO Write braucht wie schon mehrmals erwähnt eine Completion (nur
Header ohne Daten)!
Du hast etwas falsch verstanden, es geht nicht um den empfangenen Header
der war vorher schon in Ordnung.
Completion ist ein Antwortpacket das NACH einem IO Write generiert
werden muss, genau wie bei IO Read aber ohne Daten.
Am einfachsten dürfte es sein, das in wb_tlc_cpld.v und
wb_tlc_cpld_fifo.v mit einzubauen, aber beachten dass es bei Memory
Writes NICHT gemacht wird.
Es hat geklappt aber ich habe das Gefühl dass, es eine kleine
Verzögerung beim IOWrite gibt.
Sonst es funktioniert...
Hat das wahrscheinlich mit der Completion zu tun ? Wenn dann wie kann
ich diese verbessern ?
keller thomas schrieb:> Es hat geklappt aber ich habe das Gefühl dass, es eine kleine> Verzögerung beim IOWrite gibt.> Sonst es funktioniert...> Hat das wahrscheinlich mit der Completion zu tun ?
Ja hat es.
Der Intelchipsatz, ist da gutmütig, d.h. er macht nach einem Completion
Timeout einfach weiter. (Beim Lesen bekommt man dann 0xFFFFFFFF).
Es gibt aber andere. (Nvidia Ion friert ein).
Siehe auch ein frühres Posting:
Beitrag "Re: Lattice ECP3: IO Read Begrenzung"
keller thomas schrieb:> OK das habe ich auch verstanden!> Wo was getan werden soll ist meine Frage. Also ich weiße nicht wo ich> damit anfangen soll.
Chapter 2.2.9 in der PCIe Spec 2.1 lesen und verstehen.
Dannach verstehen was in der wb_tlc_cpld.v genau gemacht wird.
Wenn das klar ist, versuchen die FSM in der wb_tlc_cpld.v zu ergänzen.
rx_din[15:8] und rx_bar_hit sind ganz sicher nicht mehr gültig.
Du brauchst ein zusätzliches Signal entsprechend "read", das ein iowrite
durchreicht.
tran_length muss bei write completions auf 0 gesetzt werde, es wird ja
nur der Header gesendet.
"bc" muss 4 sein, aber ob für "la" die byte enables ausgwertet werden
sollen
kann ich dir jetzt nicht mit Sicherheit sagen, ich vermute nein.
(Immer daran denken, iowrite ist verfaultest Legacy, und die Behandlung
von cfgwrites nimmt uns der core ab)
Wenn dies sich au Power Management Messages bezieht dann habe ich....
Ich habe mit TLP gerechnet und nicht mit Power Message da ich keine
Zusammenhang sehe.
Die Tabellennumerierung im Latticecode bezieht sich offensichtlich noch
auf die PCIe Spec 1.1
In der 2.1 Spec sind das jetzt die Tabellen 2.31 und 2.32
Danke,
Mit tran_length = 0 verstehe ich aber bc =4 ist mir unklar weil:
wenn First_BE = 0xF = 1111 dann BC=4
aber hier habe ich mein IOWr Paket angeschaut und First_BE=0x1=0001 also
würde ich damit BC= 1 erwarten oder ?
>> Mit tran_length = 0 verstehe ich aber bc =4 ist mir unklar weil:> wenn First_BE = 0xF = 1111 dann BC=4>> aber hier habe ich mein IOWr Paket angeschaut und First_BE=0x1=0001 also> würde ich damit BC= 1 erwarten oder ?
In 2.9 Completion Rules steht, dass der BC für alle Completions ausser
Memory Reads (und AtomicOPs hier irrelevant) 4 sein muss.
Das schliesst auch IO Reads mit ein!
Wo kommt "rx_din" her? wenn es einfach rx_din vom PCIe core ist, kann es
nicht gehen. Der Wert den du da abfragen willst, liegt da schon seit
vielen Takten nicht mehr an.
Schau Mal ganz unten dem folgende Module. Ich habe einfach rx_din
hinzugefügt als neu input für das Module wb_tlc_cpld.
Es wäre vielleicht einfacher wenn man folgende Signale ausnutzen würde:
Hallo hier einen Hinweis zu la Signal:(2.2.9 Completion Rules im PCIe
Specification 2.1)
Damit muss man la =0
• Lower Address[6:0] – lower byte address for starting byte of
Completion
♦ For Memory Read Completions, the value in this field is the byte
address for the first
enabled byte of data returned with the Completion (see the rules in
Section 2.3.1.1)
♦ For AtomicOp Completions, the Lower Address field is reserved.
5 ♦ This field is set to all 0’s for all remaining types of Completions.
Receivers may
optionally check for violations of this rule. See Section 2.3.2, second
bullet, for details.
Ich habe auch dies aus von Xilinx Completion Module (Sieh unten)
keller thomas schrieb:> Schau Mal ganz unten dem folgende Module. Ich habe einfach rx_din> hinzugefügt als neu input für das Module wb_tlc_cpld.
rx_din ist wie schon mehrfach gesagt ungeignet.
Du musst dir den ganzen Ablauf in Takten vor Augen halten, sonst wird
das nichts mit deiner Zukunft als VHDL/Verilog Entwickler.
> Es wäre vielleicht einfacher wenn man folgende Signale ausnutzen würde:>
1
>assignwrite=wb_cyc_o&&(wb_we_o);
2
>assignread=read_comp&&(~read_comp_d);
3
>
Schon besser, aber beachte dass das write das dem cpld übergibst nur
einen Takt lang sein sollte, (am Ende des WB Cycles)
Ausserdem ganz wichtig, wenn du es wie bei read nur aus den Whishbone
signalen generierts, kannst du nicht zwischen Mem und IO Writes
unterscheiden. Und bei Mem Writes darfst du keine Completions
generieren.
keller thomas schrieb:> Hallo hier einen Hinweis zu la Signal:(2.2.9 Completion Rules im PCIe> Specification 2.1)> Damit muss man la =0
Da bin ich mir nicht sicher, aber ich habe bislang keine Write
Completions (IO bzw CFG) implementieren müssen, und damit das ganze auch
nicht detailiert untersucht.
Leg dir einen PCIe Analyzer zu, dann kannst du schauen was bei CFG
Writes gemacht wird.
Hallo ,
Habe was festgestellt, beim Read aus MemoryMap Bereiche also BAR1 wird
das Signal read gesetzt und Completion auch.
Aber beim Read aus IO-Bereiche wird das Signal Read niemals gesetzt.
Es scheint als es ein Filter irgendwo noch gibt der nur MWr/Mrd
ermöglicht.
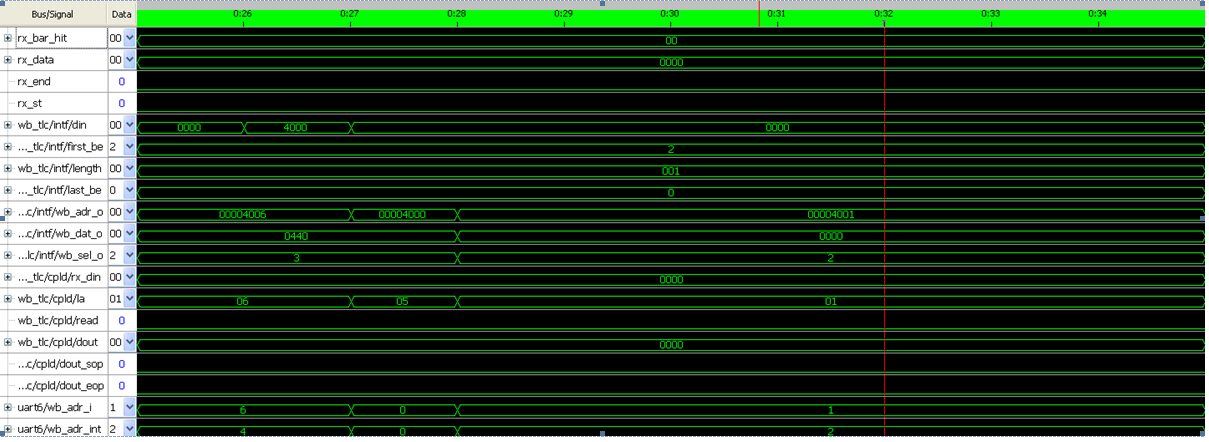
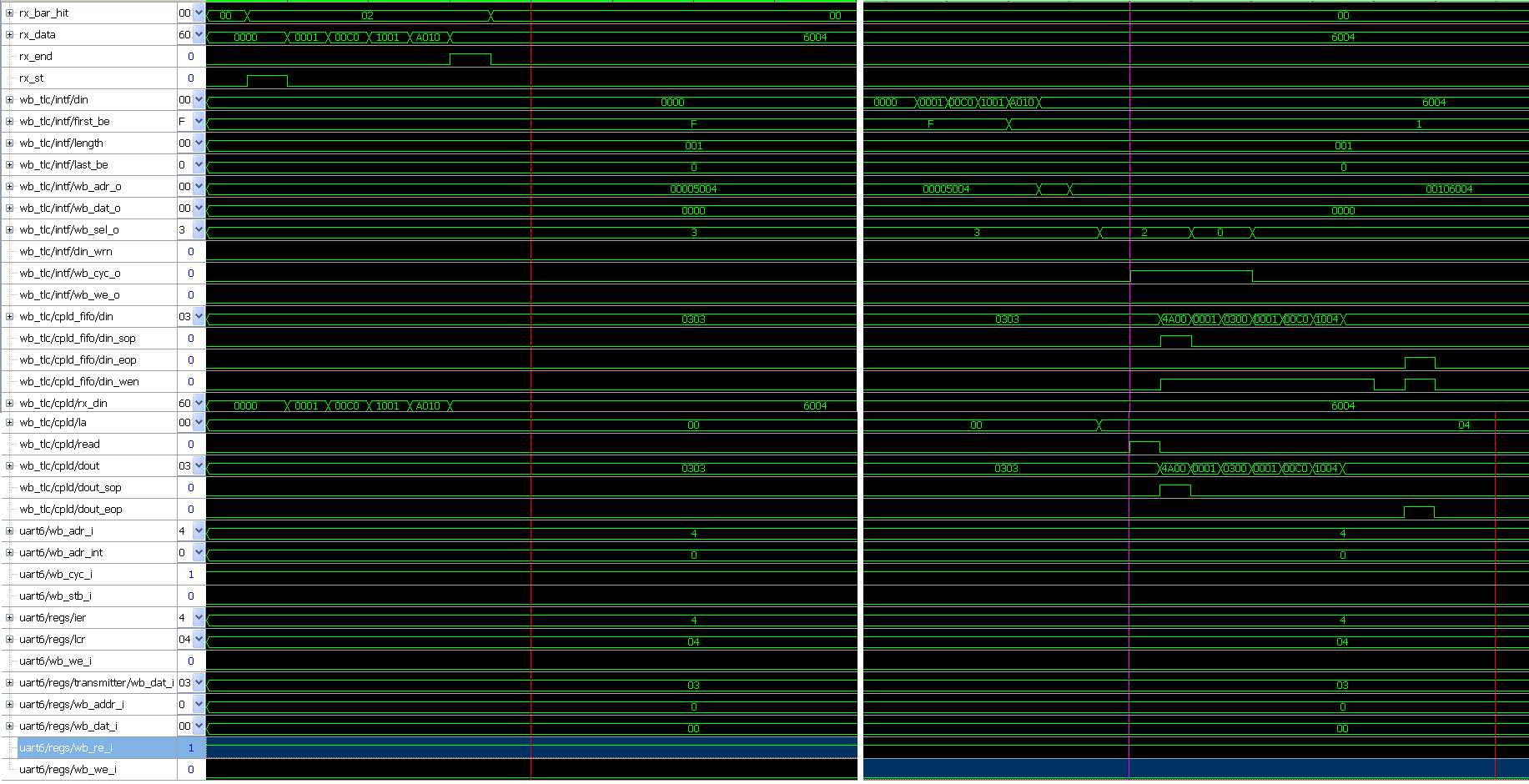
Schaue Mal bitte kurz die Bilder aus LogicAnalyser aus
keller thomas schrieb:> Hallo ,>> Habe was festgestellt, beim Read aus MemoryMap Bereiche also BAR1 wird> das Signal read gesetzt und Completion auch.> Aber beim Read aus IO-Bereiche wird das Signal Read niemals gesetzt.> Es scheint als es ein Filter irgendwo noch gibt der nur MWr/Mrd> ermöglicht.
Da es schon mal funktioniert hat, mit Backup bzw älterem Zustände aus
der Versionsverwaltung vergleichen.
> Schaue Mal bitte kurz die Bilder aus LogicAnalyser aus
Um aus denen schlau zu werden, müsste ich mich mit allen Details der
Implementation beschäftigen. Dazu habe ich keine Zeit. Davon abgesehen
ist der Ausschnutt zu kurz: Wo ist der empfangene Request?
(Ich habe einen eigenen Wrapper und verwende nicht den von Lattice).
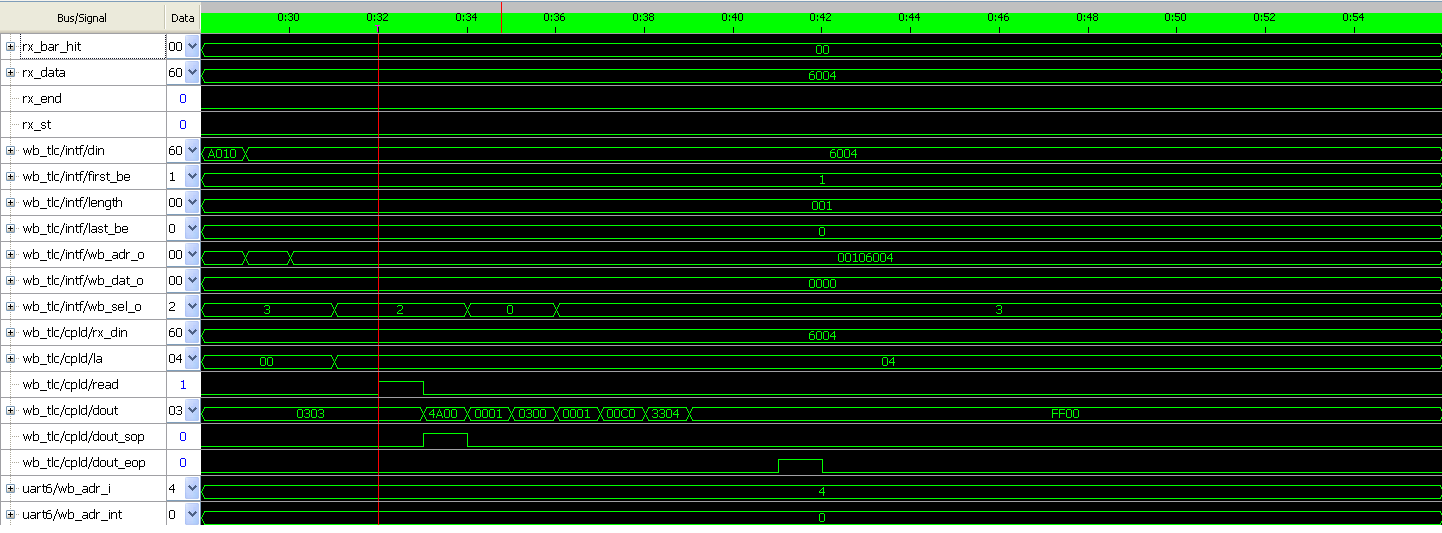
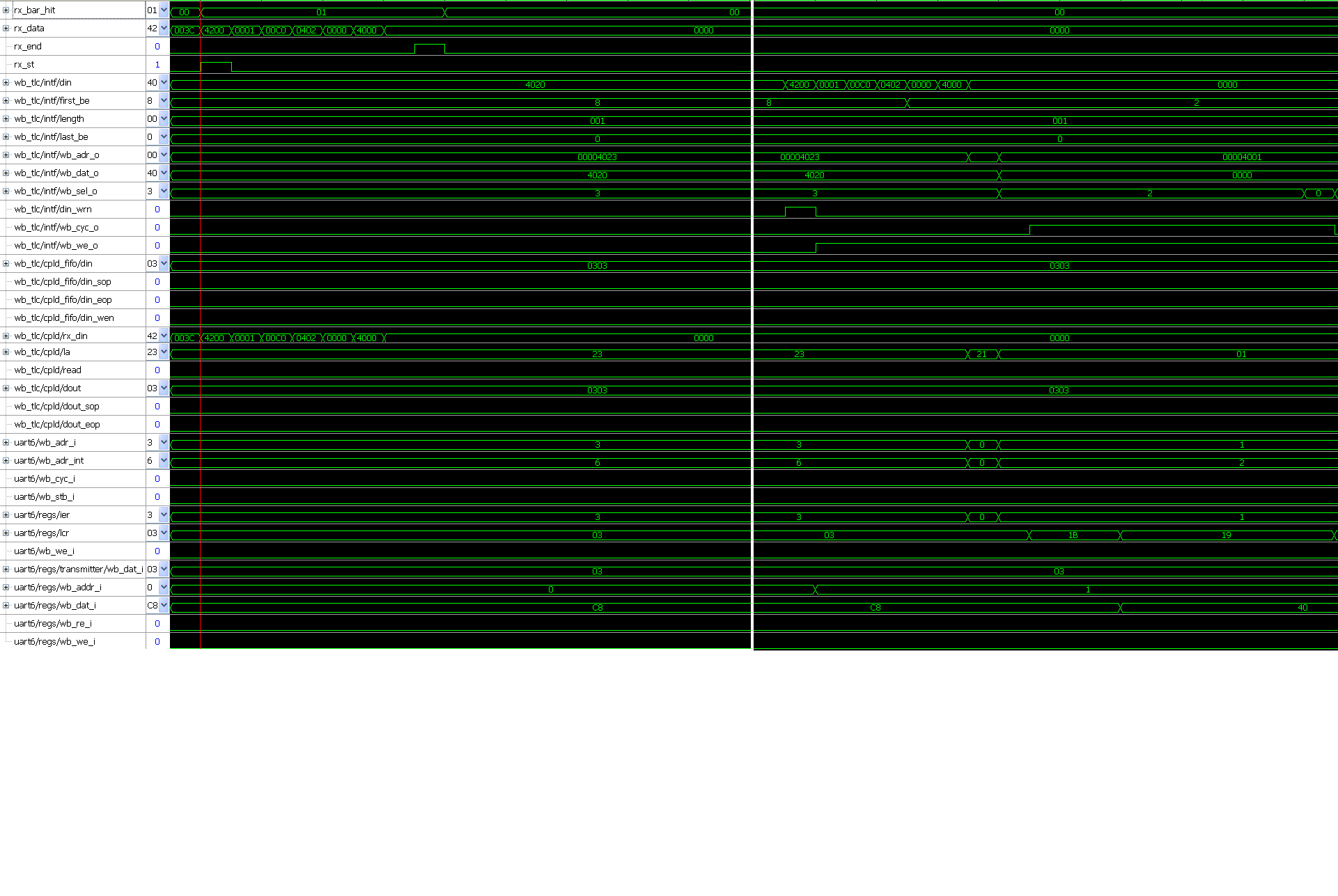
Hallo Hier ein voll Ausschnutt (Request+ Completion)
Bei IO-Read TLP wird die richtige Wert gelesen (cpld_fifo/din =
cpld/dout = 0x0303)ohne Header. Read Signal wird niemals gesetzt obwohl
die richtige Data zuruckkommen.
Bei Memory-Read wird 0xFF00 mit entprechende Header gelesen als
Completion.
Hat diese vielleicht mit meinen ip_rx_crpr.v und UR_gen.v Module?
Auf Hinweis werde ich denkbar da, ich seit 1 Woche daran arbeite.
Zusammengefasst unten Linux Ausgabe:
Beim IO-Read wird 0x03 an die Adresse 0x4000 gelesen
und
Beim Memory-Read wird 0xFF an die Adresse 0x106004 gelesen
Bei IO-Read bleibt der Counter ( word_cnt ) vom cpld.v Module bei 0 aber
trotzdem wird die richtige Daten gelesen.
Und beim IO-Write bleibt der Counter immerhin bei 0
Dann lässt sich die Frage stellen Warum ? Wie soll ich ihm erzwingen
rein zu gehen ? Es gibt meiner Meinung nach eine Zeilecode wo nur Memory
Requests erlauben werden.
Auf Hinweise würde ich mich freuen
keller thomas schrieb:> Ich hätte erwartet dass, das read Signale beim IO-Read zu 1 geht .> Mein naschter Schritt ist der Grund zu verstehen oder ?
Offensichtlich wird in wb_intf der IORead nicht erkannt
Hallo,
Ich habe aus ein ECP3 PCI Express Basic Demo Design mein Design
abgeleitet(also MMAP basiert ohne IO).
Beim Test lauft alles gut bis etwa 8 Stunden und bleibt hangen.
Ist dies ein Hardware Timer oder Timing Constrainsts ?
beigefügt is mein Place_Route_Trace_Report zu finden.
Auf Anmerkungen würde ich mich freuen..
keller thomas schrieb:> Beim Test lauft alles gut bis etwa 8 Stunden und bleibt hangen.
Hört sich nach fehlender PCI Express Lizens an. (Eval Timer)
Disable mal in den Strategy Settings unter Translate Design die Hardware
Evaluation.
Eigentlich habe ich eine Lizenz. Nur habe ich mein Design vom
ReferenzDesign danach zusatzliche Komponente addiert.
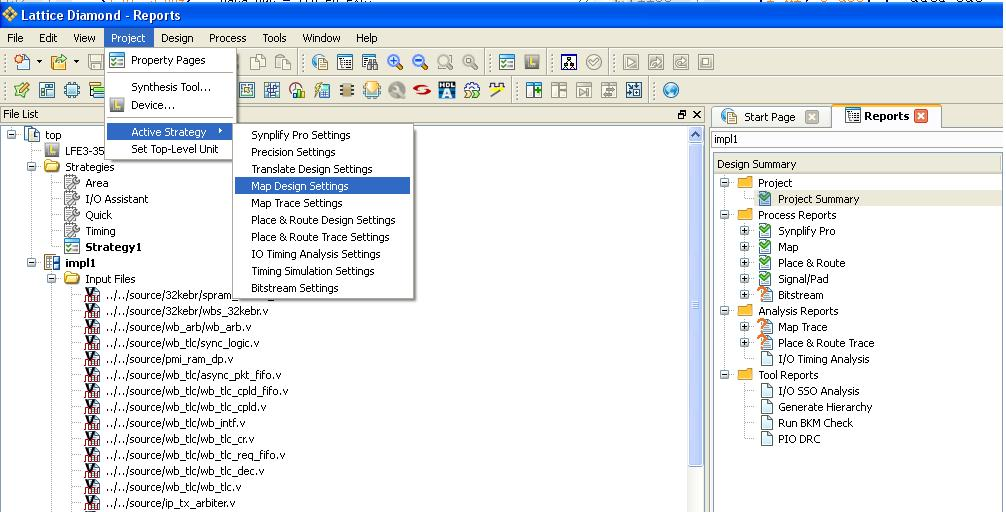
Wie komme ich drauf also unter welche Menu (Sieh Bild)
Hallo,
Unter Project/Active Strategy/Translate Design Setting habe ich
folgende:
Name Type Value
Hardware Evaluation List Enable
Was soll ich denn hier ändern durch was ??
Hallo,
Nach der Änderung
Hardware Evaluation List Disable
Habe ich während der neuen Kopilierung folgende Meldung erhalten:
Your License has expired.
Feature has expired.
Feature: LSC_IP_pcie_x1_e3_ipe
Expired date 16-jan-2013
Danach bleibt meine Kompilierung hängen.Somit ist mir klar dass, es um
eine Lizenz Problem geht oder ?
keller thomas schrieb:> Your License has expired.> Somit ist mir klar dass, es um eine Lizenz Problem geht oder ?
Sieht wohl so aus...
Die Lizenz des Versa-Kits gilt nur für 1 Jahr. Dann musst du dir ein
neues Kit kaufen... ;-)
Lothar Miller schrieb:> keller thomas schrieb:>> Your License has expired.>> Somit ist mir klar dass, es um eine Lizenz Problem geht oder ?> Sieht wohl so aus...>> Die Lizenz des Versa-Kits gilt nur für 1 Jahr. Dann musst du dir ein> neues Kit kaufen... ;-)
Für Diamond selbst hat er ja eine gültige Versa-spezifische Lizenz, die
freie Weblizenz gilt normalerweise nicht für die ECP3.
Also einfach mal nachfragen.
Auch bei der Verlängerung regulären Volllizenz für Diamond, muss man die
IP Lizenzen jedesmal manuell nachtragen lassen.