
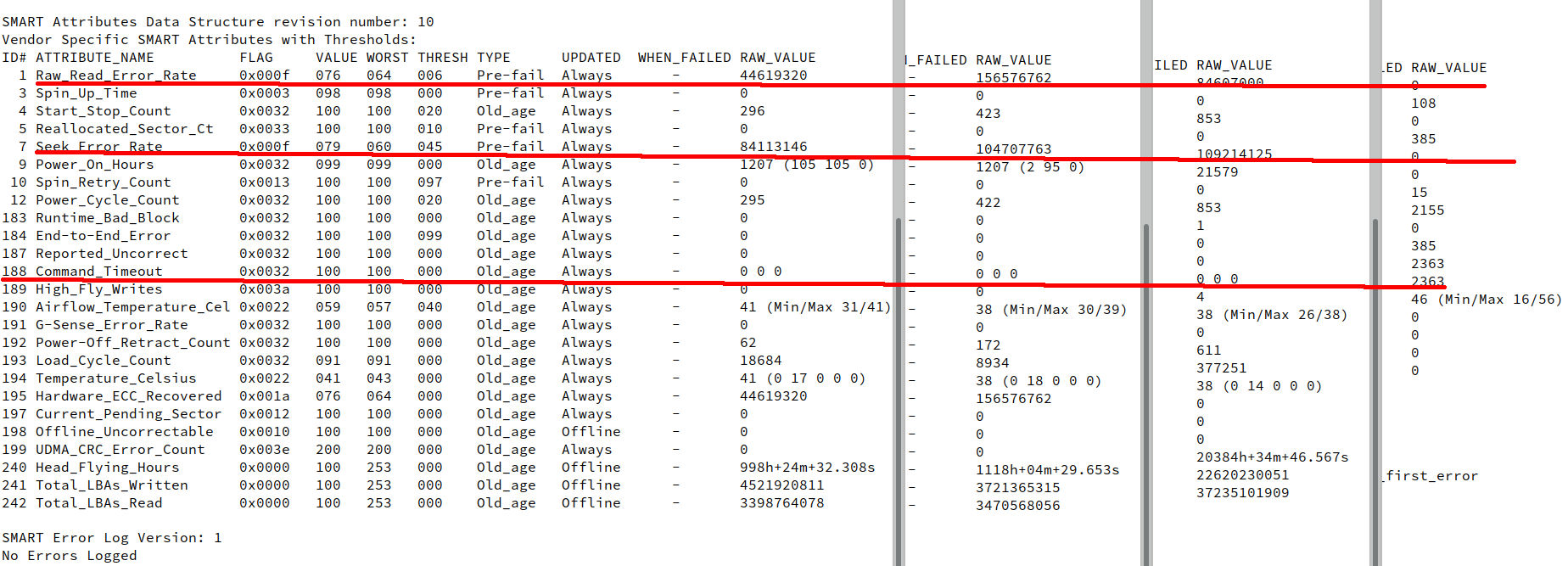
Hallo Forum, sorry muss als Gast posten, da ich mein PW grade nicht zur Hand habe. Habe vier HDs mit dem o.g. output von smartctl -a Werde aber nicht ganz schlau daraus und hoffe Ihr könnt mir etwas auf die Sprünge helfen. Vor allem die letzte Disk ganz rechts könnte Probleme haben - sehe ich das so richtig? Aufgefallen ist mir das heute, weil der zypper dup Vorgang bereits auf zuvor heruntergeladene Packete mit zypper dup --download-only sehr langsam läuft. Von meinen Notebooks bin ich es gewöhnt, das der Update von bereits auf der Disk heruntergeladenen Packeten ratzfatz durchläuft. Ich warte aber schon fast zwei Stunden auf das Finish. Das könnte auf ein Disk-Problem hindeuten. Ich sehe aber keine Fehlermeldungen via journalctl -f zypper Durchlauf gekürzt s.u.: >In cache binwalk-2.3.2-1.1.noarch.rpm (2019/2021), 187.2 KiB >(832.1 KiB unpacked) >In cache q4wine-1.3.12-1.17.x86_64.rpm (2020/2021), 2.9 MiB ( >5.1 MiB unpacked) >In cache q4wine-lang-1.3.12-1.17.noarch.rpm (2021/2021), 216.9 KiB ( >1.4 MiB unpacked) > >Checking for file conflicts: .........................................................[done] >( 1/2059) Removing libstdc++6-pp-gcc9-32bit-9.3.1+git1684-3.5.x86_64 ...............[done] >( 2/2059) Removing libstdc++6-pp-gcc9-9.3.1+git1684-3.5.x86_64 .....................[done] >... fast zwei Stunden dazwischen!!! >(1023/2059) Installing: shadow-4.8.1-7.1.x86_64 ......................................[done] >(1024/2059) Installing: pam-config-1.3-2.1.x86_64 ....................................[done] >Additional rpm output: Könnt Ihr mir diesbezüglich Eure Einschätzung geben, was Sache ist. Danke für die Mühe schon mal vorab. Markus
Angehängte Dateien:
:
Verschoben durch Moderator
Die ersten 3 HDDs sind Seagate, die vierte HDD ist eine WD. Die RAW values verschiedener Hersteller lassen sich schlecht vergleichen. Gib mal bitte den kompletten Output von /dev/sdd hier an - aber nicht als Bild, sondern als Text - zum Beispiel Dateianhang.
Moin, Ich wuerd' dann auch einfach mal die Selbsttests der Pladden empfehlen; also: smartctl -t short /dev/bla oder auch mal long, wenns nicht pressiert... Gruss WK
Sorry sehe gerade der Beitrag ist im Falschen Bereich gelandet! Bitte nach PC-Hardware verschieben. Danke! Jetzt ist auch das Bit im Hirn gekippt und ich habe mich aus dem Gedächtnis einloggen können ;-) Nun zum eigentlichen Problem: Die vollen Outputs der sda bis sdd sind nun im Anhang gelistet. Hoffe das Sichten macht nicht zu viel Mühe. Übrigens liegt /var auf sda4 dort legt doch zypper seine herunter geladenen Pakete ab - richtig? /dev/sda4 125G 46G 73G 39% /var Ich habe aber erst einmal alle Disks durchforstet um eventuelle Fehler zu erkennen und anhand der Werte vergleichen zu können. Markus
@Dergute W. da mein Update gerade läuft, ist das halt suboptimal. Aber Danke für das Kommando - war mir aber bereits bekannt. LG Markus
@Frank M. Hallo Frank, ich habe mich in meinem Eröffnungsbeitrag verschrieben bzw. verschaut. Gemeint ist die dritte Disk, die mit den meisten Betriebsstunden, sofern dieser Wert verlässlich ausgegeben wird. Markus
Markus W. schrieb: > > Die vollen Outputs der sda bis sdd sind nun im Anhang gelistet. > Hoffe das Sichten macht nicht zu viel Mühe. Die SMART Werte sind im grünen Bereich. Wie ein Vorredner schon sagte, lassen sich die RAW Werte zwischen Herstellern nicht vergleichen. Das gilt ganz besonders für Attribute 1 und 7. Festplattenfehler auf gemounteten Partitionen führen auch immer zu Einträgen im Log, z.b. /var/log/syslog oder /var/log/kernel (kommt auf die Konfiguration an). > Übrigens liegt /var auf sda4 dort legt doch zypper seine > herunter geladenen Pakete ab - richtig? > > /dev/sda4 125G 46G 73G 39% /var Weiß nicht. Habe kein zypper. Abgesehen davon ist /dev/sda4 die 4. Partition auf der 1. Platte. Und falls die Partition, die /var hält kaputt sein sollte, ist auf das Log natürlich kein Verlass. Mit dmesg sollte man aber zumindest noch den Ringbuffer des Kernels mit den letzten Messages auslesen können.
:
Bearbeitet durch User
Nö da ist doch nichts. 'TRESH' setzt den Level ab dem gewarnt wird wenn 'VALUE' ihn unterschreitet. ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH 1 Raw_Read_Error_Rate 0x000b 100 100 016 Die raw Werte sind kein Ereigniszähler wie z.B. beim Power_Cycle_Count gleiches gilt für die Seek_Error_Rate Da gibts nichts das mich stören würde. Sicher das dein Paketmanager mit 'zypper dup --download-only' genau das macht was du dir vorstellst? Lädt der nicht alles nötige zum he Distributionsupgrade runter und installiert es nur nicht? --- nur überflogen --- If --download-only is used, the downloaded packages will be available in /var/cache/zypper/RPMS To get a meaningful file conflict check use --dry-run together with --download-only
Hallo Markus W.,
Markus W. schrieb:
Deine Platte mit dem Gerätenamen sdd benötigt einen Lüfter, die läuft,
bedingt durch die 7200 rpm heißer, war aber sogar mal bei
verschleißträchtigen 56°C.
:
Bearbeitet durch User
Danke mal allen Beteiligten für Ihre konstruktiven Beiträge zu meinem Problem. Inzwischen ist mir auch wohler und ich sehe, dass die Disks soweit noch keine Probleme produzieren. Beim zypper dup bin ich mir auch nicht sicher ob da ein Problem vorligt - Das Tempo des Updates legt es aber nahe. Ich habe mir die laufenden Logs und history vom zypper angesehen als auch seinen cache. Sieht soweit unauffällig aus. Ich mache diese Art von Updates schon seit Jahren mit der Rolling Release von OpenSuse. Beide Updates zuhause sind gestern auch imnu durchgelaufen, obwohl auch über 2T Pakete ersetzt wurden. /var/cache/zypp # >du -sh * 13G packages 4.0K pubkeys 60M raw 51M solv /var/log # >tail -f zypper.log /var/log/zypp # >tail -f history /var/cache/zypp/packages/repo-oss/x86_64 # >ls -ltr | head -10 total 8414192 -rw-r--r-- 1 root root 206364 Feb 23 2020 Mesa-KHR-devel-19.3.3-241.1.x86_64.rpm -rw-r--r-- 1 root root 227640 Feb 23 2020 apache2-example-pages-2.4.41-8.1.x86_64.rpm -rw-r--r-- 1 root root 24536 Feb 23 2020 attica-qt5-5.67.0-1.1.x86_64.rpm -rw-r--r-- 1 root root 1007076 Feb 23 2020 busybox-static-1.31.1-1.1.x86_64.rpm -rw-r--r-- 1 root root 665256 Feb 23 2020 cmake-man-3.16.2-2.1.x86_64.rpm -rw-r--r-- 1 root root 1094760 Feb 23 2020 colord-color-profiles-1.4.4-3.4.x86_64.rpm -rw-r--r-- 1 root root 309720 Feb 23 2020 dhcp-doc-4.3.5-13.1.x86_64.rpm -rw-r--r-- 1 root root 15120 Feb 23 2020 enchant-data-2.2.5-2.2.x86_64.rpm -rw-r--r-- 1 root root 81184 Feb 23 2020 gcr-data-3.34.0-3.1.x86_64.rpm /var/cache/zypp/packages/repo-oss/x86_64 # >ls -ltr | tail -10 -rw-r--r-- 1 root root 1197300 Sep 10 09:32 kate-plugins-21.08.1-1.1.x86_64.rpm -rw-r--r-- 1 root root 94933 Sep 10 09:32 kaccounts-providers-21.08.1-1.1.x86_64.rpm -rw-r--r-- 1 root root 523396 Sep 10 09:32 plasma5-workspace-libs-5.22.5-1.1.x86_64.rpm -rw-r--r-- 1 root root 182778 Sep 10 09:32 kwrite-21.08.1-1.1.x86_64.rpm -rw-r--r-- 1 root root 73765 Sep 10 09:32 libKF5Purpose5-5.85.0-1.1.x86_64.rpm -rw-r--r-- 1 root root 246384 Sep 10 09:32 kde-cli-tools5-5.22.5-1.1.x86_64.rpm -rw-r--r-- 1 root root 35065 Sep 10 09:32 libKF5PurposeWidgets5-5.85.0-1.1.x86_64.rpm -rw-r--r-- 1 root root 233478 Sep 10 09:32 purpose-5.85.0-1.1.x86_64.rpm -rw-r--r-- 1 root root 1928943 Sep 10 09:32 okular-21.08.1-1.1.x86_64.rpm -rw-r--r-- 1 root root 3053224 Sep 10 09:32 q4wine-1.3.12-1.17.x86_64.rpm Nach über drei Stunden bin ich fast am Ende mit dem Update. Die Ursache für die Lange Durchführung ist mir aber immer noch nicht klar. 1013/1031) Installing: kaccounts-providers-21.08.1-1.1.x86_64 ........................................................................ .....................................[done] (1014/1031) Installing: marble-data-21.08.1-1.1.noarch ........................................................................ .............................................[done] (1015/1031) Installing: plasma5-workspace-libs-5.22.5-1.1.x86_64 ........................................................................ ...................................[done] (1016/1031) Installing: kwrite-21.08.1-1.1.x86_64 ........................................................................ ...............................................<100%>[/] Im Prinzip verwende ich drei Kommandos um einen Rolling-Update bei OpenSuse zu machen. zypper ref zypper dup --download-only --allow-vendor-change --auto-agree-with-licenses zypper dup --allow-vendor-change --auto-agree-with-licenses Nach den beiden ersten Kommandos habe ich zu Testzwecken tcpdump -i eth0 an geschmissen um zu sehen ob zypper noch aufs LAN zugreift - war aber nicht der Fall. Langsam habe ich den Verdacht, dass es am rpm liegt, den zypper verwendet. Ein ps -ef | grep zypper und ein ps -ef | grep rpm zeigen relativ lange (mehrere Sekunden) Aktivzeiten in der Processliste an. Das geht bei mir daheim wesentlich fixer. So jetzt muss ich die Kiste durchbooten und hoffe gleich wieder online zu sein - sofern der NV Treiber nicht wieder Probleme macht ;-) LG Markus
Also, ich habe ein kleines Problem mit sdc. 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377251 Der ›Load_Cycle_Count‹ ist komplett runter auf Minimum evtl. sogar darunter. Könnte so eine Energie-Spar-Blue-SaveThePlanet Harddisk sein die ständig mit den Köpfen klappert wie ein Unterkühlter mit den Zähnen. Würde ich zumindest mal recht genau im Auge behalten, das ist nämlich ein Attribut-Wert einer mechanischen Aktivität.
Hallo Norbert, hallo Forum, bin wieder Online ;-) Danke den Admins für das Moven des Beitrags an den richtigen Platz. >Würde ich zumindest mal recht genau im Auge behalten, das ist nämlich >ein Attribut-Wert einer mechanischen Aktivität. Also Scrubbing oder etwas in der Art habe ich nicht aktiviert. Zudem verwende ich keine Indexierung auf Partitionen. Warum die Disk dann "klappern sollte" kann ich nicht sagen. Hast Du eine Idee, wie man das testen und eventuell abstellen kann. Siehst Du was ungewöhnliches am systemctl output was Deine Annahme bestätigen würde? Markus PS.: Für Norbert: smartctl -a /dev/sdc | grep Load_Cycle_Count 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377277 >while true; do smartctl -a /dev/sdc | grep Load_Cycle_Count; sleep 60; done 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377278 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377279 Der Wert steigt kontinuierlich :-( Soll ich eine neue Disk einbauen - jetzt schon. Besser zu früh als zu spät!
:
Bearbeitet durch User
Nein, nein. Was ich meinte war einfach: Wenn das so eine Platte mit extrem schnellem Kopf- Load/Park Zyklus ist -- und so sieht der Zähler mit über einer drittel Million Zyklen aus -- dann ist laut SMART (Hersteller) das Maximum der spezifizierten Load/Park Zyklen erreicht. Läuft weiter, aber nun außerhalb dessen was Seagate spezifiziert hat. Jeder Zyklus eine mechanische Bewegung, ein Klick/Klack - Das Zähneklappern war vielleicht etwas zu salopp formuliert. ;-) > Siehst Du was ungewöhnliches am systemctl output > was Deine Annahme bestätigen würde? 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377251 Der erste 001 Wert begann mal bei 100 (in Prozent) und ist nun auf 1 (%) herunter. Ich kann nicht sagen ob das der Endwert ist oder ob's noch auf 0 geht.
Markus W. schrieb: > PS.: Für Norbert: > while true; do smartctl -a /dev/sdc | grep Load_Cycle_Count; sleep 60; done > 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always > - 377278 > 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always > - 377279 > > Der Wert steigt kontinuierlich :-( Soll ich eine neue Disk einbauen - > jetzt schon. Besser zu früh als zu spät! Neue Disk? Wer kann das schon sagen… Ich würde es aufmerksam beobachten. Und zumindest versuchen das Timeout für den Head-Retract sehr deutlich hoch zu setzen. ›hdparm‹ eventuell, muss man aber mit den Hersteller-Informationen abgleichen
Nach dem Vorschlag von (prx) A. K. habe ich mir den Link durchgelesen und das Tool mal compiliert. Leider war das deaktivieren des Timers nicht erfolgreich, s.u. >smartctl -a /dev/sdd smartctl 7.2 2021-06-06 r5225 [x86_64-linux-5.14.0-1-default] (SUSE RPM) Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Western Digital Gold Device Model: WDC WD4002FYYZ-01B7CB1 >./idle3ctl -g /dev/sdd sg16(VSC_ENABLE) failed: Invalid exchange >./idle3ctl -d /dev/sdd sg16(VSC_ENABLE) failed: Invalid exchange >while true; do smartctl -a /dev/sdc | grep Load_Cycle_Count; sleep 60; done 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377278 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377279 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377280 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377281 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377282 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377283 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377284 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377285 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377286 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377287 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377288 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377289 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377290 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377291 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 377292 Markus
(prx) A. K. hat ja schon einen Link gepostet, wo beschrieben ist, wie man das Parken konfigurieren kann. Wenn ich das richtig sehe, funktioniert idle3ctl (idle3-tools) wohl nur verlässlich mit WD HDDs. Die dritte Platte ist aber eine Seagate. Kann funktionieren, muss aber nicht. Immerhin gibt es die Option "-f(orce)". Markus W. schrieb: > Der Wert steigt kontinuierlich :-( Die Platte scheint wohl bei jeder kleinen Pause den/die Köpfe zu parken. > Soll ich eine neue Disk einbauen - Verkehrt ist es nicht. HDDs kosten ja nicht mehr die Welt.
:
Bearbeitet durch Moderator
Auch die unterschiedlichen Versionen habe keinen Ausleseerfolg gebracht! /dev/shm/idle3-tools-0.9.1 # >./idle3ctl -g100 /dev/sdd sg16(VSC_ENABLE) failed: Invalid exchange /dev/shm/idle3-tools-0.9.1 # >./idle3ctl -g103 /dev/sdd sg16(VSC_ENABLE) failed: Invalid exchange /dev/shm/idle3-tools-0.9.1 # >./idle3ctl -g105 /dev/sdd sg16(VSC_ENABLE) failed: Invalid exchange /dev/shm/idle3-tools-0.9.1 # Markus
Markus W. schrieb: > ./idle3ctl -g100 /dev/sdd Die dritte Platte, die das Load_Cycle_Count Problem hat, ist /dev/sdc und nicht /dev/sdd. Warum willst Du Parameter für/dev/sdd ändern und erwartest dann, dass sich diese auf /dev/sdc auswirken? Wenn ich es richtig verstanden habe, funktioniert das Tool sowieso nur für WD-Platten. /dev/sdc ist aber eine Seagate.
:
Bearbeitet durch Moderator
Klappt übrigens bei der Seagate-Disk sdc auch nicht mit dem Tool den counter auszulesen. /dev/shm/idle3-tools-0.9.1 # >./idle3ctl --force -g100 /dev/sdc sg16(VSC_ENABLE) failed: Invalid exchange /dev/shm/idle3-tools-0.9.1 # >./idle3ctl --force -g103 /dev/sdc sg16(VSC_ENABLE) failed: Invalid exchange /dev/shm/idle3-tools-0.9.1 # >./idle3ctl --force -g105 /dev/sdc sg16(VSC_ENABLE) failed: Invalid exchange /dev/shm/idle3-tools-0.9.1 # Markus
Norbert hat recht. Die ST4000DM000 scheint für 300k load/unload cycles spezifiziert zu sein. Datasheet: https://www.seagate.com/www-content/datasheets/pdfs/desktop-hdd-8tbDS1770-9-1603UK-en_GB.pdf Da die restlichen SMART-Parameter OK sind, ist hier kein akuter Schaden zu sehen. Aber aus Sicht des Herstellers ist hat die Mechanik die projizierte Lebenserwartung überschritten. Je nachdem wieviel die auf der Platte gespeicherten Daten wert sind, könnte man über prophylaktischen Austausch nachdenken... Temporär läßt sich der Idle-Timer bei vielen Platten mit
1 | hdparm -B 254 |
und/oder
1 | hdparm -M 254 |
entsprechend hochsetzen. Die Einstellung geht aber nach jedem PowerCycle verloren. idle3ctl ist nur für WD-spezifisch. Ich würde nicht erwarten, daß es auch bei Seagate funktioniert.
Deswegen habe ich ja erst bei der WD Disk das Tool angewendet. Aber mit dem --force Parameter klappt das Auslesen auch bei der Segate-Disk nicht. War ja nur ein Versuch. ICh kann jetzt aber gezielt nach dem Problem im Web suche. Also nochmals danke für den Hinweis. Nun wird aber die Kiste runter gefahren und dann geht es ins WE. Markus
Ich weiß, es ist vermutlich eine überflüssige Frage, aber wurden die Befehle mit root-Rechten ausgeführt?
Tom schrieb: > Ich weiß, es ist vermutlich eine überflüssige Frage, aber wurden > die > Befehle mit root-Rechten ausgeführt? Raute im Prompt, wahrscheinlich ja.
Norbert ist mir mit der Antwort zuvor gekommen.
>/dev/shm/idle3-tools-0.9.1 #
# als default shell prompt => root user.
Jetzt ist aber die Kiste bis Do. offline,
danach werde ich weiter suchen und hoffentlich
auch was finden.
Danke nochmals für die schnelle und kompetente
Hilfe.
Markus
Schade, habe den Link erst jetzt entdeckt: https://sourceforge.net/p/idle3-tools/bugs/2/ beim Suchen nach "sg16(VSC_ENABLE)" in der Suchmaschiene meines Vertrauens. eine -v Option wäre beim Ausführen des idle3ctl Kommandos aussagekräftiger gewesen. Habe es leider übersehen. Markus
Eventuell ist diese Aussage auch hilfreich! Habe leider den angegebenen Link nicht bis ganz unten gelesen, sondern mich gleich auf die Kommandos und das Compilieren gestürzt. >Intellipark on newer WD drives cannot be switched off even with original >WDIDLE3 utility. >As a workaround you can add to hourly cron this command >smartctl -t offline /dev/sdX >it prevents parks. Performance degradation is unnoticeable for me. Markus
:
Bearbeitet durch User
Ja, der offline test wuselt im Hintergrund ein wenig auf der Platte herum wenn gerade nichts wichtiges (Arbeit) anliegt. Also bleiben die Köpfe schön geladen. Du solltest aber das Ding einmal so laufen lassen um abzuschätzen wie lange ein Durchlauf braucht. Das wäre dann ungefähr das Intervall im cron.
Hallo Norbert, ich habe mal spaßhalber, da durch die Beiträge neugierig geworden, mir meine Disks via smartctl auf meinem NB daheim angesehen. sda zählt etwas langsamer hoch sdb etwas schneller. Beide Disks sind von Seagate. === START OF INFORMATION SECTION === Model Family: Seagate Barracuda 2.5 5400 Device Model: ST2000LM015-2E8174 root@linux:~ >while true > do > smartctl -a /dev/sda | grep Load_Cycle_Count | awk '{printf("sda: %s\n",$0)}' > smartctl -a /dev/sdb | grep Load_Cycle_Count | awk '{printf("sdb: %s\n",$0)}' > sleep 120 > done sda: 193 Load_Cycle_Count 0x0032 050 050 000 Old_age Always - 100829 sdb: 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 535385 sda: 193 Load_Cycle_Count 0x0032 050 050 000 Old_age Always - 100829 sdb: 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 535385 sda: 193 Load_Cycle_Count 0x0032 050 050 000 Old_age Always - 100829 sdb: 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 535386 sda: 193 Load_Cycle_Count 0x0032 050 050 000 Old_age Always - 100829 sdb: 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 535388 sda: 193 Load_Cycle_Count 0x0032 050 050 000 Old_age Always - 100829 sdb: 193 Load_Cycle_Count 0x0032 001 001 000 Old_age Always - 535390 Markus
Scheint im Hintergrund zu laufen.
root@linux:~
>time smartctl -t offline /dev/sdb
smartctl 7.2 2021-06-06 r5225 [x86_64-linux-5.14.0-1-default] (SUSE RPM)
Copyright (C) 2002-20, Bruce Allen, Christian Franke,
www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART off-line routine immediately in off-line
mode".
Drive command "Execute SMART off-line routine immediately in off-line
mode" successful.
Testing has begun.
real 0m0.224s
user 0m0.028s
sys 0m0.001s
Kommt das Kommando nit einer Meldung von alleine zurück?
Markus
Hmm.. Der offline-Test kann (auch aus dem Hintergrund heraus) sich negativ auf die Festplattenperformance auswirken. Statt da einen stündlichen cron-Job zu starten, daher nochmal der Hinweis auf "hdparm -B 254 /dev/<device>". Das braucht keine cron-Job und gilt bis zum PowerOff/Standby.
Hallo Tom, nur um zu verstehen was Du da vorschlägst habe ich mir die hdparm Dok. durchgelesen. Danke für Deinen Hinweis. Markus hdparm -h ... -B Set Advanced Power Management setting (1-255) wie sieht es damit aus: -S Set standby (spindown) timeout -J Get/set Western DIgital "Idle3" timeout for a WDC "Green" drive (DANGEROUS) Aus Manpage zu hdparm -B Get/set Advanced Power Management feature, if the drive supports it. A low value means aggressive power management and a high value means better performance. Possible settings range from values 1 through 127 (which permit spin-down), and values 128 through 254 (which do not permit spin-down). The highest degree of power management is attained with a setting of 1, and the highest I/O performance with a setting of 254. A value of 255 tells hdparm to disable Advanced Power Management altogether on the drive (not all drives support disabling it, but most do). -J Get/set the Western Digital (WD) Green Drive's "idle3" timeout value. This timeout controls how often the drive parks its heads and enters a low power consumption state. The factory default is eight (8) seconds, which is a very poor choice for use with Linux. Leaving it at the default will result in hundreds of thousands of head load/unload cycles in a very short period of time. The drive mechanism is only rated for 300,000 to 1,000,000 cycles, so leaving it at the default could result in premature failure, not to mention the performance impact of the drive often having to wake-up before doing routine I/O. WD supply a WDIDLE3.EXE DOS utility for tweaking this setting, and you should use that program instead of hdparm if at all possible. The reverse-engineered implementation in hdparm is not as complete as the original official program, even though it does seem to work on at a least a few drives. A full power cycle is required for any change in setting to take effect, regardless of which program is used to tweak things. A setting of 30 seconds is recommended for Linux use. Permitted values are from 8 to 12 seconds, and from 30 to 300 seconds in 30-second increments. Specify a value of zero (0) to disable the WD idle3 timer completely (NOT RECOMMENDED!). -S Put the drive into idle (low-power) mode, and also set the standby (spindown) timeout for the drive. This timeout value is used by the drive to determine how long to wait (with no disk activity) before turning off the spindle motor to save power. Under such circumstances, the drive may take as long as 30 seconds to respond to a subsequent disk access, though most drives are much quicker. The encoding of the timeout value is somewhat peculiar. A value of zero means "timeouts are disabled": the device will not automatically enter standby mode. Values from 1 to 240 specify multiples of 5 seconds, yielding timeouts from 5 seconds to 20 minutes. Values from 241 to 251 specify from 1 to 11 units of 30 minutes, yielding timeouts from 30 minutes to 5.5 hours. A value of 252 signifies a timeout of 21 minutes. A value of 253 sets a vendor-defined timeout period between 8 and 12 hours, and the value 254 is reserved. 255 is interpreted as 21 minutes plus 15 seconds. Note that some older drives may have very different interpretations of these values.
:
Bearbeitet durch User
Also, ich würde dem Gesamtsystem nicht trauen. Die Platten haben schlechte Seek_Error_Rate. Sind die mechanisch schlecht montiert? Vibrieren die Platten oder gar der PC? Vielleicht hast Du auch Resonanzen etc. Dabei sind die ersten beiden Platten ja gerade mal zwei Monate in Betrieb. Da stimmt doch was nicht. Meiner Meinung könnte das eine Ursache für die langsamen Zugriffe sein. Auch Raw_Read_Error_Rate ist doch viel zu hoch für solche, neuen Platten. Und Dein Temperatur-Problem wurde weiter oben schon angesprochen, so wie Load_Cycle_Count. So sieht z.B. eine meiner ältesten Platten aus:
1 | === START OF INFORMATION SECTION === |
2 | Model Family: Western Digital Green |
3 | Device Model: WDC WD20EARX-00PASB0 |
4 | Serial Number: WD-WCAZAC491275 |
5 | LU WWN Device Id: 5 0014ee 25bbfe755 |
6 | Firmware Version: 51.0AB51 |
7 | User Capacity: 2.000.398.934.016 bytes [2,00 TB] |
8 | Sector Sizes: 512 bytes logical, 4096 bytes physical |
9 | |
10 | ... |
11 | |
12 | ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE |
13 | 1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0 |
14 | 3 Spin_Up_Time 0x0027 202 171 021 Pre-fail Always - 4858 |
15 | 4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 319 |
16 | 5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0 |
17 | 7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0 |
18 | 9 Power_On_Hours 0x0032 001 001 000 Old_age Always - 74708 |
19 | 10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0 |
20 | 11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0 |
21 | 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 316 |
22 | 192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 52 |
23 | 193 Load_Cycle_Count 0x0032 181 181 000 Old_age Always - 59459 |
24 | 194 Temperature_Celsius 0x0022 119 108 000 Old_age Always - 31 |
25 | 196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0 |
26 | 197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0 |
27 | 198 Offline_Uncorrectable 0x0030 200 200 000 Old_age Offline - 0 |
28 | 199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0 |
29 | 200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0 |
Markus W. schrieb: >>while true >> do >> smartctl -a /dev/sda | grep Load_Cycle_Count | awk '{printf("sda: %s\n",$0)}' >> smartctl -a /dev/sdb | grep Load_Cycle_Count | awk '{printf("sdb: %s\n",$0)}' >> sleep 120 >> done smartd? (auch über lange Zeiträume wenn Journale aufgehoben werden) journalctl -u smartd -> SMART Usage Attribute: n changed from x to y bspw.: root@slax:$journalctl -r -u smartd -- Logs begin at Thu 2016-11-03 18:16:50 CET, end at Fri 2021-09-10 18:39:03 CEST. -- Sep 10 16:15:30 slax smartd[851]: Device: /dev/sdc [SAT], SMART Usage Attribute: 194 Temperature_Celsius changed from 42 to 43 Sep 10 16:15:30 slax smartd[851]: Device: /dev/sdc [SAT], SMART Usage Attribute: 190 Airflow_Temperature_Cel changed from 58 to 57 Sep 10 15:15:30 slax smartd[851]: Device: /dev/sda [SAT], SMART Prefailure Attribute: 8 Seek_Time_Performance changed from 252 to 251 usw. usw. Es interessiert ja nur wenn sich wirklich etwas geändert hat, das kannst du nat. auch durch grep jagen u. nach Platten sortieren (Load_Cycle_Count kennen meine garnicht) > sda: 193 Load_Cycle_Count 0x0032 050 050 000 Old_age > Always - 100829 > sdb: 193 Load_Cycle_Count 0x0032 001 001 000 Old_age > Always - 535385 > sda: 193 Load_Cycle_Count 0x0032 050 050 000 Old_age > Always - 100829 > sdb: 193 Load_Cycle_Count 0x0032 001 001 000 Old_age > Always - 535385 > sda: 193 Load_Cycle_Count 0x0032 050 050 000 Old_age > Always - 100829 > sdb: 193 Load_Cycle_Count 0x0032 001 001 000 Old_age ....
Hallo Markus, -S bestimmt den Zeitpunkt, wann der Spindelmotor im Standby ausgeschaltet wird. Das hat leider keinen Einfluß auf die load/unload-Timer. -J dürfte das gleiche tun (oder nicht tun), was das idle3ctl - Tool versucht hat. -B beeinflußt das Powermanagement von der Platte, und das ist ja leider eine Black-Box weil herstellerspezifisch. :-( Man kann ja -B ohne eine Zahl übergeben, dann sollte man sehen können, was der Hersteller oder das OS da als default-Wert vorgibt. Das load/unload-Problem besteht ja bei Linux (und MacOS) schon seit Jahrzehnten. (Ich habe das anno 2004 in meinem damaligen PowerBook gehabt). Man muß ein wenig mit dem Parameter spielen. Ich erinnere mich dunkel, daß manche Platten schon bei Werten größer 128 Ruhe gegeben haben, andere erst über 192. Ich habe 254 vorgeschlagen, weil 255 nicht immer funktioniert. Wenn Du in Deinen Smart-Logs die Werte von "9 Power_On_Hours" und "240 Head_Flying_Hours" vergleichst, dann sieht man, daß beide Werte ziemlich nach beiandander sind, was zumindest die betroffene Platte (sdc) bedeutet, daß sie nur selten im Spin-Down war. Von daher würde ich mir um den Spin-Down keine großen Gedanken machen. Nachteile sollte man davon keine haben, denn eigentlich jede Platte aus diesem Jahrhundert sollte einen freien Fall oder ungewöhnliche Beschleunigung des Gehäuses bemerken und die Köpfe automatisch unloaden (Smart-Parameter: "191 G-Sense_Error_Rate"). Gleiches gilt beim Herunterfahren des Rechners oder Standby (=kontrollierter Spindown) oder beim plötzlichen Abschalten ohne, daß das OS den Befehl "Spin-Down" gibt (Smart-Parameter: "192 Power-Off_Retract_Count").
Hallo, danke Euch für den Input.
Vieles davon war mir so gar nicht im Detail bekannt.
Um die angedeutete schlechte Montage zu entkräften
nun mehr Infos (Resonanzen könnten aber durchaus in Frage kommen).
Bei dem besagten Rechner handelt es sich um einen DELL-T5800 Tower.
Steht am Boden neben dem Schreibtisch.
Die vier Disks sind auf Gummipuffern ala DELL in Wechsel-Rahmen
montiert und sollten keine übermäßigen Vibrationen von Tower-Gehäuse
abbekommen.
Die später gezeigten Disks sind aus meinem HP-zBook17 G3 und waren
nur als Vergleich herangezogen worden ohne selber zum Problemkreis
zu gehören.
Die vier Disks im T5800 sind aus zwei unterschiedlichen Zeiten.
Ich wechsle die Disks alle zwei bis drei Jahre und setze auch das
Linux komplett neu auf. Die alten Disks bleiben dabei im System
für Backups und als Archiv alter Daten.
Diese Vorgehensweise habe ich die letzten zwei Jahrzehnte praktiziert
und auch bis dato keinen Datenverlust durch defekte Disks erfahren.
Sicherungen mache ich schon seit Jahren mit dem GO Programm restic
>/usr/bin/restic version
restic 0.12.1 compiled with go1.16.6 on linux/amd64
Soweit die Infos zu dem verwendeten System.
Markus
idle3 verlangt nach dem ändern einen kompletten powercycle. Ausserdem ist die Änderung wirkungslos wenn die platte gerade im spindown ist.
Noch was zu S.M.A.R.T.: Habe gerade ne Platte hier die am sterben ist aber smart health status ist ok, obwohl die massenhaft fehlerhafte Sketoren hat, der selfcheck beim ersten defekt sektor abbricht und das log bald überläuft vor lesefehlern, ...
Moin, Voodoopriester schrieb: > Noch was zu S.M.A.R.T.: blafasel Ja und? Auch wenn du dich im Auto anschnallst, kannst du trotzdem z.b. an einem Herzkasper waehrend der Fahrt sterben. SCNR, WK
Voodoopriester schrieb: > Noch was zu S.M.A.R.T.: > > Habe gerade ne Platte hier die am sterben ist aber smart health status > ist ok, obwohl die massenhaft fehlerhafte Sketoren hat, der selfcheck > beim ersten defekt sektor abbricht und das log bald überläuft vor > lesefehlern, ... guck was es bedeuten soll: manpage failing health status this means either that the device has already failed, or that it is predicting its own failure within the next 24 hours. Geht doch noch ;) --- Weshalb sollte das abbrechen? Verkabelung, Hostcontroller, Stromversorgung, Firmware... wären z.B. Dinge die ein Selbsttest ja garnicht erfaßt trotzdem ziemlicher Murks :/
Hallo Voodoopriester, Voodoopriester schrieb: > Noch was zu S.M.A.R.T.: > > Habe gerade ne Platte hier die am sterben ist aber smart health status > ist ok, der "smart health status" ist vermutlich als Vereinfachung für technikferne Menschen gedacht und wenig aussagekräftig. > obwohl die massenhaft fehlerhafte Sketoren hat, der selfcheck > beim ersten defekt sektor abbricht und das log bald überläuft vor > lesefehlern, ... Man guckt sich die einzelnen SMART-Parameter an. Hat die Festplatte fehlerhafte Sektoren, spiegelt sich dieser Defekt auch in den SMART-Parametern wieder. Festplatten mit fehlerhaften Sektoren sind in meiner Wahrnehmung nicht mehr "OK" auch wenn irgendeine Clickibunti-Software das behauptet. Sinnvoll ist es, mit den Smartmontools eine Log-Datei zu erzeugen. Da findet sich sich dann auch alles Wesentliche drin wieder, also z.B. mit smartctl -a /dev/sdX > C:voodolog.txt Man ersetzt X durch den passendenlaufwerksbuchstaben und leitet die Ausgabe der Smartmontools in die Datei voodolog.txt auf der Wurzelebene des C-Laufwerks in einem Windowssystem um.
:
Bearbeitet durch User
Bitte melde dich an um einen Beitrag zu schreiben. Anmeldung ist kostenlos und dauert nur eine Minute.
Bestehender Account
Schon ein Account bei Google/GoogleMail? Keine Anmeldung erforderlich!
Mit Google-Account einloggen
Mit Google-Account einloggen
Noch kein Account? Hier anmelden.